前言
在上一篇,详细了解了使用mycat进行数据库的垂直拆分和表的水平拆分,本篇在此基础上继续探讨mycat的常用分片规则。
什么是分片规则?
分片规则就是按照一定的规则(算法),将数据分散存储到多个物理节点上,从根本上来说,是为了解决单节点数据容量过大而引发的性能问题。
Mycat 常用分片规则
mycat提供了多种分片规则以供使用,常见的分片规则包括:
- 范围分片;
- 取模分片;
- 一致性hash分片;
- 枚举分片;
- 应用指定分片;
- 固定hash分片;
- 按天/月分片;
接下来就以上列举的常用的分片规则,结合实际案例做较为详细的探讨。
一、范围分片
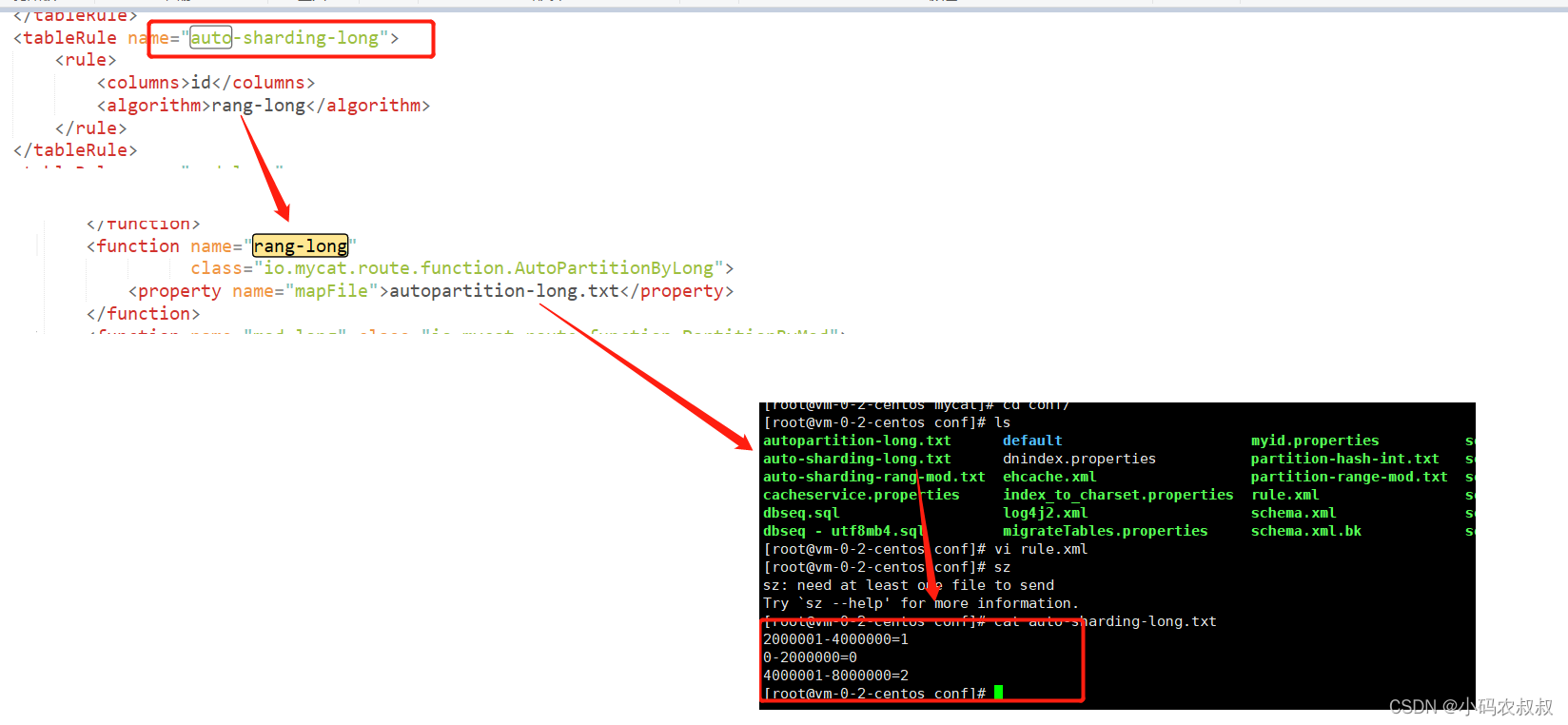
在mycat的环境搭建一篇中,还记得下面这段配置吗,在这段配置中,table 标签中有过 rule的属性,这里配置的是 auto-sharding-long
<schema name="DB01" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="TB_ORDER" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" splitTableNames ="true"/>
</schema>
而auto-sharding-long 这个分片规则最终表现出来的效果就是范围分片,如下图所示,简单来说就是,通过配置这种类型的规则,数据将会按照范围区间进行存储,默认情况下,按照200万为区间进行划分;
如果默认的数据区间范围不能满足你的要求,可以考虑手动调整,比如将200万一个区间扩大至500万一个区间;
二、取模分片
取模分片原理
根据指定的字段值与节点数量进行求模运算,根据运算结果, 来决定该数据属于哪一个分片

在上一篇的最后,我们在进行表的水平拆分时,对 tb_log 这张表做了实验,将一张数据量非常大的大表按照取模的规则,分散到3个数据库实例上去,用到的就是取模分片,核心配置如下,
<schema name="DB02" checkSQLschema="true" sqlMaxLimit="100">
<table name="tb_log" dataNode="dn1,dn2,dn3" primaryKey="id" rule="mod-long" />
</schema>
<dataNode name="dn1" dataHost="dhost1" database="dblog" />
<dataNode name="dn2" dataHost="dhost2" database="dblog" />
<dataNode name="dn3" dataHost="dhost3" database="dblog" />
对应到rule.xml中的关键配置
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>关键参数说明
- columns :标识将要分片的表字段
- algorithm : 指定分片函数与function的对应关系
- class : 指定该分片算法对应的类
- count : 数据节点的数量
其中最关键的配置在rule这里,rule="mod-long" ,即使用这个规则就可以完成取模分片操作,使用这种分片规则的好处是,各个数据节点的数据比较均匀,不会造成严重的数据倾斜问题;
但是这种分片规则,主要是针对数字类型的字段适用,使用的时候注意这点。
三、一致性 hash 分片
一致性hash这个词语想必大家并不陌生吧,顾名思义,即相同的哈希因子,通过计算之后,总是被划分到相同的分区表,不会因为分区节点的增加而改变原来数据的分区位置,可以有效解决分布式数据的拓容问题,比如nginx负载均衡中的一致性hash,redis分片集群的底层原理等都有类似的思想;

对应到schema.xml中的核心配置
<!-- 一致性hash -->
<table name="tb_user" dataNode="dn1,dn2,dn3" rule="sharding-by-murmur" /><tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function>核心属性的含义:
- columns : 标识将要分片的表字段
- algorithm: 指定分片函数与function对应关系
- class: 指定该分片算法对应的类
- seed :创建murmur_hash对象的种子,默认0
- count :要分片的数据库节点数量,必须指定,否则没法分片
- virtualBucketTimes: 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍;virtualBucketTimes*count就是虚拟结点数量 ;
- weightMapFile :节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替
- bucketMapPath:用来在测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西;
接下来用一个实际的案例演示下这种分片规则吧
1、创建一个数据表 tb_user
CREATE TABLE tb_user (
id VARCHAR (100) NOT NULL PRIMARY KEY,
user_name VARCHAR (64) NULL
);2、配置schema.xml文件
<schema name="DB02" checkSQLschema="true" sqlMaxLimit="100">
<table name="tb_user" dataNode="dn1,dn2,dn3" primaryKey="id" rule="sharding-by-murmur" />
</schema>
<dataNode name="dn1" dataHost="dhost1" database="dblog" />
<dataNode name="dn2" dataHost="dhost2" database="dblog" />
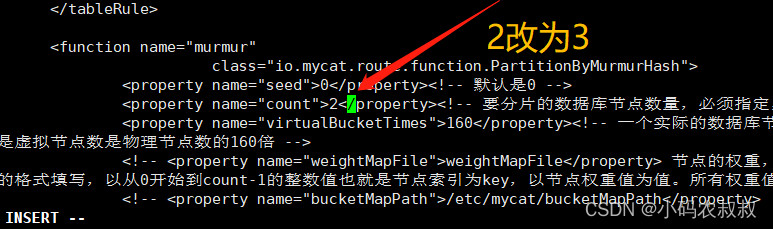
<dataNode name="dn3" dataHost="dhost3" database="dblog" />然后在 rule.xml文件中将2改为3,因为上面配置的是3个数据节点
3、重启mycat服务

4、连接mycat客户端并执行建表sql

创建成功后,确认在3个数据实例节点表是否都已经存在

5、随机插入一些数据
insert into TB_USER(id,user_name) values('a1','jike');
insert into TB_USER(id,user_name) values('e5','jerry');
insert into TB_USER(id,user_name) values('h6','marry');
insert into TB_USER(id,user_name) values('r3','james');
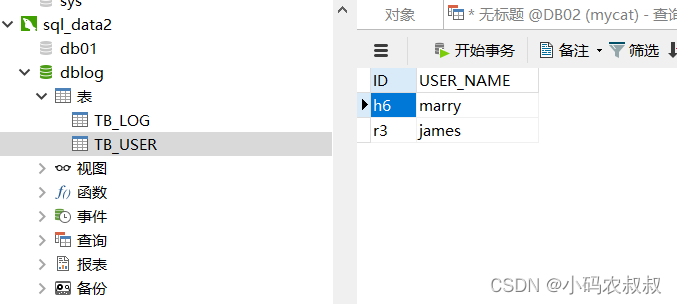
insert into TB_USER(id,user_name) values('s1','john');执行成功后,分布检查各个数据节点的表的数据情况,这就是按照hash之后的分片效果

四、枚举分片
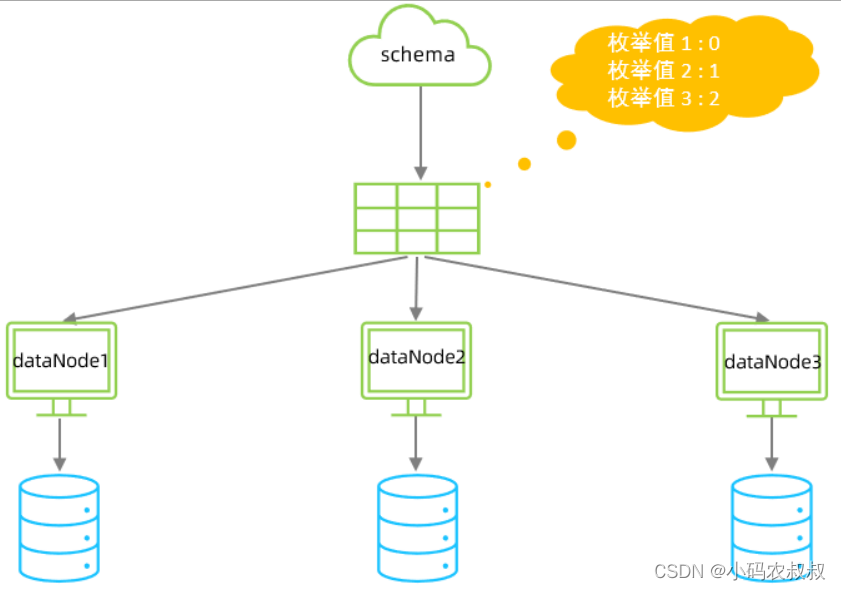
schema.xml文件核心配置
<table name="tb_user" dataNode="dn1,dn2,dn3" rule="sharding-by-intfile-enumstatus" /><tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>在conf目录中,有一个名为 partition-hash-int.txt 的文件,即默认的枚举分片规则文件,不妨打开看看,当然在具体的业务表中,需要结合自己的表的枚举值进行重新定义配置;

分片规则属性说明
- columns : 标识将要分片的表字段
- algorithm :指定分片函数与function的对应关系
- class : 指定该分片算法对应的类
- mapFile: 对应的外部配置文件
- type :默认值为0 ; 0 表示Integer , 1 表示String
- defaultNode: 默认节点 ; 小于0 标识不设置默认节点 , 大于等于0代表设置默认节点 ;
默认节点的所用:枚举分片时,如果碰到不识别的枚举值, 就让它路由到默认节点 ; 如果没有默认值,碰到不识别的则报错
接下来用一个实际的案例演示下这种分片规则吧
1、准备一张表,建表sql如下
CREATE TABLE `tb_user` (
`id` bigint(20) NOT NULL,
`username` varchar(100) NOT NULL,
`status` int(2) DEFAULT 1 COMMENT '1:启用, 2:停用, 3:锁定',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;2、schema.xml 核心配置
关键地方就是rule 配置的规则为 sharding-by-intfile
<schema name="DB02" checkSQLschema="true" sqlMaxLimit="100">
<table name="tb_user" dataNode="dn1,dn2,dn3" primaryKey="id" rule="sharding-by-intfile" />
</schema>
3、rule.xml文件配置
将table 标签中的 <columns>status</columns> 里面的字段改为自身表的枚举字段即可

<tableRule name="sharding-by-intfile">
<rule>
<columns>status</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>4、partition-hash-int.txt 修改
该文件中配置的是默认的,需要根据实际情况进行调整

5、重启mycat服务并连接mycat客户端执行sql建表


6、插入几条sql,观察数据在各个实例上的分布情况
insert into TB_USER(id,username,`status`) values(1,'jerry',1);
insert into TB_USER(id,username,`status`) values(2,'jike',2);
insert into TB_USER(id,username,`status`) values(3,'mike',3);
insert into TB_USER(id,username,`status`) values(5,'john',1);执行成功后,可以看到数据是按照预期的分片分布的

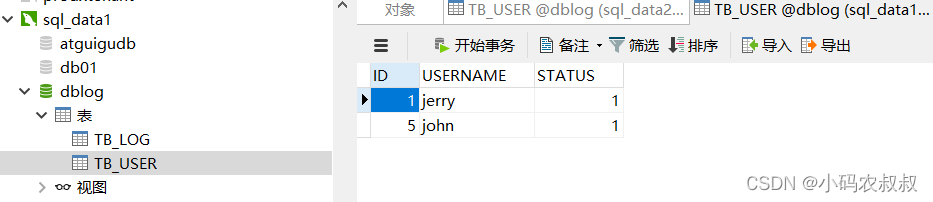
五、应用指定分片
当表设计之初,表的某个字段带有特殊的前缀或后缀标识,或字段值具有比较明显的业务特征,这种情况下,可以考虑使用应用指定分片这种规则;
具体来说,就是在运行阶段由应用自主决定路由到那个分片 , 直接根据字符子串(必须前缀须包含数字)计算分片号;
比如这样的字段值:001-00001,002-00001 ......
其对应到schema.xml文件中的示意图如下

核心的分片规则相关配置如下,包括 schema.xml文件和rule.xml文件

规则属性说明
- columns :标识将要分片的表字段
- algorithm :指定分片函数与function的对应关系
- class :指定该分片算法对应的类
- startIndex :字符子串起始索引
- size :字符长度
- partitionCount: 分区(分片)数量
- defaultPartition :默认分片(在分片数量定义时, 字符标示的分片编号不在分片数量内时,使用默认分片)
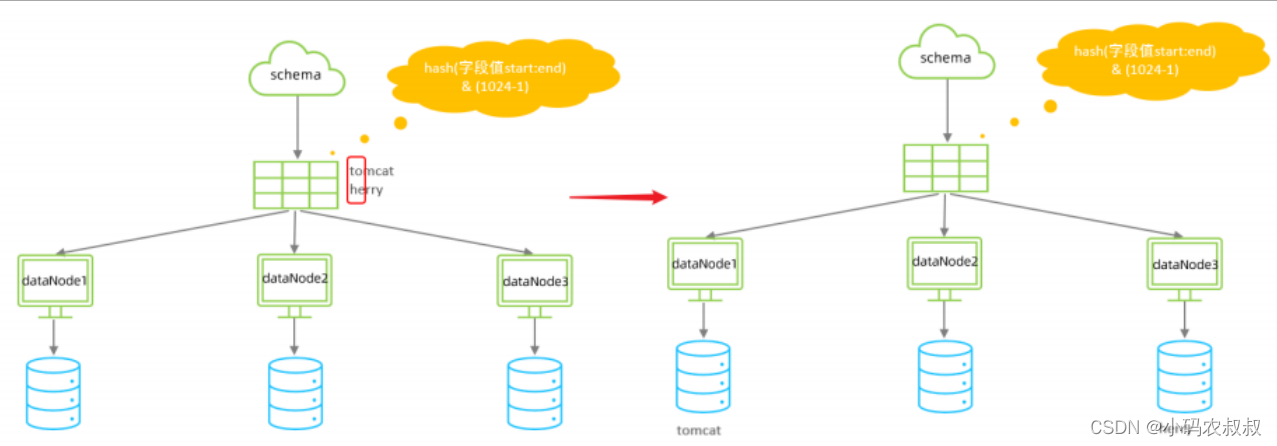
六、固定hash分片
与上面的一致性hash算法不同的是,一致性hash分片规则类似于十进制求模运算,但固定hash分片为二进制的操作;
例如,取 id 的二进制低 10 位 与 1111111111 进行位 & 运算,位与运算最小值为 0000000000,最大值为1111111111,转换为十 进制,也就是位于0-1023之间。

这种分片的特点是:
-
如果是求模,并且是连续的值,将分别分配到各个不同的分片,但该算法会将连续的值可能分配到相同的 分片,降低事务处理的难度。(多个节点同时操作事务的情况)
-
可以均匀分配,也可以非均匀分配
-
分片字段必须为数字类型
核心的分片规则相关配置如下,包括 schema.xml文件和rule.xml文件

配置属性说明:
- columns 标识将要分片的表字段名
- algorithm 指定分片函数与function的对应关系
- class 指定该分片算法对应的类
- partitionCount 分片个数列表
- partitionLength 分片范围列表
补充说明:
- 分片长度 : 默认最大2^10 , 为 1024 ;
- count, length的数组长度必须是一致的 ;
七、字符串hash解析算法分片

- columns :标识将要分片的表字段
- algorithm :指定分片函数与function的对应关系
- class :指定该分片算法对应的类
- partitionLength hash :求模基数 ; length*count=1024 (出于性能考虑)
- partitionCount :分区数
- hashSlice hash :运算位 , 根据子字符串的hash运算 ; 0 代表 str.length(), -1 代表 str.length()-1 , 大于0只代表数字自身 ; 可以理解为substring(start,end),start为0则只表示0
七、按天分片
在某些业务场景下,业务表的数据呈现出很强的时间周期的特性,比如一张日志表,一张订单统计表,表中都可以按照时间标准进行区分,这种情况下,可以考虑使用时间分片规则,具体来说,时间分片的规则,mycat提供了按天分片以及按月进行分片两种方式;
以按天进行分片规则为例进行说明,在这种分片规则下,以时间区间为标准进行划分,比如 1~10 号落到第一个分片,11~20号落到第二个分片,21~30号落到第三个分片;
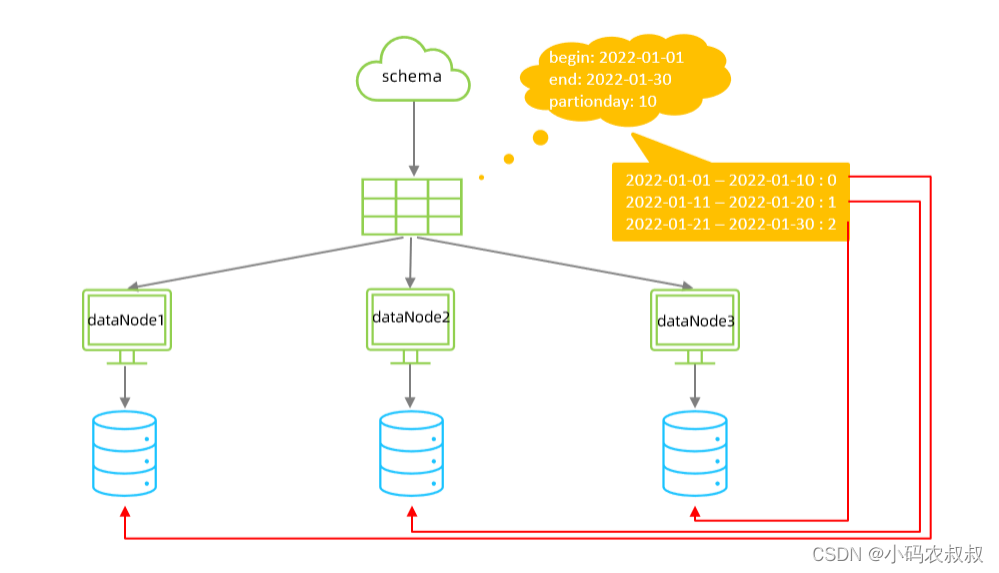
- columns :标识将要分片的表字段
- algorithm :指定分片函数与function的对应关系
- class :指定该分片算法对应的类
- dateFormat : 日期格式
- sBeginDate :开始日期
- sEndDate :结束日期,如果配置了结束日期,则代码数据到达了这个日期的分片后,会重复从开始分片插入
- sPartionDay :分区天数,默认值 10 ,从开始日期算起,每个10天一个分区
CREATE TABLE tb_log (
id BIGINT NOT NULL COMMENT 'ID' PRIMARY KEY,
detail VARCHAR (100) NULL COMMENT '详情',
create_time date NULL
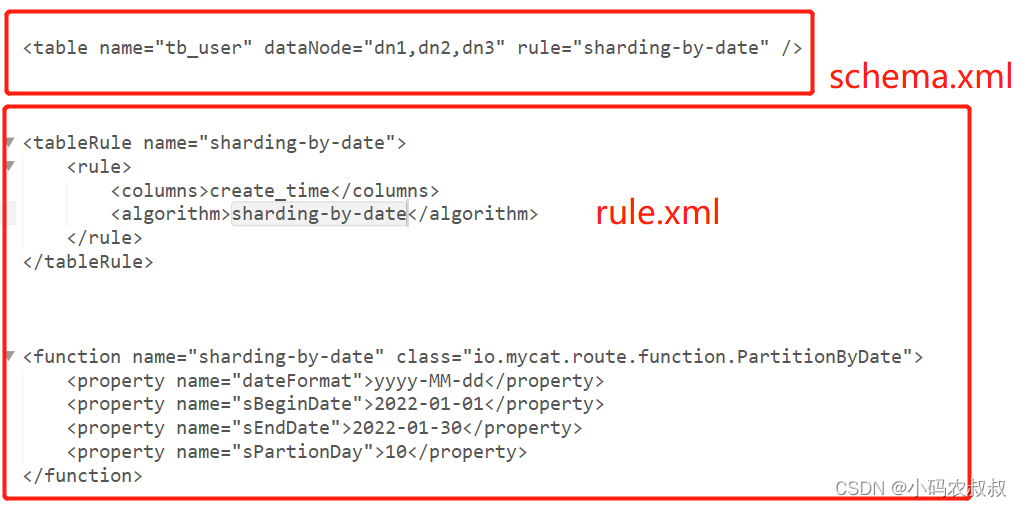
);2、修改schema.xml配置
<schema name="DB02" checkSQLschema="true" sqlMaxLimit="100">
<table name="tb_log" dataNode="dn1,dn2,dn3" primaryKey="id" rule="sharding-by-date" />
</schema>3、修改rule.xml配置
<tableRule name="sharding-by-date">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-date</algorithm>
</rule>
</tableRule>
<function name="sharding-by-date" class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2022-01-01</property>
<property name="sEndDate">2022-01-30</property>
<property name="sPartionDay">10</property>
</function>分片规则属性配置说明:
- columns :标识将要分片的表字段
- algorithm :指定分片函数与function的对应关系
- class :指定该分片算法对应的类
- dateFormat : 日期格式
- sBeginDate :开始日期
- sEndDate :结束日期,如果配置了结束日期,则代码数据到达了这个日期的分片后,会重复从开始分片插入
- sPartionDay :分区天数,默认值 10 ,从开始日期算起,每个10天一个分区
注意点:这种分片规则下,起始时间和结束之间总的时间,除以间隔的时间数量,要和实际的数据节点数量保持一致
4、连接mycat客户端并执行创建表语句
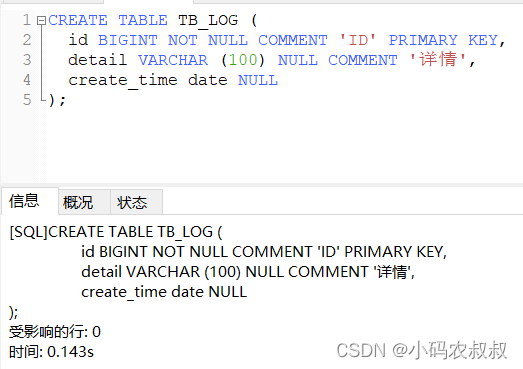
5、随机插入一些数据,观察数据的分布情况
insert into TB_LOG(id,detail ,create_time) values(1,'save','2022-01-01');
insert into TB_LOG(id,detail ,create_time) values(2,'delete','2022-01-09');
insert into TB_LOG(id,detail ,create_time) values(3,'update','2022-01-15');
insert into TB_LOG(id,detail ,create_time) values(5,'query','2022-01-18');
insert into TB_LOG(id,detail ,create_time) values(7,'update','2022-01-21');
insert into TB_LOG(id,detail ,create_time) values(9,'save','2022-01-23');执行成功后,通过3个节点的表的数据分布情况可以发现,达到了预期的分片规则的目的
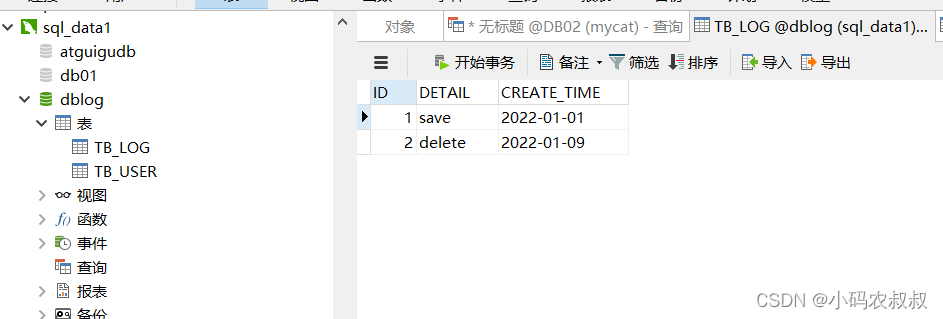
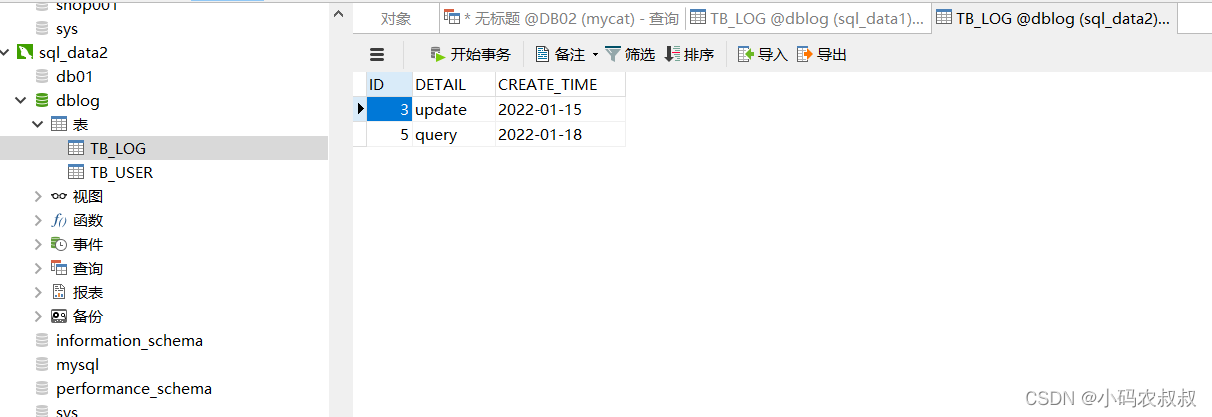
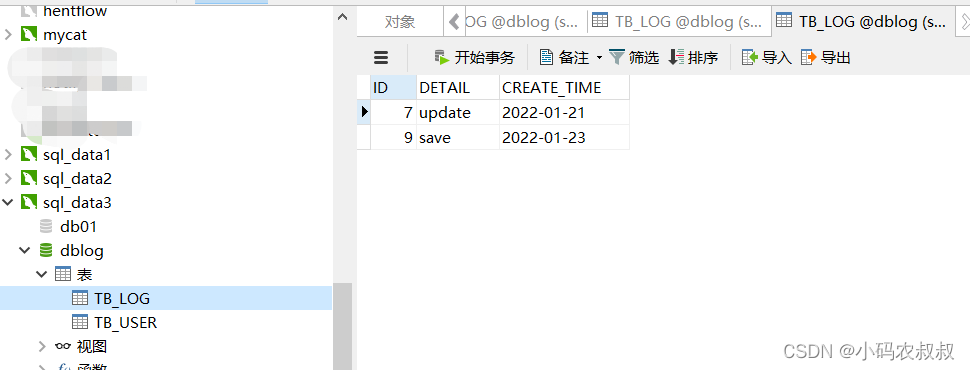
八、按自然月分片
在某些场景下,如果业务数据表的数据呈现出按照月份能够进行很好的划分的话,采用这种分片规则也是一种不错的选择,在这种情况下,每个自然月为一个分片;
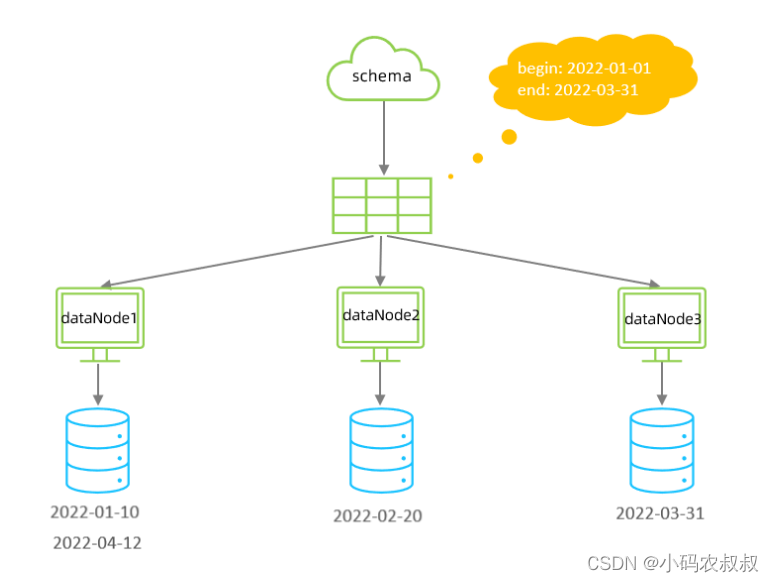
核心的分片规则相关配置如下,包括 schema.xml文件和rule.xml文件

分片规则属性配置说明:
- columns :标识将要分片的表字段
- algorithm :指定分片函数与function的对应关系
- class :指定该分片算法对应的类
- dateFormat :日期格式
- sBeginDate :开始日期
- sEndDate :结束日期,如果配置了结束日期,则代码数据到达了这个日期的分片后,会重复从开始分片插入
本篇详细介绍了mycat常用的分片规则,篇幅较长,实际在使用过程中,可以结合自身的业务情况合理选择某种具体的分片规则进行使用,本篇到此结束,最后感谢观看!