论文:https://arxiv.org/pdf/1908.03826.pdf
代码:https://github.com/TAMU-VITA/DeblurGANv2
abstract
我们提出了一个名为DeblurGAN-v2的端到端的生成对抗网络,它对于去模糊产生了非常好的性能。DeblurGAN-v2基于conditional GAN(带有两个判别器)。我们将特征金字塔网络结构作为DeblurGAN-v2生成器的核心构建块。 它可以灵活地与各种backbone配合使用,在性能和效率之间取得平衡。如果使用复杂的backbone(如Inception-ResNet-v2)可以得到非常好的去模糊效果。同时,若使用轻量的backbone(e.g., MobileNet and its variants) ,DeblurGAN-v2比最接近的竞争对手快10到100倍,同时保持接近最先进的结果,这意味着可以选择实时视频去模糊。
Introduction
本文以DeblurGAN的成功为基础,旨在再次大力推动基于GAN的运动去模糊。 我们引入了一个新的框架DeblurGAN-v2来改进DeblurGAN,并且在质量效率范围内实现高度灵活性。 我们的创新总结如下:
Framework Level : 我们构建了一个用于去模糊的新条件GAN框架。 对于生成器,我们将特征金字塔网络(FPN)(最初用于目标检测)引入到图像恢复任务中。 对于鉴别器,我们采用 relativistic discriminator ,并且使用最小均方损失在两个尺度上分别进行评估。
Backbone Level : 在生成器部分选择不同的 backbone 会有不同的去模糊效果。如果想得到最好的去模糊效果,我们使用复杂的 backbone : Inception-ResNet-v2 。 如果想得到更高的效率 ,我们使用清量的backbone : MobileNet, 并进一步创建他的变形:具有深度可分离卷积的 MobileNet-DSC。很明显后面两个具有更快的速度。
Experiment Level : 我们在三个流行的基准测试中展示了非常广泛的实验,以展示DeblurGANv2实现的最先进(或接近)性能(PSNR,SSIM和感知质量)。 在效率方面,DeblurGAN-v2与MobileNet-DSC的速度比DeblurGAN快21倍[21],比[33,45]快100多倍,模型尺寸仅为4 MB,这意味着可能实现 时间视频去模糊。 我们还对真实模糊图像的去模糊质量进行了主观研究。 最后,我们展示了我们的模型在一般图像恢复中的潜力,因为它具有额外的灵活性。
DeblurGAN-v2 Architecture
DeblurGAN-v2 结构如下图所示,通过对生成器的训练,可以从一张模糊图像中恢复清晰图像。

Feature Pyramid Deblurring
FPN框架最初用于目标检测。它生成多个特征映射层,这些特征映射层编码不同的语义并包含更好的质量信息。 FPN包括自下而上和自上而下的路径。 自下而上的路径是用于特征提取的卷积网络,在从下往上的过程中空间分辨率被下采样。但是可以提取和压缩更多的语义特征信息。另一方面,通过自上往下的路径, FPN可以重建特征信息。自下而上和自上而下通道之间的横向连接补充了高分辨率细节并有助于定位物体。
我们的架构由一个FPN骨干网组成,我们从中获取五个不同尺度的最终特征图作为输出。这些特征稍后被上采样到输入大小的1/4并连接成一个张量,其包含不同级别的语义信息。我们在网络的最后添加一个上采样层和一个卷积层来恢复清晰图像和去伪影。我们引入了从输入到输出的跳跃连接,以便学习重点关注残差。
对应代码分析:
def forward(self, x):
### 提取特征层
map0, map1, map2, map3, map4 = self.fpn(x)
###对不同的特征上采样
map4 = nn.functional.upsample(self.head4(map4), scale_factor=8, mode="nearest")
map3 = nn.functional.upsample(self.head3(map3), scale_factor=4, mode="nearest")
map2 = nn.functional.upsample(self.head2(map2), scale_factor=2, mode="nearest")
map1 = nn.functional.upsample(self.head1(map1), scale_factor=1, mode="nearest")
并接map1- map4
smoothed = self.smooth(torch.cat([map4, map3, map2, map1], dim=1))
smoothed = nn.functional.upsample(smoothed, scale_factor=2, mode="nearest")
smoothed = self.smooth2(smoothed + map0)
smoothed = nn.functional.upsample(smoothed, scale_factor=2, mode="nearest")
final = self.final(smoothed)
得到输出结果
res = torch.tanh(final) + x
return torch.clamp(res, min = -1,max = 1)
首先提取图片不同尺度的的特征映射:

map0, map1, map2, map3, map4 = self.fpn(x)
其中self.fpn(x)对应函数如下:
def forward(self, x):
# Bottom-up pathway, from ResNet
enc0 = self.enc0(x)
enc1 = self.enc1(enc0) # 256
enc2 = self.enc2(enc1) # 512
enc3 = self.enc3(enc2) # 1024
enc4 = self.enc4(enc3) # 2048
# Lateral connections
lateral4 = self.pad(self.lateral4(enc4))
lateral3 = self.pad(self.lateral3(enc3))
lateral2 = self.lateral2(enc2)
lateral1 = self.pad(self.lateral1(enc1))
lateral0 = self.lateral0(enc0)
# Top-down pathway
pad = (1, 2, 1, 2) # pad last dim by 1 on each side
pad1 = (0, 1, 0, 1)
map4 = lateral4
map3 = self.td1(lateral3 + nn.functional.upsample(map4, scale_factor=2, mode="nearest"))
map2 = self.td2(F.pad(lateral2, pad, "reflect") + nn.functional.upsample(map3, scale_factor=2, mode="nearest"))
map1 = self.td3(lateral1 + nn.functional.upsample(map2, scale_factor=2, mode="nearest"))
return F.pad(lateral0, pad1, "reflect"), map1, map2, map3, map4
其中 self.enc0 ------ self.enc4 为首先对特征进行卷积,然后进行池化,然后的到不同的特征,如图:
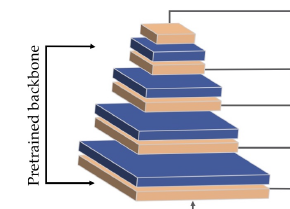
self.enc0 = self.inception.conv2d_1a
self.enc1 = nn.Sequential(
self.inception.conv2d_2a,
self.inception.conv2d_2b,
self.inception.maxpool_3a,
) # 64
self.enc2 = nn.Sequential(
self.inception.conv2d_3b,
self.inception.conv2d_4a,
self.inception.maxpool_5a,
) # 192
self.enc3 = nn.Sequential(
self.inception.mixed_5b,
self.inception.repeat,
self.inception.mixed_6a,
) # 1088
self.enc4 = nn.Sequential(
self.inception.repeat_1,
self.inception.mixed_7a,
)
FPN网络原理:
我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测, FPN不一样的地方在于预测是在不同特征层独立进行的。 如上面介绍的那样, FPN结构经过不同次数的卷积等处理就可以得到不同的特征层信息。
FPN结构对比:
- a、 图像金字塔,即将图像做成不同的scale,然后不同scale的图像生成对应的不同scale的特征。这种方法的缺点在于增加了时间成本。有些算法会在测试时候采用图像金字塔。
- b、 像SPP net,Fast RCNN,Faster RCNN是采用这种方式,即仅采用网络最后一层的特征。
- c、 像SSD(Single Shot Detector)采用这种多尺度特征融合的方式,没有上采样过程,即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的
- d、FPN结构 顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的。
如下图所示:

上图(a)中的方法即为常规的生成一张图片的多维度特征组合的经典方法。即对某一输入图片我们通过压缩或放大从而形成不同维度的图片作为模型输入,使用同一模型对这些不同维度的图片分别处理后,最终再将这些分别得到的特征(feature maps)组合起来就得到了我们想要的可反映多维度信息的特征集。此种方法缺点在于需要对同一图片在更改维度后输入处理多次,因此对计算机的算力及内存大小都有较高要求。
图(b)中的方法则只拿单一维度的图片做为输入,然后经CNN模型处理后,拿最终一层的feature maps作为最终的特征集。显然此种方法只能得到单一维度的信息。优点是计算简单,对计算机算力及内存大小都无过高需求。此方法为大多数R-CNN系列目标检测方法所用像R-CNN/Fast-RCNN/Faster-RCNN等。因此最终这些模型对小维度的目标检测性能不是很好。
图©中的方法同样是拿单一维度的图片做为输入,不过最终选取用于接下来分类或检测任务时的特征组合时,此方法不只选用了最后一层的high level feature maps,同样也会选用稍靠下的反映图片low level 信息的feature maps。然后将这些不同层次(反映不同level的图片信息)的特征简单合并起来(一般为concat处理),用于最终的特征组合输出。此方法可见于SSD当中。不过SSD在选取层特征时都选用了较高层次的网络。比如在它以VGG16作为主干网络的检测模型里面所选用的最低的Convolution的层为Conv4,这样一些具有更低级别信息的层特征像Conv2/Conv3就被它给漏掉了,于是它对更小维度的目标检测效果就不大好。
图(d)中的方法同图©中的方法有些类似,也是拿单一维度的图片作为输入,然后它会选取所有层的特征来处理然后再联合起来做为最终的特征输出组合。(作者在论文中拿Resnet为实例时并没选用Conv1层,那是为了算力及内存上的考虑,毕竟Conv1层的size还是比较大的,所包含的特征跟直接的图片像素信息也过于接近)。另外还对这些反映不同级别图片信息的各层自上向下进行了再处理以能更好地组合从而形成较好的特征表达(详细过程会在下面章节中进一步介绍)。而此方法正是我们本文中要讲的FPN CNN特征提取方法。
FPN结构原理:
作者的算法大致结构如下图: 一个自底向上的线路,一个自顶向下的线路,横向连接(lateral connection)。图中放大的区域就是横向连接,这里1*1的卷积核的主要作用是减少卷积核的个数,也就是减少了feature map的个数,并不改变feature map的尺寸大小。

自底向上其实就是网络的前向过程。在前向过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。
自顶向下的过程采用上采样(upsampling)进行,而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合(merge)。在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应(aliasing effect)。并假设生成的feature map结果是P2,P3,P4,P5,和原来自底向上的卷积结果C2,C3,C4,C5一一对应。
