1、RDD基础
Spark中的RDD就是一个不可变的分布式对象集合。每个RDD都被分为多个分区,这些分区运行在分区的不同节点上。
用户可以通过两种方式创建RDD:
(1)读取外部数据集====》 sc.textFile(inputfile)
(2)驱动器程序中对一个集合进行并行化===》sc.parallelize(List(“pandas”,”I like pandas”))
2、RDD操作
转化(Transformations)和行动*(Actions)操作
(1):转化操作
RDD 经过转化返回一个新的RDD,转化出来的RDD是惰性求值的,只有在行动操作才会进行计算的。
常见的转换操作如下图:
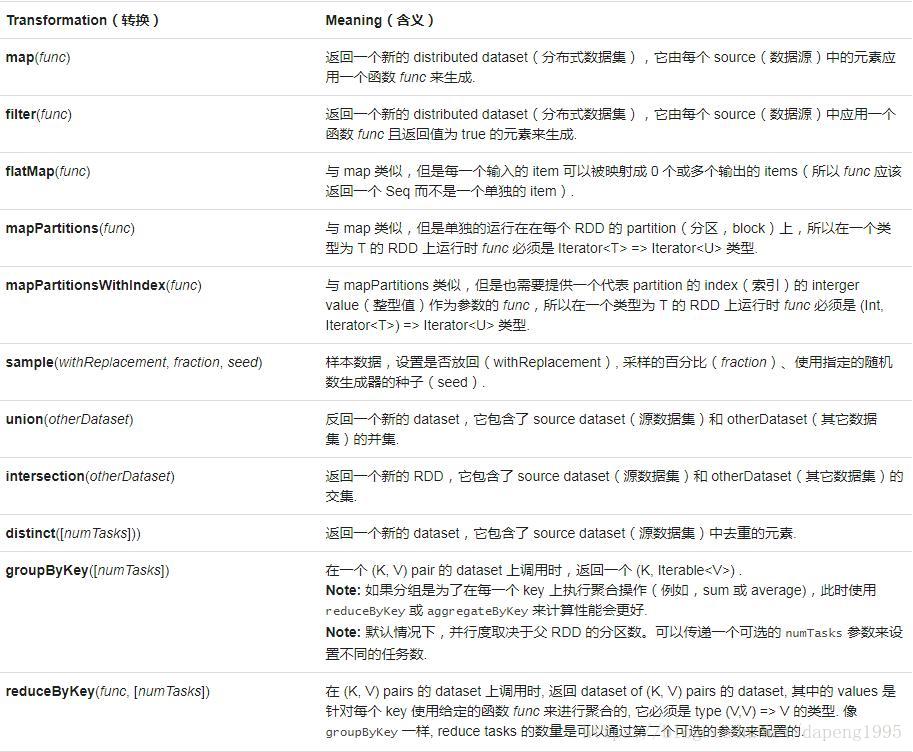
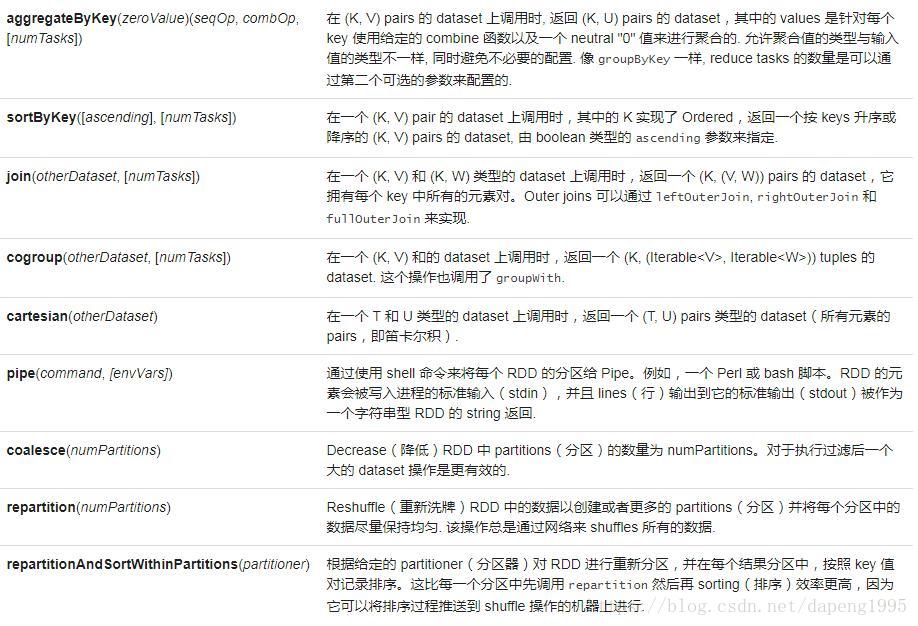
(2):行动操作
对数据集进行实际的计算,这最终求得的结果返回驱动器程序中,或者写入外部程序中。
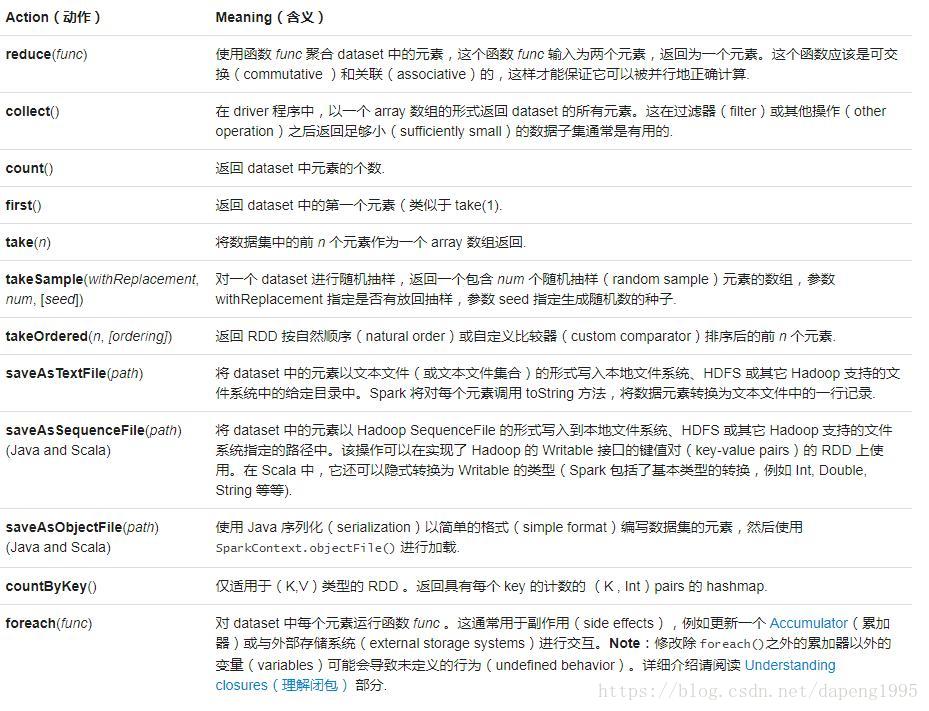
下表列出了一些 Spark 常用的 actions 操作
简单worldcount操作实现
object WordCountScala {
def main(args: Array[String]): Unit = {
//创建Spark配置对象
val conf = new SparkConf();
conf.setAppName("WordCountScala")
//设置master属性
//conf.setMaster("local");
conf.setMaster("local[*]")
//通过conf创建sc
val sc = new SparkContext(conf);
print("hello world");
//加载文本文件
val rdd1 = sc.textFile("F:/spark/b.txt");
//压扁
val rdd2 = rdd1.flatMap(line => {
println("map :"+line)
line.split(" ")
}) ;
//映射w => (w,1)
val rdd3 = rdd2.map(word=>{
println("map :"+word)
(word,1)
})
val rdd4 = rdd3.reduceByKey(_ + _)
val r = rdd4.collect()
r.foreach(println)
}
}3、RDD的持久化
因为Spark RDD是惰性求值的,有时候我们希望能够多次使用同一个RDD。如果简单的对RDD调用行动操作,Spark会重算RDD以及它的所有的依赖。造成算法的开销很大。处于不同的目的,我们可以为RDD选择不同的持久化级别。RDD 可以使用 persist() 方法或 cache() 方法进行持久化。数据将会在第一次 action 操作时进行计算,并缓存在节点的内存中。Spark 的缓存具有容错机制,如果一个缓存的 RDD 的某个分区丢失了,Spark 将按照原来的计算过程,自动重新计算并进行缓存。默认的存储级别是 StorageLevel.MEMORY_ONLY(将反序列化的对象存储到内存中) ,如果您想手动删除 RDD 而不是等待它掉出缓存,使用 RDD.unpersist() 方法。

例如: Scala中的两次执行
val result=input.map(x=>x*x)
result.persist(StorageLevel.DISK_ONLY)
println(result.count())
println(result.collect().mkString(","))