1.实现思路
实现方式:范围分片,就是我们自己根据某个字段的数值范围来确定这些数据到底存放在哪一个分片上,不过需要我们提前规划好分片字段某个范围属于哪个分片。切分规则根据文件(autopartition-long.txt)配置的范围来进行切片,根据配置的分片字段取值范围,然后把这一范围的所有数据都插入到该分片。
举个例子:比如将id在0-500W的数据分片在第一个节点上面,将id在500W-1000W的数据分片在第二个节点上,依次类推下去。
优点:适用于想明确知道某个分片字段的某个范围具体在哪一个节点;
缺点:如果短时间内有大量的批量插入操作,那么某个分片节点可能一下子会承受比较大的数据库压力,而别的分片节点此时可能处于闲置状态,无法利用其它节点进行分担压力(热点数据问题);
下面通过一个简单的示例,说明在MyCat中如何实现范围分片。
2.范围分片
【a】创建数据库和表
create database range1;
use range1;
create table user(id bigint not null primary key,name varchar(20));
create database range2;
use range2;
create table user(id bigint not null primary key,name varchar(20));
【b】配置server.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="nonePasswordLogin">0</property> <!-- 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户-->
<property name="useHandshakeV10">1</property>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 -->
<property name="sequnceHandlerType">2</property>
<!--<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>-->
<!--必须带有MYCATSEQ_或者 mycatseq_进入序列匹配流程 注意MYCATSEQ_有空格的情况-->
<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>
<property name="subqueryRelationshipCheck">false</property> <!-- 子查询中存在关联查询的情况下,检查关联字段中是否有分片字段 .默认 false -->
<!-- <property name="useCompression">1</property>--> <!--1为开启mysql压缩协议-->
<!-- <property name="fakeMySQLVersion">5.6.20</property>--> <!--设置模拟的MySQL版本号-->
<!-- <property name="processorBufferChunk">40960</property> -->
<!--
<property name="processors">1</property>
<property name="processorExecutor">32</property>
-->
<!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena | type 2 NettyBufferPool -->
<property name="processorBufferPoolType">0</property>
<!--默认是65535 64K 用于sql解析时最大文本长度 -->
<!--<property name="maxStringLiteralLength">65535</property>-->
<!--<property name="sequnceHandlerType">0</property>-->
<!--<property name="backSocketNoDelay">1</property>-->
<!--<property name="frontSocketNoDelay">1</property>-->
<!--<property name="processorExecutor">16</property>-->
<!--
<property name="serverPort">8066</property> <property name="managerPort">9066</property>
<property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property>
<property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> -->
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property>
<!--
off heap for merge/order/group/limit 1开启 0关闭
-->
<property name="useOffHeapForMerge">0</property>
<!--
单位为m
-->
<property name="memoryPageSize">64k</property>
<!--
单位为k
-->
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<!--
单位为m
-->
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">false</property>
<!-- XA Recovery Log日志路径 -->
<!--<property name="XARecoveryLogBaseDir">./</property>-->
<!-- XA Recovery Log日志名称 -->
<!--<property name="XARecoveryLogBaseName">tmlog</property>-->
<!--如果为 true的话 严格遵守隔离级别,不会在仅仅只有select语句的时候在事务中切换连接-->
<property name="strictTxIsolation">false</property>
<property name="useZKSwitch">true</property>
</system>
<!-- 全局SQL防火墙设置 -->
<!--白名单可以使用通配符%或着*-->
<!--例如<host host="127.0.0.*" user="root"/>-->
<!--例如<host host="127.0.*" user="root"/>-->
<!--例如<host host="127.*" user="root"/>-->
<!--例如<host host="1*7.*" user="root"/>-->
<!--这些配置情况下对于127.0.0.1都能以root账户登录-->
<!--
<firewall>
<whitehost>
<host host="1*7.0.0.*" user="root"/>
</whitehost>
<blacklist check="false">
</blacklist>
</firewall>
-->
<user name="root">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
【c】配置schema.xml分片表、分片节点等
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="1000">
<table name="user" dataNode="dn1,dn2" primaryKey="id" rule="auto-sharding-long" />
</schema>
<dataNode name="dn1" dataHost="dataHost01" database="range1" />
<dataNode name="dn2" dataHost="dataHost01" database="range2" />
<dataHost name="dataHost01" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.70.128:3306" user="root" password="123" />
</dataHost>
</mycat:schema>
【d】配置rule.xml自定义范围分片
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
<property name="defaultNode">0</property>
</function>
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
【e】配置autopartition-long.txt文件,说明分片字段分片范围
vim autopartition-long.txt
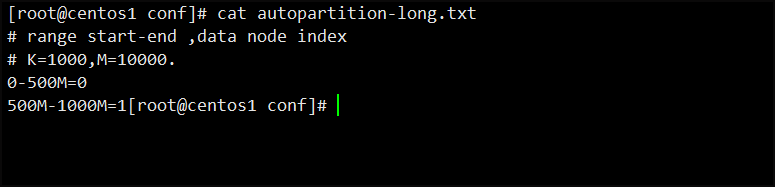
注意:这里配置了dn1,dn2两个分片节点,所以这里也配置两个节点对应的分片字段范围,如果配置多了可能会报错。
【f】测试插入数据
insert into user(id,name) values(111,'zhangsan');
insert into user(id,name) values(222,'lisi');
insert into user(id,name) values(5000001,'wangwu');
insert into user(id,name) values(10000001,'zhaoliu');

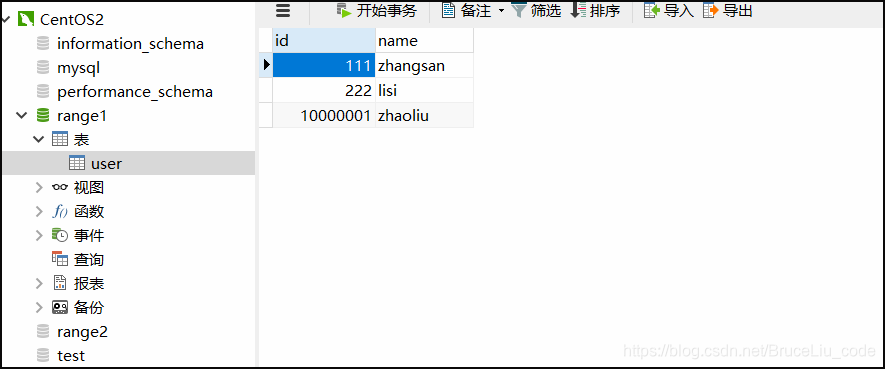
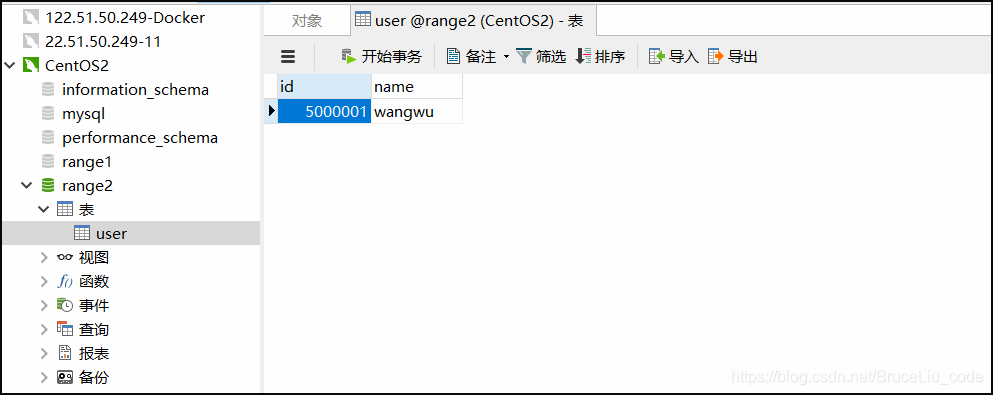
如上两图可见,成功实现了id在0-500W范围内就被插入到了第一个分片上dn1,id在500W-1000W范围内被插入到第二个分片上dn2,并且配置了如果ID都不在这两个范围内的默认节点,被分配到了第一个节点上(默认节点)
3.总结
实现范围分片大体步骤:
server.xml配置用户信息、逻辑库等;
schema.xml配置分片规则、分片表;
配置autopartition-long.txt文件,说明分片字段分片范围;
rule.xml配置分片规则以及默认节点等;
注意事项:分片规则配置文件autopartition-long.txt中配置的节点要跟dataNode数量对应上,不然可能会报错。
