1.简介
在MyCat中,有许多分片规则,比如枚举分片、取模分片、范围分片、一致性hash分片等等,每一种分片规则都需要根据项目中具体的业务已经数据量来决定,所以说没有哪一种分片规则很好,哪一种分片规则就不好,都是依业务来定。本文将对其中一种,也是比较简答的分片规则 - 枚举分片进行简单的介绍,并通过一个示例说明其用法以及规则。
2.实现方式
按照partition-hash-int-enum.txt配置的枚举匹配规则,将符合条件的记录分配到对应节点上,不满足条件的分配到默认节点(简单来讲,就是根据某个值,决定这条数据放到哪一个库里面)。
3.使用场景
比如有些业务需要按照省份或区县来进行保存,而全国省份区县是固定的,这时候可以考虑将使用枚举分片规则,具体使用场景可根据自己具体的业务场景确定。
4.实现步骤
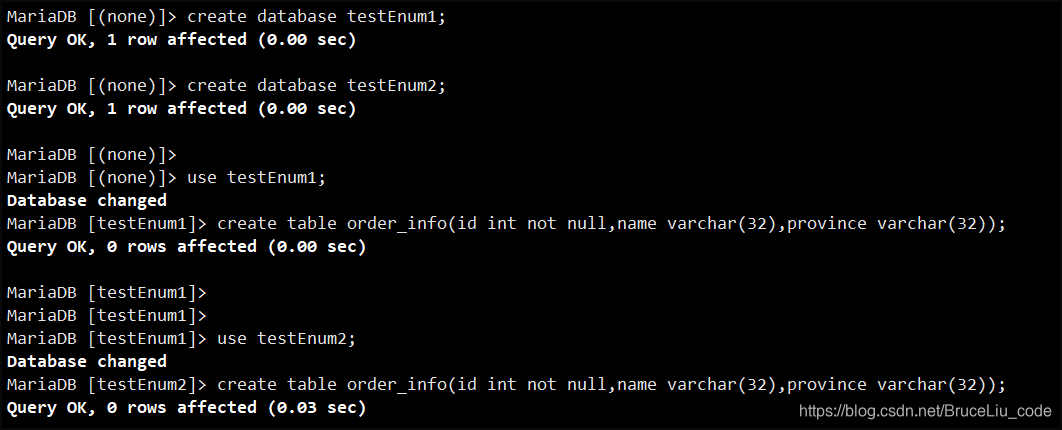
【a】创建数据库以及表:
create database testEnum1;
create database testEnum2;
use testEnum1;
create table order_info(id int not null,name varchar(32),province varchar(32));
use testEnum2;
create table order_info(id int not null,name varchar(32),province varchar(32));
【b】配置server.xml指定逻辑库,用户名密码等
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 -->
<property name="sequnceHandlerType">2</property>
<!-- <property name="useCompression">1</property>--> <!--1为开启mysql压缩协议-->
<!-- <property name="fakeMySQLVersion">5.6.20</property>--> <!--设置模拟的MySQL版本号-->
<!-- <property name="processorBufferChunk">40960</property> -->
<!--
<property name="processors">1</property>
<property name="processorExecutor">32</property>
-->
<!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena-->
<property name="processorBufferPoolType">0</property>
<!--默认是65535 64K 用于sql解析时最大文本长度 -->
<!--<property name="maxStringLiteralLength">65535</property>-->
<!--<property name="sequnceHandlerType">0</property>-->
<!--<property name="backSocketNoDelay">1</property>-->
<!--<property name="frontSocketNoDelay">1</property>-->
<!--<property name="processorExecutor">16</property>-->
<!--
<property name="serverPort">8066</property> <property name="managerPort">9066</property>
<property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property>
<property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> -->
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property>
<!--
off heap for merge/order/group/limit 1开启 0关闭
-->
<property name="useOffHeapForMerge">1</property>
<!--
单位为m
-->
<property name="memoryPageSize">1m</property>
<!--
单位为k
-->
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<!--
单位为m
-->
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">true</property>
</system>
<!-- 全局SQL防火墙设置 -->
<!--
<firewall>
<whitehost>
<host host="127.0.0.1" user="mycat"/>
<host host="127.0.0.2" user="mycat"/>
</whitehost>
<blacklist check="false">
</blacklist>
</firewall>
-->
<user name="root">
<property name="password">123456</property>
<property name="schemas">TESTENUM</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">123456</property>
<property name="schemas">TESTENUM</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
【c】配置schema.xml指定逻辑表,枚举分片规则、分片节点等
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTENUM" checkSQLschema="false" sqlMaxLimit="100">
<table name="order_info" dataNode="dn$1-2" rule="sharding-by-intfile-enum"/>
</schema>
<dataNode name="dn1" dataHost="localhost1" database="testEnum1" />
<dataNode name="dn2" dataHost="localhost1" database="testEnum2" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="192.168.70.128:3306" user="root" password="123">
</writeHost>
</dataHost>
</mycat:schema>
【d】配置rule.xml指定分片规则为枚举分片
<tableRule name="sharding-by-intfile-enum">
<rule>
<columns>province</columns>
<algorithm>hash-int-enum</algorithm>
</rule>
</tableRule>
<function name="hash-int-enum" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int-enum.txt</property>
<property name="type">1</property>
<property name="defaultNode">0</property>
</function>
mapFile属性: 切分规则匹配配置文件
type属性: 类型 ,1表示字符串,0表示是int类型
defaultNode属性: 默认的节点 ,小于0表示不设置默认节点,大于等于0表示设置默认节点
【e】配置partition-hash-int-enum.txt,指定哪个枚举值对应到哪个分片节点

[root@centos1 conf]# chmod 777 partition-hash-int-enum.txt
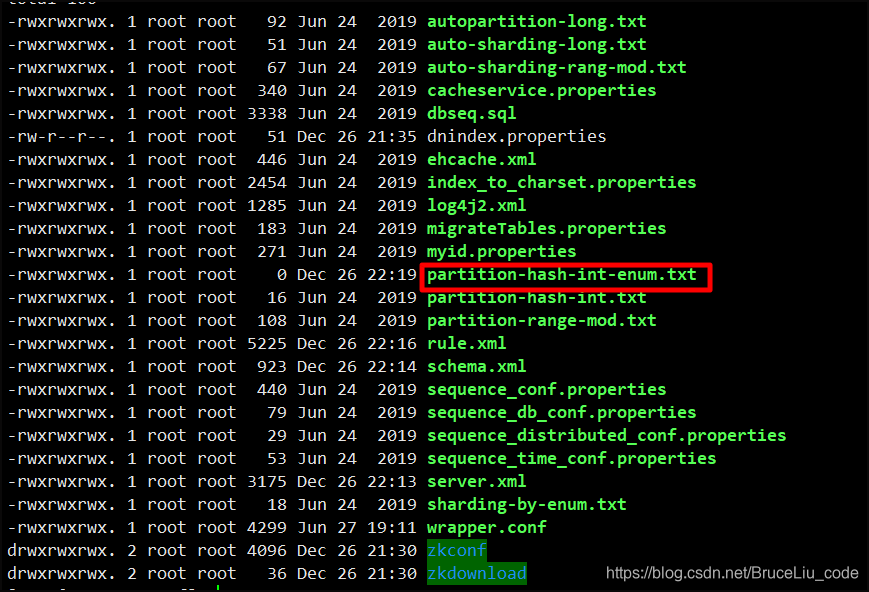
添加自定义的分片规则配置文件 vim partition-hash-int-enum.txt
gz=0
sz=1
【f】测试插入数据
重启mycat, 然后登录mycat:
然后插入数据进行测试:
insert into order_info(id,name,province) values('1111','1','gz');
insert into order_info(id,name,province) values('2222','2','sz');
根据枚举匹配结果,正常第一条记录应该匹配到第一个分片节点dn1, 第二条记录应该被保存在dn2节点。
逻辑库TESTENUM:
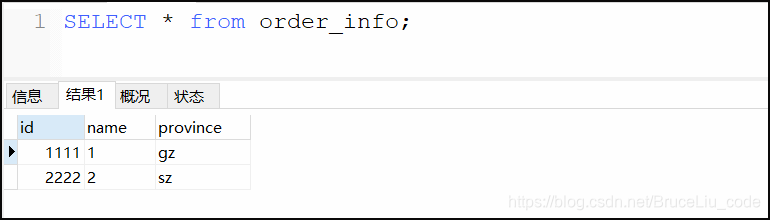
可见,逻辑库中已经成功插入了两条数据,下面我们分别查看这两条数据到底插入到哪个真实物理数据库中。
testEnum1数据库:
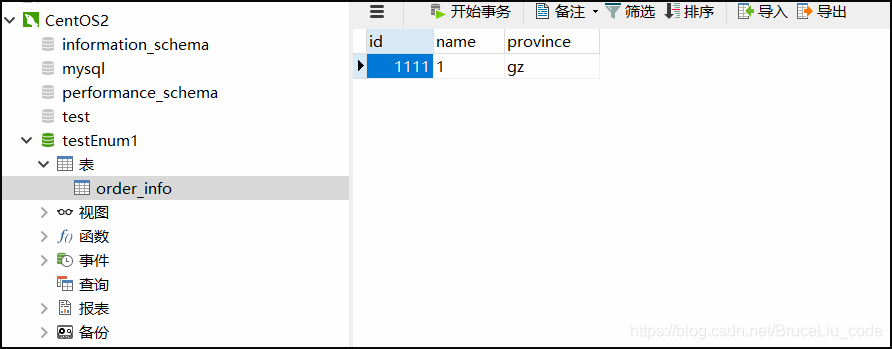
testEnum2数据库:
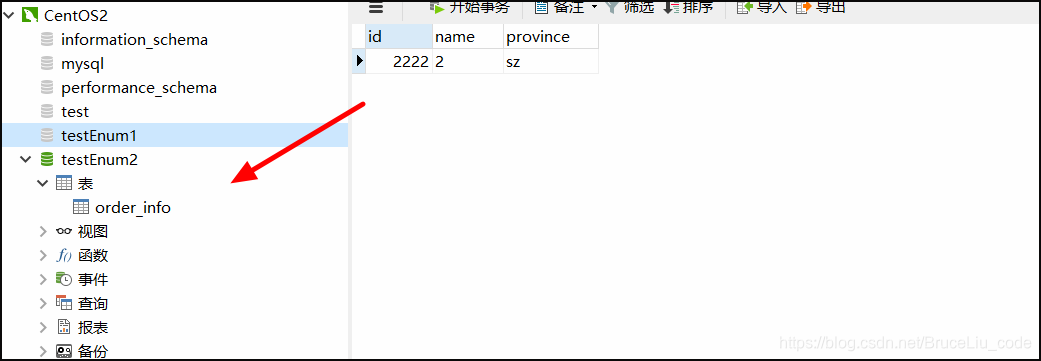
如上面两个图,说明数据确实按照预期枚举分片的规则进行路由了。province=gz的数据被路由到dn1, province=sz的数据被路由到dn2中。
如果碰到无法匹配的枚举值,将会走默认分片节点dn1,如下所示:
insert into order_info(id,name,province) values('3333','3','zh');
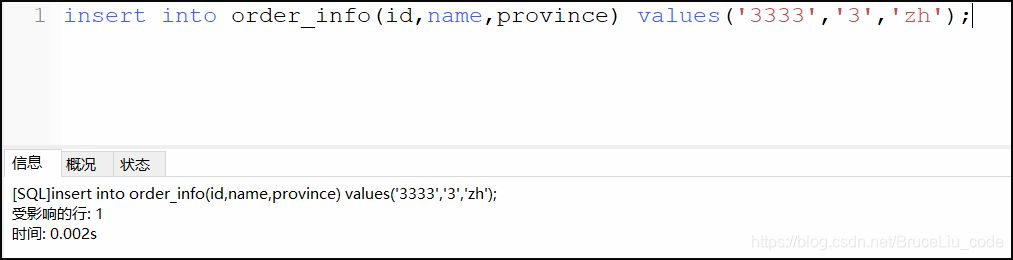
逻辑库:
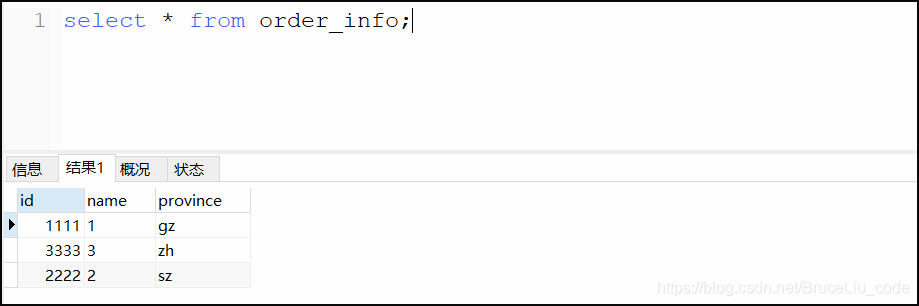 testEnum1数据库:
testEnum1数据库:

【g】查询测试
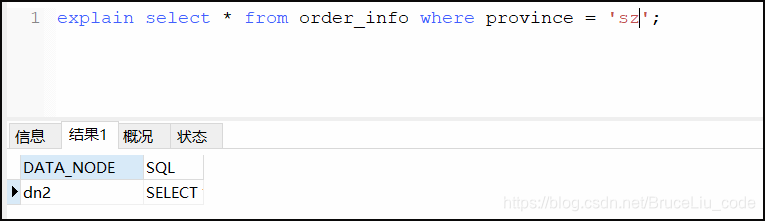
explain select * from order_info where province = 'sz';
使用分片字段进行查询:
不使用分片字段进行查询:
explain select * from order_info where name = '1';
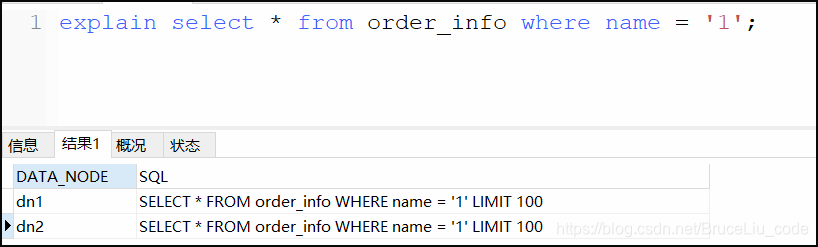
可见,如果没有使用分片字段进行查询的话,则查询sql语句会发送到所有的分片节点上去查询。
5.总结
以上就是关于枚举分片的详细实现步骤,总结需要注意的几点:
a. 自定义规则配置文件rule.xml,指定分片字段、分片函数以及mapFile;
b. schema.xml声明逻辑表的时候指定rule=“xxx”, xxx对应rule.xml中tableRule的name;
c. 添加自定义的分片规则配置文件 vim partition-hash-int-enum.txt;
另外,补充一下rule.xml配置文件说明:
rule.xml: 定义了很多各种分片算法和规则,在声明逻辑表的时候进行制定分片规则。
(1) tableRule 标签:
<tableRule name="mod-long">
<rule>
<columns>order_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
name属性:指定分片规则的名字,与schema.xml中table标签rule的名字对应
columns属性: 指定具体的分片字段
algorithm属性:指定分片函数,即分片算法,与funciton标签的name对应
(2) function 标签
<function name="hash-int"
class="org.opencloudb.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
name属性: 指定分片算法的名字,在rule标签中algorithm属性中使用
class属性: 指定分片算法具体的实现类名字
property属性: 指定分片算法需要用到的一些属性
