文章目录
一、MyCAT介绍
1、什么是MyCAT?
简单的说,MyCAT就是:
一个彻底开源的,面向企业应用开发的“大数据库集群”
支持事务、ACID、可以替代Mysql的加强版数据库
一个可以视为“Mysql”集群的企业级数据库,用来替代昂贵的Oracle集群
一个融合内存缓存技术、Nosql技术、HDFS大数据的新型SQL Server
结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
一个新颖的数据库中间件产品
MyCAT的目标是:低成本的将现有的单机数据库和应用平滑迁移到“云”端,解决数据存储和业务规模迅速增长情况下的数据瓶颈问题。
2、MyCAT的关键特性
支持 SQL 92标准
支持Mysql集群,可以作为Proxy使用
支持JDBC连接ORACLE、DB2、SQL Server,将其模拟为MySQL Server使用
支持galera for mysql集群,percona-cluster或者mariadb cluster,提供高可用性数据分片集群
自动故障切换,高可用性
支持读写分离,支持Mysql双主多从,以及一主多从的模式
支持全局表,数据自动分片到多个节点,用于高效表关联查询
支持独有的基于E-R 关系的分片策略,实现了高效的表关联查询
多平台支持,部署和实施简单
3、MyCAT架构
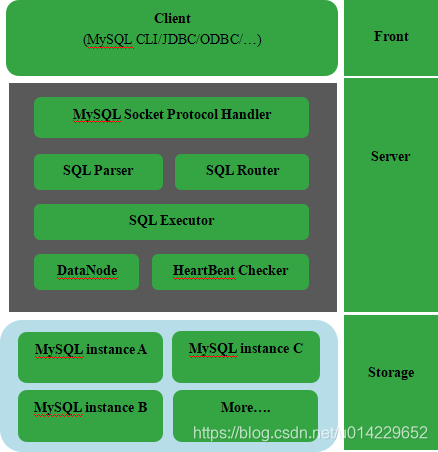
如图所示:MyCAT使用Mysql的通讯协议模拟成了一个Mysql服务器,并建立了完整的Schema(数据库)、Table (数据表)、User(用户)的逻辑模型,并将这套逻辑模型映射到后端的存储节点DataNode(MySQL Instance)上的真实物理库中,这样一来,所有能使用Mysql的客户端以及编程语言都能将MyCAT当成是Mysql Server来使用,不必开发新的客户端协议。
二、Mycat解决的问题
- 性能问题
- 数据库连接过多
- E-R分片难处理
- 可用性问题
- 成本和伸缩性问题

1、Mycat对多数据库的支持

2、分片策略
MyCAT支持水平分片与垂直分片:
- 水平分片:一个表格的数据分割到多个节点上,按照行分隔。
- 垂直分片:一个数据库中多个表格A,B,C,A存储到节点1上,B存储到节点2上,C存储到节点3上。

MyCAT通过定义表的分片规则来实现分片,每个表格可以捆绑一个分片规则,每个分片规则指定一个分片字段并绑定一个函数,来实现动态分片算法。
1、Schema:逻辑库,与MySQL中的Database(数据库)对应,一个逻辑库中定义了所包括的Table。
2、Table:表,即物理数据库中存储的某一张表,与传统数据库不同,这里的表格需要声明其所存储的逻辑数据节点DataNode。在此可以指定表的分片规则。
3、DataNode:MyCAT的逻辑数据节点,是存放table的具体物理节点,也称之为分片节点,通过DataSource来关联到后端某个具体数据库上
4、DataSource:定义某个物理库的访问地址,用于捆绑到Datanode上
四、Mycat的下载及安装
1、下载mycat
cd /home/download
mkdir mycat
cd mycat
wget http://dl.mycat.io/1.6.6.1/Mycat-server-1.6.6.1-release-20181031195535-linux.tar.gz
2、Mycat安装
tar -zxvf Mycat-server-1.6.6.1-release-20181031195535-linux.tar.gz
mv mycat/ /usr/local/mycat
cd /usr/local/mycat/
# 修改端口号
vim conf/server.xml
修改端口号如下:
<property name="serverPort">38066</property> <property name="managerPort">39066</property>
默认服务端口为8066
3、启动
cd /usr/local/mycat/
./bin/mycat start
tail -1000f logs/mycat.log
日志如下:

这里会报连接错误,我本地mysql端口不是默认的3306,所以mycat去连接默认端口是连不通,所以还需要配置。
五、Mycat分片(横向切分)
1、准备
一台mysql服务节点
192.0.0.1
端口都是 23306
用户名密码:root 123456
mysql安装可以参考我的另一篇博客:
https://blog.csdn.net/u014229652/article/details/84573655
2、需求
把商品表分片存储到两个个数据节点上。这里放在同一个mysql服务上的两个不同的database里面
3、配置schema.xml
①、Schema.xml介绍
Schema.xml作为MyCat中重要的配置文件之一,管理着MyCat的逻辑库、表、分片规则、DataNode以及DataSource。弄懂这些配置,是正确使用MyCat的前提。这里就一层层对该文件进行解析。
schema 标签用于定义MyCat实例中的逻辑库
Table 标签定义了MyCat中的逻辑表
dataNode 标签定义了MyCat中的数据节点,也就是我们通常说所的数据分片。
dataHost标签在mycat逻辑库中也是作为最底层的标签存在,直接定义了具体的数据库实例、读写分离配置和心跳语句。
②Schema.xml配置
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="goods" primaryKey="ID" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
</schema>
<!-- <dataNode name="dn1$0-743" dataHost="localhost1" database="db$0-743"
/> -->
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<!--<dataNode name="dn4" dataHost="sequoiadb1" database="SAMPLE" />
<dataNode name="jdbc_dn1" dataHost="jdbchost" database="db1" />
<dataNode name="jdbc_dn2" dataHost="jdbchost" database="db2" />
<dataNode name="jdbc_dn3" dataHost="jdbchost" database="db3" /> -->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root"
password="123456">
</writeHost>
</dataHost>
</mycat:schema>
schema 标签:
schema 标签用于定义MyCat实例中的逻辑库,MyCat可以有多个逻辑库,每个逻辑库都有自己的相关配置。可以使用 schema 标签来划分这些不同的逻辑库。如果不配置 schema 标签,所有的表配置,会属于同一个默认的逻辑库。
checkSQLschema:
当该值设置为 true 时,如果我们执行语句"select * from TESTDB.travelrecord;", 则MyCat会把语句修改为"select * from
travelrecord;"。 即把表示schema的字符去掉,避免发送到后端数据库执行时报 “(ERROR 1146 (42S02): Table
‘testdb.travelrecord’ doesn’t exist)。”
不过,即使设置该值为 true ,如果语句所带的是并非是schema指定的名字,例如:“select * from db1.travelrecord;” 那么MyCat并不会删除db1这个字段,如果没有定义该库的话则会报错,所以在提供SQL语句的最好是不带这个字段。
sqlMaxLimit
当该值设置为某个数值时。每条执行的SQL语句,如果没有加上limit语句,MyCat也会自动的加上所对应的值。例如设置值为
100,执行**select * from TESTDB.travelrecord;的效果为和执行select * from TESTDB.travelrecord limit 100;**相同。
不设置该值的话,MyCat默认会把查询到的信息全部都展示出来,造成过多的输出。所以,在正常使用中,还是建议加上一个
值,用于减少过多的数据返回。
当然SQL语句中也显式的指定limit的大小,不受该属性的约束。
需要注意的是,如果运行的schema为非拆分库的,那么该属性不会生效。需要手动添加limit语句
Table 标签定义了MyCat 中的逻辑表,所有需要拆分的表都需要在这个标签中定义。
table 标签的相关属性:
name 属性:
定义逻辑表的表名,这个名字就如同我在数据库中执行create table 命令指定的名字一样,同个schema 标
签中定义的名字必须唯一。
dataNode 属性:
定义这个逻辑表所属的dataNode, 该属性的值需要和dataNode 标签中name 属性的值相互对应。
如果需要定义的dn 过多可以使用如下的方法减少配置:
<table name="travelrecord" dataNode="multipleDn$0-99,multipleDn2$100-199" rule="auto-shardinglong"
></table>
73
<dataNode name="multipleDn$0-99" dataHost="localhost1" database="db$0-99" ></dataNode>
<dataNode name="multipleDn2$100-199" dataHost="localhost1" database=" db$100-199" ></dataNode>
这里需要注意的是database 属性所指定的真实database name 需要在后面添加一个,例如上面的例子中,
我需要在真实的mysql 上建立名称为dbs0 到dbs99 的database。
rule 属性:
该属性用于指定逻辑表要使用的规则名字,规则名字在rule.xml 中定义,必须与tableRule 标签中name 属
性属性值一一对应。
ruleRequired 属性:
该属性用于指定表是否绑定分片规则,如果配置为true,但没有配置具体rule 的话,程序会报错。
primaryKey 属性:
该逻辑表对应真实表的主键,例如:分片的规则是使用非主键进行分片的,那么在使用主键查询的时候,就
会发送查询语句到所有配置的DN 上,如果使用该属性配置真实表的主键。难么MyCat 会缓存主键与具体DN 的
信息,那么再次使用非主键进行查询的时候就不会进行广播式的查询,就会直接发送语句给具体的DN,但是尽管
配置该属性,如果缓存并没有命中的话,还是会发送语句给具体的DN,来获得数据。
type 属性:
该属性定义了逻辑表的类型,目前逻辑表只有“全局表”和”普通表”两种类型。对应的配置:
全局表:global。
普通表:不指定该值为globla 的所有表。
autoIncrement 属性:
mysql 对非自增长主键,使用last_insert_id()是不会返回结果的,只会返回0。所以,只有定义了自增长主
键的表才可以用last_insert_id()返回主键值。mycat 目前提供了自增长主键功能,但是如果对应的mysql 节点上数据表,没有定义auto_increment,那么在mycat 层调用last_insert_id()也是不会返回结果的。
由于insert 操作的时候没有带入分片键,mycat 会先取下这个表对应的全局序列,然后赋值给分片键。这样
才能正常的插入到数据库中,最后使用last_insert_id()才会返回插入的分片键值。
如果要使用这个功能最好配合使用数据库模式的全局序列。使用autoIncrement=“true” 指定这个表有使用自增长主键,这样mycat 才会不抛出分片键找不到的异常。使用autoIncrement=“false” 来禁用这个功能,当然你也可以直接删除掉这个属性。默认就是禁用的。
subTables属性:
使用方式添加subTables="t_order$1-2,t_order3"。
目前分表1.6 以后开始支持并且dataNode 在分表条件下只能配置一个,分表条件下不支持各种条件的
join 语句。
needAddLimit 属性:
指定表是否需要自动的在每个语句后面加上limit 限制。由于使用了分库分表,数据量有时会特别巨大。这时
候执行查询语句,如果恰巧又忘记了加上数量限制的话。那么查询所有的数据出来,也够等上一小会儿的。
所以,mycat 就自动的为我们加上LIMIT 100。当然,如果语句中有limit,就不会在次添加了。
这个属性默认为true,你也可以设置成false`禁用掉默认行为。
childTable 标签:
childTable 标签用于定义E-R 分片的子表。通过标签上的属性与父表进行关联。
name 属性:
定义子表的表名
joinKey 属性:
插入子表的时候会使用这个列的值查找父表存储的数据节点
parentKey 属性:
属性指定的值一般为与父表建立关联关系的列名。程序首先获取joinkey 的值,再通过parentKey 属性指定
的列名产生查询语句,通过执行该语句得到父表存储在哪个分片上。从而确定子表存储的位置。
primaryKey 属性:
同table 标签所描述的。
needAddLimit 属性:
同table 标签所描述的。
<table name="customer" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id"
parentKey="id">
<childTable name="order_items" joinKey="order_id"
parentKey="id" />
</childTable>
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id"
parentKey="id" />
</table>
dataNode 标签
<dataNode name="dn1" dataHost="lch3307" database="db1" ></dataNode>
dataNode 标签定义了MyCat 中的数据节点,也就是我们通常说所的数据分片。一个dataNode 标签就是
一个独立的数据分片。
例子中所表述的意思为:使用名字为lch3307 数据库实例上的db1 物理数据库,这就组成一个数据分片,最
后,我们使用名字dn1 标识这个分片。
name 属性:
定义数据节点的名字,这个名字需要是唯一的,我们需要在table 标签上应用这个名字,来建立表与分片对
应的关系。
dataHost 属性:
该属性用于定义该分片属于哪个数据库实例的,属性值是引用dataHost 标签上定义的name 属性。
database 属性:
该属性用于定义该分片属性哪个具体数据库实例上的具体库,因为这里使用两个纬度来定义分片,就是:实
例+具体的库。因为每个库上建立的表和表结构是一样的。所以这样做就可以轻松的对表进行水平拆分。
dataHost 标签
作为Schema.xml 中最后的一个标签,该标签在mycat 逻辑库中也是作为最底层的标签存在,直接定义了具
体的数据库实例、读写分离配置和心跳语句。现在我们就解析下这个标签。
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="123456">
<!-- can have multi read hosts -->
<!-- <readHost host="hostS1" url="localhost:3306" user="root" password="123456"/> -->
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
name 属性:
唯一标识dataHost 标签,供上层的标签使用。
maxCon 属性
指定每个读写实例连接池的最大连接。也就是说,标签内嵌套的writeHost、readHost 标签都会使用这个属
性的值来实例化出连接池的最大连接数。
minCon 属性
指定每个读写实例连接池的最小连接,初始化连接池的大小。
balance 属性
负载均衡类型,目前的取值有3 种:
1. balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的writeHost 上。
2. balance="1",全部的readHost 与stand by writeHost 参与select 语句的负载均衡,简单的说,当双
主双从模式(M1->S1,M2->S2,并且M1 与M2 互为主备),正常情况下,M2,S1,S2 都参与select 语句的负载
均衡。
3. balance="2",所有读操作都随机的在writeHost、readhost 上分发。
4. balance="3",所有读请求随机的分发到wiriterHost 对应的readhost 执行,writerHost 不负担读压
力,注意balance=3 只在1.4 及其以后版本有,1.3 没有。
writeType 属性
负载均衡类型,目前的取值有3 种:
1. writeType="0", 所有写操作发送到配置的第一个writeHost,第一个挂了切到还生存的第二个
writeHost,重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties .
2. writeType="1",所有写操作都随机的发送到配置的writeHost,1.5 以后废弃不推荐。
dbType 属性
指定后端连接的数据库类型,目前支持二进制的mysql 协议,还有其他使用JDBC 连接的数据库。例如:
mongodb、oracle、spark 等。
dbDriver 属性
指定连接后端数据库使用的Driver,目前可选的值有native 和JDBC。使用native 的话,因为这个值执行的
是二进制的mysql 协议,所以可以使用mysql 和maridb。其他类型的数据库则需要使用JDBC 驱动来支持。
从1.6 版本开始支持postgresql 的native 原始协议。
如果使用JDBC 的话需要将符合JDBC 4 标准的驱动JAR 包放到MYCAT\lib 目录下,并检查驱动JAR 包中包
括如下目录结构的文件:META-INF\services\java.sql.Driver。在这个文件内写上具体的Driver 类名,例如:
com.mysql.jdbc.Driver。
switchType 属性
-1 表示不自动切换
1 默认值,自动切换
2 基于MySQL 主从同步的状态决定是否切换
心跳语句为show slave status
3 基于MySQL galary cluster 的切换机制(适合集群)(1.4.1)
心跳语句为show status like ‘wsrep%’
heartbeat 标签
这个标签内指明用于和后端数据库进行心跳检查的语句。例如,MYSQL 可以使用select user(),Oracle 可以
使用select 1 from dual 等。
这个标签还有一个connectionInitSql 属性,主要是当使用Oracla 数据库时,需要执行的初始化SQL 语句就
这个放到这里面来。例如:alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss'
1.4 主从切换的语句必须是:show slave status
writeHost 标签、readHost 标签
这两个标签都指定后端数据库的相关配置给mycat,用于实例化后端连接池。唯一不同的是,writeHost 指
定写实例、readHost 指定读实例,组着这些读写实例来满足系统的要求。
在一个dataHost 内可以定义多个writeHost 和readHost。但是,如果writeHost 指定的后端数据库宕机,
那么这个writeHost 绑定的所有readHost 都将不可用。另一方面,由于这个writeHost 宕机系统会自动的检测
到,并切换到备用的writeHost 上去。
这两个标签的属性相同,这里就一起介绍。
host 属性
用于标识不同实例,一般writeHost 我们使用*M1,readHost 我们用*S1。
url 属性
后端实例连接地址,如果是使用native 的dbDriver,则一般为address:port 这种形式。用JDBC 或其他的
dbDriver,则需要特殊指定。当使用JDBC 时则可以这么写:jdbc:mysql://localhost:3306/。
user 属性
后端存储实例需要的用户名字。
password 属性
后端存储实例需要的密码。
weight 属性
权重配置在readhost 中作为读节点的权重(1.4 以后)。
usingDecrypt 属性
是否对密码加密默认0 否如需要开启配置1,同时使用加密程序对密码加密,加密命令为:
执行mycat jar 程序(1.4.1 以后):
java -cp Mycat-server-1.4.1-dev.jar io.mycat.util.DecryptUtil 1:host:user:password
Mycat-server-1.4.1-dev.jar 为mycat download 下载目录的jar
1:host:user:password 中1 为db 端加密标志,host 为dataHost 的host 名称
4、配置server.xml
①、Server.xml介绍
server.xml几乎保存了所有mycat需要的系统配置信息。最常用的是在此配置用户名、密码及权限。
②、Server.xml配置
<user name="mycat">
<property name="password">qinhe123456</property>
<property name="schemas">TESTDB</property>
<!--
<property name="readOnly">false</property>
-->
</user>
5、配置rule.xml
rule.xml里面就定义了我们对表进行拆分所涉及到的规则定义。我们可以灵活的对表使用不同的分片算法,或者对表使用相同的算法但具体的参数不同。这个文件里面主要有tableRule和function这两个标签。在具体使用过程中可以按照需求添加tableRule和function。
此配置文件可以不用修改,使用默认即可。
6、测试分片
①、创建表
配置完毕后,重新启动mycat。使用mysql客户端连接mycat,
cd /usr/local/mycat/
./bin/mycat restart
tail -1000f logs/mycat.log
用navicat连接mycat
需要先在mysql实例中创建db1和db2、db3这三个数据库,mycat里面的TESTDB逻辑库是自动就有的。
然后在mycat中执行一下sql语句
DROP TABLE IF EXISTS `goods`;
CREATE TABLE `goods` (
`id` bigint(20) NOT NULL COMMENT '商品id,同时也是商品编号',
`title` varchar(100) NOT NULL COMMENT '商品标题',
`sell_point` varchar(500) DEFAULT NULL COMMENT '商品卖点',
`price` bigint(20) NOT NULL COMMENT '商品价格,单位为:分',
`num` int(10) NOT NULL COMMENT '库存数量',
`barcode` varchar(30) DEFAULT NULL COMMENT '商品条形码',
`image` varchar(500) DEFAULT NULL COMMENT '商品图片',
`cid` bigint(10) NOT NULL COMMENT '所属类目,叶子类目',
`status` tinyint(4) NOT NULL DEFAULT '1' COMMENT '商品状态,1-正常,2-下架,3-删除',
`created` datetime NOT NULL COMMENT '创建时间',
`updated` datetime NOT NULL COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `cid` (`cid`),
KEY `status` (`status`),
KEY `updated` (`updated`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='商品表';
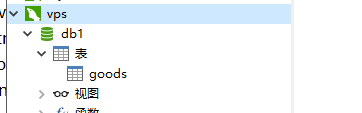
可以发现mycat里面和mysql实例里面的db1和db2中的goods表都已经生成

②、插入数据
- 执行以下语句:
INSERT INTO goods(ID,TITLE,SELL_POINT,PRICE,NUM,BARCODE,IMAGE,CID,STATUS,CREATED,UPDATED) VALUES ('1', 'new2 - 阿尔卡特 (OT-927) 炭黑 联通3G手机 双卡双待', '清仓!仅北京,武汉仓有货!', '29900000', '99999', '', 'http://image.taotao.com/jd/4ef8861cf6854de9889f3db9b24dc371.jpg', '560', '1', '2015-03-08 21:33:18', '2015-04-11 20:38:38');
mycat中出现一行数据,同时在db1数据库中也出现了这条数据,db2、db3没有
- 把主键改成5000000,再插入一条
INSERT INTO goods(ID,TITLE,SELL_POINT,PRICE,NUM,BARCODE,IMAGE,CID,STATUS,CREATED,UPDATED) VALUES ('5000000', 'new2 - 阿尔卡特 (OT-927) 炭黑 联通3G手机 双卡双待', '清仓!仅北京,武汉仓有货!', '29900000', '99999', '', 'http://image.taotao.com/jd/4ef8861cf6854de9889f3db9b24dc371.jpg', '560', '1', '2015-03-08 21:33:18', '2015-04-11 20:38:38');
这条数据还是在db1中。
- 把主键改成5000001,再插入一条
INSERT INTO goods(ID,TITLE,SELL_POINT,PRICE,NUM,BARCODE,IMAGE,CID,STATUS,CREATED,UPDATED) VALUES ('5000001', 'new2 - 阿尔卡特 (OT-927) 炭黑 联通3G手机 双卡双待', '清仓!仅北京,武汉仓有货!', '29900000', '99999', '', 'http://image.taotao.com/jd/4ef8861cf6854de9889f3db9b24dc371.jpg', '560', '1', '2015-03-08 21:33:18', '2015-04-11 20:38:38');
这条数据在db2中了。
结论:
mycat的长整型分片规则(sharding-by-intfile)规定一张表中的主键不能大于五百万(5000000),如果大于五百万,就会自动插入在下一个数据节点中,如果没有下一个数据节点,则会报找不到datanode的错误。
