一: 简介
在数据切分处理中,特别是水平切分中,中间件最终要的两个处理过程就是数据的切分、数据的聚合。选择 合适的切分规则,至关重要,因为它决定了后续数据聚合的难易程度,甚至可以避免跨库的数据聚合处理。
可以通过全局表,ER分片表,数据冗余来尽量来避免跨库多表连接join。
二: 全局表
所谓全局表就是该表在每个分片上都会存在,并且每个分片上的全局表的数据完全一致。在进行数据插入操作时,mycat将把数据分发到全局表对应的所有分片上执行,在进行数据读取时候将会随机获取一个节点读取数据。当表的数据量不大,数据不经常变动,业务场景中经常会使用的表可以作为全局表,如字典表、配置表、商品表、用户表等。
在schemal.xml中可以通过type=“global”来标记此表为全局表
<table name="tbl_user" primaryKey="id" type="global" dataNode="dataNode1,dataNode2,dataNode3" />
全局表的作用就是避免跨库多表连接,如下面sql,当订单表关联用户表,因用户表已经在该分片上了,可以直接left join,如果此分片上没有tbl_user表,那我们只能先查tbl_order表,然后再查tbl_user表,然后使用Java代码组装数据
全局表可以直接join
# 全局表直接join
select
o.order_code,
o.amount,
u.username
from tbl_order o
left join tbl_user u on o.user_id = u.id
跨库连接通过代码组装数据
// 先查询tbl_order, 再查询tbl_user, 最后组装数据
List<Order> orderList = "select * from tbl_order";
List<User> userList = "select * from tbl_user";
orderList.forEach(order -> {
Long userId = order.getUserId;
List resultList = userList.stream().filter(user -> userId.equals(user.getId())).collect(Collectors.toList());
User user = resultList.get(0);
order.setUser(user);
});
三:ER分片表
业务中有些表是有父子关系的或者一对多的关系,如订单表tbl_order和订单项表tbl_order_item,我们可以通过合适的分片规则对父表进行分片(如根据订单id), 然后指定一下父表有哪些子表,这样当父表的一条数据被分片到某个节点,那么对应于父表的那条数据下的所有子表数据也会分配到和父表相同的节点上。当父表和子表都分配同一个分片上,就避免了跨库连接。这样的表被称为ER分片表,ER分片表也是为了避免跨库连接, ER分片表可以通过childTable来配置分片表。子表可以有多个,子表也可以嵌套子表
<!-- joinKey用于指定子表关联的字段;parentKey用于指定父表关联的字段;注意只有父表定义了分片规则rule子表是不定义的 -->
<table name="tbl_order" dataNode="dataNode1,dataNode2,dataNode3" rule="mod-long">
<childTable name="tbl_order_item" primaryKey="id" joinKey="order_id" parentKey="id" />
</table>
-- 如果某条订单被分配到节点1上(假如根据订单id使用取模的分配规则)
INSERT INTO tbl_order(id, order_code, user_id, amount)VALUES(1, '20181027160000000001', 1, 100);
-- 那么子表也会使用joinKey对应的值(即order_id)使用取模的分配规则,
-- 因tbl_order_item.order_id和tbl_order.id值是完全一样的,对同一个值使用同样的分配规则,
-- 那么这个订单的订单项也会分片到节点1上,即子表和父表被分到相同的片上
INSERT INTO tbl_order_item(id, order_id, goods_id, amount)VALUES(1, 1, 1, 100);
INSERT INTO tbl_order_item(id, order_id, goods_id, amount)VALUES(2, 1, 2, 200);
INSERT INTO tbl_order_item(id, order_id, goods_id, amount)VALUES(3, 1, 3, 300);
-- 因子表和父表被分到相同的片上,所以可以直接关联join,不用再使用Java组装数据了
select
o.order_code,
oi.goods_id,
oi.amount
from tbl_order o
left join tbl_order_item oi on o.id = oi.order_id
四:分片键选择
- 当你没有任何字段可以作为分片字段的时候,使用主键字段来分片,其优点是按照主键的查询最快,当采 用自动增长的序列号作为主键时,还能比较均匀的将数据分片在不同的节点上。
- 若有某个合适的业务字段比较合适作为分片字段,则建议采用此业务字段分片,选择分片字段的条件如下,常用的分片字段有日期、枚举值字段等
- 尽可能的比较均匀分布数据到各个节点上。
- 该业务字段是最频繁的或者最重要的查询条件。
五:常用的分片规则
Mycat内置了十多种分片规则,也支持自定义分片。
- 取模mod-long
- 自然月分片 sharding-by-month
- 按日期(天)分片sharding-by-date
- 按单月小时拆分sharding-by-hour
- 范围约定,提前规划好分片字段某个范围属于哪个分片,auto-sharding-long
- 范围求模分片
- 取模范围约束sharding-by-pattern
- 分片枚举sharding-by-intfile
- 固定分片hash算法
- 截取数字hash解析sharding-by-stringhash
- 一致性hash
- 日期范围hash分片rangeDateHash
- 截取数字做hash求模范围约束sharding-by-prefixpattern
- 应用指定,在运行阶段有应用自主决定路由到那个分片。sharding-by-substring
- 冷热数据分片 sharding-by-date
- 有状态分片算法
- crc32slot分片算法
① 取模mod-long
对分片字段求摸运算。
1. rule.xml
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
</mycat:rule>
即根据id进行十进制求模预算。分片列的值 % 分片数量 = 对应分片的数据库。
- 分片规则 名称mod-long
- 分片列 id
- 分片数量 3
2. schema.xml
配置分片规则rule=“mod-long”
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="testdb" checkSQLschema="false" sqlMaxLimit="100">
<table name="tbl_user" primaryKey="id" autoIncrement="true" dataNode="dataNode1,dataNode2,dataNode3" rule="mod-long"/>
</schema>
</mycat:schema>
3. 重启mycat
~ bin/mycat restart
4. mycat测试
DROP TABLE tbl_user;
CREATE TABLE `tbl_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`username` varchar(20) DEFAULT NULL,
`age` tinyint(4) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO tbl_user(id, username, age)VALUES(1, 'mengdeay', 18);
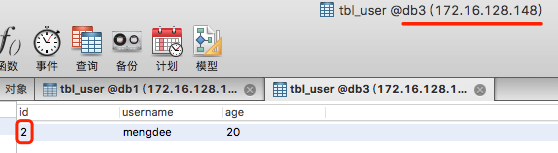
INSERT INTO tbl_user(id, username, age)VALUES(2, 'mengdee', 20);
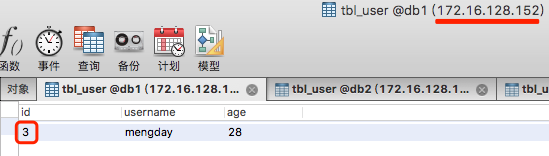
INSERT INTO tbl_user(id, username, age)VALUES(3, 'mengday', 28);
id count mod dataNode
1 % 3 = 1 dataNode2 172.16.128.153
2 % 3 = 2 dataNode3 172.16.128.148
3 % 3 = 0 dataNode1 172.16.128.152

②范围约定auto-sharding-long
提前规划好分片字段某个范围属于哪个分片。
1. rule.xml
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
</mycat:rule>
<function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
<!--
<property name="defaultNode">0</property>
-->
</function>
- 分片名称 auto-sharding-long
- 分片字段 id
- 分片范围映射文件 autopartition-long.txt
- defaultNode 超过范围后的默认节点, 如果没有配置会插入不进去,报错ERROR 1064 (HY000): can’t find any valid datanode :TBL_USER -> ID -> 15000001
mycat/conf/autopartition-long.txt
所有的节点配置都是从0开始,及0代表节点1,K=1000,M=10000.
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2
2. schema.xml
设置分片规则rule=“auto-sharding-long”
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="testdb" checkSQLschema="false" sqlMaxLimit="100">
<table name="tbl_user" primaryKey="id" autoIncrement="true" dataNode="dataNode1,dataNode2,dataNode3" rule="auto-sharding-long"/>
</schema>
</mycat:schema>
3. 重启mycat
~ bin/mycat restart
4. mycat测试
mysql> DROP TABLE tbl_user;
Query OK, 0 rows affected (0.02 sec)
mysql> CREATE TABLE `tbl_user` (
-> `id` bigint(20) NOT NULL AUTO_INCREMENT,
-> `username` varchar(20) DEFAULT NULL,
-> `age` tinyint(4) DEFAULT NULL,
-> PRIMARY KEY (`id`)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Query OK, 0 rows affected (0.02 sec)
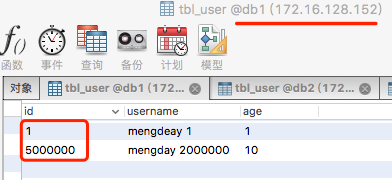
mysql> INSERT INTO tbl_user(id, username, age)VALUES(1, 'mengdeay 1', 1);
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO tbl_user(id, username, age)VALUES(5000000, 'mengday 2000000', 10);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO tbl_user(id, username, age)VALUES(5000001, 'mengday 2000001', 11);
Query OK, 1 row affected (0.01 sec)
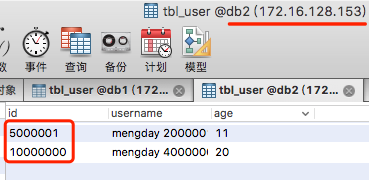
mysql> INSERT INTO tbl_user(id, username, age)VALUES(10000000, 'mengday 4000000', 20);
Query OK, 1 row affected (0.02 sec)
mysql> INSERT INTO tbl_user(id, username, age)VALUES(10000001, 'mengday 4000001', 21);
Query OK, 1 row affected (0.02 sec)
mysql> INSERT INTO tbl_user(id, username, age)VALUES(15000000, 'mengday 8000001', 30);
Query OK, 1 row affected (0.02 sec)
-- 由于这里没有配置defaultNode,所以会报错
mysql> INSERT INTO tbl_user(id, username, age)VALUES(15000001, 'mengday 8000001', 31);
ERROR 1064 (HY000): can't find any valid datanode :TBL_USER -> ID -> 15000001
0-500M=0 172.16.128.152 db1
500M-1000M=1 172.16.128.153 db2
1000M-1500M=2 172.16.128.148 db3
③分片枚举sharding-by-intfile
通过在配置文件中配置可能的枚举 id,自己配置分片,本规则适用于特定的场景,比如有些业务需要按照省 份或区县来做保存,而全国省份区县固定的,这类业务使用本条规则
1.rule.xml
修改sharding-by-intfile分片规则对应的columns,这里该为省份id province_id
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="sharding-by-intfile">
<rule>
<columns>province_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">0</property>
<property name="defaultNode">0</property>
</function>
</mycat:rule>
- type 默认值为 0,0表示Integer,非零表示String
- defaultNode 默认节点:小于0表示不设置默认节点,大于等于0表示设置默认节点. 节点的索引从0开始。默认节点的作用:枚举分片时,如果碰到不识别的枚举值,就让它路由到默认节点 * 如果不配置默认节点(defaultNode 值小于 0 表示不配置默认节点),碰到不识别的枚举值就会报错,like this:can’t find datanode for sharding column:column_name val:ffffffff
2.mycat/conf/partition-hash-int.txt
因自己只有3个节点,这里为了测试只配置了3个枚举值10000、10010、10020
10000=0
10010=1
10020=2
3.schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="testdb" checkSQLschema="false" sqlMaxLimit="100">
<table name="tbl_user" primaryKey="id" autoIncrement="true" dataNode="dataNode1,dataNode2,dataNode3" rule="sharding-by-intfile"/>
</schema>
</mycat:schema>
4.重启mycat
~ bin/mycat restart
5.mycat测试
DROP TABLE tbl_user;
CREATE TABLE `tbl_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`username` varchar(20) DEFAULT NULL,
`age` tinyint(4) DEFAULT NULL,
`province_id` bigint(4) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
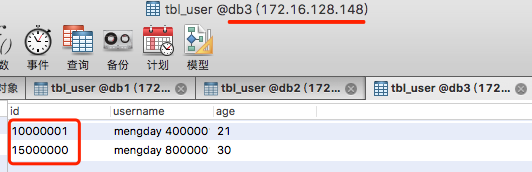
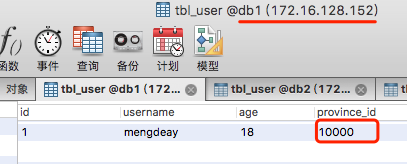
INSERT INTO tbl_user(id, username, age, province_id)VALUES(1, 'mengdeay', 18, 10000);
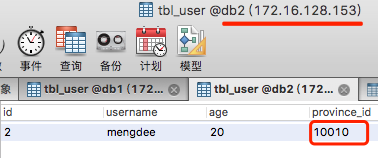
INSERT INTO tbl_user(id, username, age, province_id)VALUES(2, 'mengdee', 20, 10010);
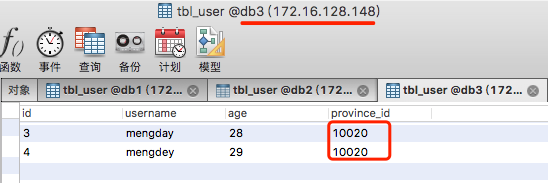
INSERT INTO tbl_user(id, username, age, province_id)VALUES(3, 'mengday', 28, 10020);
INSERT INTO tbl_user(id, username, age, province_id)VALUES(4, 'mengdey', 29, 10020);
10000=0 172.16.128.152 db1
10010=1 172.16.128.153 db2
10020=2 172.16.128.148 db3
④自然月分片 sharding-by-month
按月份列分区 ,每个自然月一个分片,格式 between 操作解析的范例。
1.rule.xml
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<function name="partbymonth" class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2018-10-01</property>
</function>
</mycat:rule>
- sBeginDate 开始日期,无默认值
- sEndDate 结束日期,无默认值
节点从0开始分片
2.使用场景
- 场景1: 默认设置,节点数量必须是12个,从1月~12月
无论哪一年,1月分片到节点0,2月分片到节点1,以此类推,12月分片到节点11
- “2014-01-01”=节点0
- “2013-01-01”=节点0
- “2018-05-01”=节点4
- “2019-12-01”=节点11
- 场景2: 设置sBeginDate=“2018-11-01”
小于sBeginDate的yyyy-MM将找不到节点,从yyyy-MM开始为第0个节点,每往后一个月就递增一个节点,这种方式随着时间需要很多节点
- “2017-01-01”=未找到节点
- “2018-11-01”=节点1
- “2019-01-01”=节点2
- “2019-12-01”=节点13
-
场景3: 设置sBeginDate=“2018-01-01”、sEndDate=“2018-12-01”
该配置和场景1的配置效果完全一样,场景一的配置效率更高 -
场景4: 设置sBeginDate=“2018-01-01”、sEndDate=“2018-03-01”
该配置标识只有3个节点;很难与月份对应上;平均分散到3个节点上
3.schema.xml
设置rule=“sharding-by-month”
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="testdb" checkSQLschema="false" sqlMaxLimit="100">
<table name="tbl_user" primaryKey="id" autoIncrement="true" dataNode="dataNode1,dataNode2,dataNode3" rule="sharding-by-month"/>
</schema>
</mycat:schema>
4.重启mycat
~ bin/mycat restart
5.mycat测试
DROP TABLE tbl_user;
CREATE TABLE `tbl_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`username` varchar(20) DEFAULT NULL,
`age` tinyint(4) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
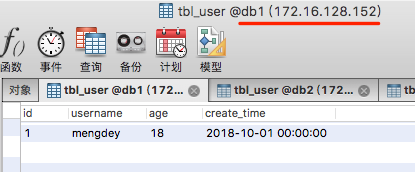
INSERT INTO tbl_user(id, username, age, create_time)VALUES(1, 'mengdey', 18, '2018-10-01 00:00:00');
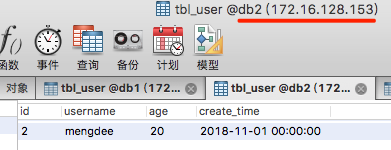
INSERT INTO tbl_user(id, username, age, create_time)VALUES(2, 'mengdee', 20, '2018-11-01 00:00:00');
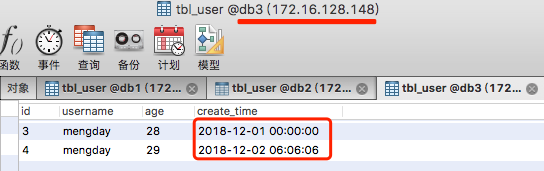
INSERT INTO tbl_user(id, username, age, create_time)VALUES(3, 'mengday', 28, '2018-12-01 00:00:00');
INSERT INTO tbl_user(id, username, age, create_time)VALUES(4, 'mengday', 29, '2018-12-02 06:06:06');
2018-10-01 172.16.128.152 db1
2018-11-01 172.16.128.153 db2
2018-12-01 172.16.128.148 db3
⑤固定分片hash算法rule1
本条规则类似于十进制的求模运算,区别在于是二进制的操作,是取 id 的二进制低 10 位,即 id 二进制 &1111111111。
此算法的优点在于如果按照 10 进制取模运算,在连续插入 1-10 时候 1-10 会被分到 1-10 个分片,增 大了插入的事务控制难度,而此算法根据二进制则可能会分到连续的分片,减少插入事务事务控制难度。
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">4</property>
<property name="partitionLength">256</property>
</function>
</mycat:rule>
吐槽: 感觉rule1和func1命名很随意
- partitionCount 分片个数列表
- partitionLength 分片范围列表
- 示例配置是平均分为4分片,partitionCount*partitionLength=1024