文章目录
Katiyar, A. and C. Cardie (2017). Going out on a limb: Joint extraction of entity mentions and relations without dependency trees. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).
abstract
提出了一种新的基于注意的递归神经网络,用于联合提取实体提及度和关系。我们证明了注意力和长短时记忆(LSTM)网络可以在不访问依赖树的情况下提取实体提及之间的语义关系。在自动内容提取(ACE)语料库上的实验表明,我们的模型显著优于Li和Ji(2014)基于特征的联合模型。我们还将我们的模型与Miwa和Bansal(2016)的基于端到端树的LSTM模型(SPTree)进行了比较,结果表明我们的模型在实体提及率1%和关系率2%的范围内运行。我们的细粒度分析还表明,我们的模型在代理工件关系上表现得更好,而SPTree在物理和部分整体关系上表现得更好。
- 一种新的基于注意的递归神经网络
- l联合抽取
- 无依赖树
1. Introduction
- 联合模型的性能优于管道模型,因为类型化关系的知识可以增加模型对实体提取的信心,反之亦然
递归网络(RNNs) (Elman, 1990)最近成为非常流行的序列标记任务,如涉及一组连续令牌的实体提取。然而,它们识别序列中不相邻的标记(如两个实体的头名词)之间关系的能力却很少被研究。对于这些任务,使用树结构的rns被认为是更合适的。例如,Miwa和Bansal(2016)提出了一个由基于序列的长短时记忆(LSTM)和一个独立的基于树的依赖LSTM层组成的RNN来进行实体识别,并使用两个组件之间的共享参数进行关系分类。因此,他们的模型严重依赖于对依赖树的访问,将其限制在句子层次提取和存在(好的)依赖解析器的语言。而且,他们的模型并不共同提取实体和关系;它们首先提取所有实体,然后对句子中所有对实体进行关系分类。
- 不相邻的标记之间的关系—用树结构的RNNs
在我们之前的工作(Katiyar和Cardie, 2016)中,我们在意见提取上下文中处理了相同的任务。我们基于lstm的公式明确地将实体头部之间的距离编码为意见关系标签。我们的模型的输出空间是实体和关系标签集大小的平方,我们没有明确地标识关系类型。不幸的是,添加关系类型使得输出标签空间非常稀疏,使得模型很难学习。
- 本文:a novel RNN-based model,无树
与其他模型不同,我们的模型不依赖于任何依赖树信息。我们的基于rnn的模型是一个序列上的多层双向LSTM。我们从左到右对输出序列进行编码。在每个时间步上,我们在前面解码的时间步上使用一个类似于注意的模型,来标识与当前令牌具有指定关系的令牌。我们还在网络中添加了一个额外的层来对从右到左的输出序列进行编码,并发现使用双向编码对关系识别的性能有了显著的改进。
我们的模型显著优于Li和Ji(2014)的基于特征的结构化感知器模型,在ACE05数据集的实体和关系提取上都有了改进。与Miwa和Bansal(2016)的基于依赖树的LSTM模型相比,我们的模型对ACE05数据集的实体和关系的处理效率分别为1%和2%。我们还发现,我们的模型在AGENT-ARTIFACT关系上的表现明显好于基于树的模型,而他们的基于树的模型在物理和部分-整体关系上的表现更好;这两个模型在所有其他关系类型上的表现是比较的。我们的非树模型极具竞争力的性能对于在缺乏良好解析器的低资源语言中提取非相邻实体的关系来说是个好兆头。
2. 相关工作
RNNs (Hochreiter and Schmidhuber, 1997)最近被应用于许多顺序建模和预测任务,如机器翻译(Bahdanau et al., 2015;Sutskever等,2014),命名实体识别(NER) (Hammerton, 2003),意见挖掘(Irsoy and Cardie, 2014)。已经发现,在LSTMs上添加crf样目标等变体可以在多个序列预测NLP任务中产生最新的结果(Collobert et al., 2011;黄等,2015;Katiyar和Cardie, 2016)。这些模型在输出层假设条件独立,我们不假设条件独立在输出层,允许它对输出序列上的任意分布建模。
- RNN+crf–效果更好
- 以前都假设条件独立,我们不假设输出层条件独立,允许它对输出序列上的任意分布建模。
关系分类作为一个独立的任务被广泛研究,假设关系的参数是预先知道的。已经提出了几种模型,包括基于特征的模型(Bunescu和Mooney, 2005;和基于神经网络的模型(Socher et al., 2012;dos Santos等人,2015;桥本等人,2015;徐等,2015a,b)。
联合提取实体和关系,基于特征的结构化预测模型(Li and Ji, 2014;Miwa和Sasaki, 2014),联合推理整数线性规划模型(Yih和Roth, 2007;Yang和Cardie, 2013),卡片金字塔解析(Kate和Mooney, 2010)和概率图形模型(Yu和Lam, 2010;(Singh et al., 2013)已经被提出。与此相反,我们提出了一种不依赖于诸如词性(POS)标签、依赖树等任何特征的可用性的神经网络模型。
- 本文:我们提出了一种不依赖于诸如词性(POS)标签、依赖树等任何特征的可用性的神经网络模型
最近,Miwa和Bansal(2016)提出了一种基于端到端的LSTM序列和树结构模型。它们通过序列层提取实体,通过最短路径依赖树网络提取实体之间的关系。在本文中,我们尝试研究递归神经网络,在不使用任何依赖解析树特征的情况下提取实体提及之间的语义关系。我们还提出了第一个基于神经网络的联合模型,该模型可以提取实体提及和关系以及关系类型。在我们之前的工作(Katiyar和Cardie, 2016)中,如前所述,我们提出了一个基于lstm的模型来联合提取意见实体和关系,但是没有关联类型。由于输出空间变得稀疏,使得模型难以学习,因此不能直接扩展该模型以包含关系类型。
递归神经网络的最新进展是将注意力应用于递归神经网络,以获得序列模型中令牌的重要性加权的表示。这些模型在问答任务中被频繁使用(最近的例子见Chen et al.(2016)和Lee et al.(2016)),机器翻译(Luong et al., 2015;以及许多其他NLP应用。指针网络(Vinyals et al., 2015)是注意力模型的一种适应,使用这些标记级权重作为指向输入元素的指针。例如,Zhai et al.(2017)将这些用于神经分块,Nallapati et al.(2016)和Cheng and Lapata(2016)用于总结。然而,就我们所知,这些网络还没有被用来联合提取实体提及和关系。我们首先尝试使用这些带有递归神经网络的注意模型来联合提取实体提及和关系。
3. Model
该模型由一个多层的双向递归网络构成,它学习序列中每个令牌的表示。我们使用来自顶层的隐藏表示来进行联合实体和关系提取。对于序列中的每个标记,我们输出一个实体标记和一个关系标记。实体标记对应于实体类型,而关系标记是指向相关实体及其各自关系类型的指针的元组。图1显示了来自数据集的一个示例句子的注释。我们将关系标记从实体级转换为令牌级。例如,我们为独立电视新闻实体中的每个令牌分别建模关系ORG-AFF。因此,我们分别模拟ITV和Martin Geissler, News和Martin Geissler之间的关系。为了找到每个令牌的关系标记,我们在序列层的顶部使用了一个类似指针的网络,如图2所示。在每个时间步骤中,网络利用前一个时间步骤中所有输出标记的可用信息来联合输出当前令牌的实体标记和关系标记。
- 多层,双向RNN
- 学习序列每个token的表示,然后用这个来进行联合实体和关系抽取
- 为了找到每个token的关系标记
- 使用类似指针的网络
3.1 Multi-layer Bi-directional Recurrent Network
- 多层LSTMs,双向
- 我们使用多层双向lstm进行序列标记,因为lstm更能够捕获令牌之间的长期依赖关系,这使得它非常适合实体提及和关系抽取。
-
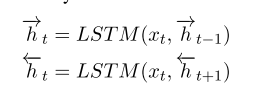
- 最终的隐层表示

3.2实体检测
- BILOU,序列标注任务
- —找到最有可能的输出标签
我们的网络结构如图2所示,也包含了从前一个时间步骤的输出yt-1到当前顶层隐藏层的连接。因此,我们的产出并不是有条件地相互独立的。为了添加来自yt-1的连接,我们将这个输出k转换为一个嵌入 的标签。(我们还可以使用前一个时间步骤的关系标签输出来添加关系标签嵌入。)我们表示每种标签类型k用一个密度表示

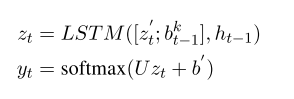
- 我们用贪婪的方式从左向右来解码输出序列
3.3 attention model
- 关系抽取:attention model
我们使用注意模型进行关系提取。注意模型,在一个编码序列的表示z上,可以在这些学习的表示上计算一个软概率分布p,其中di是解码序列中的第i个标记。这些概率表示编码器序列中不同令牌的重要性:
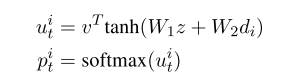
- v是attention scores
- v是注意力的权重矩阵,它将隐藏的表征转化为注意力得分。
我们在我们的方法中使用了指针网络(Vinyals等人,2015),这是这些注意力模型的变体。指针网络将这些pi t解释为指向输入t的指针,表示在输入编码序列上的概率分布,并使用ui元素。我们可以使用这些指针来对当前令牌和之前预测的令牌之间的关系进行编码,使其适合于关系提取,如3.4节所述。
3.4 关系检测

- 看做序列标注任务
我们还将关系提取描述为一个序列标记任务。对于每个令牌,我们希望找到与当前令牌相关的过去令牌及其关系类型。在图1中,“Safwan”通过关系类型“PHYS”与令牌“Martin”以及“Geissler”相关联。为简单起见,我们假设只有一个以前的令牌与当前的令牌在训练时相关,即,“Safwan”和“Geissler”是通过物理关系联系在一起的。我们可以扩展我们的方法来输出多个关系,如第4节所述。
使用3.3的pointer network。在每个时间步,我们堆栈顶部隐藏层表示从以前的时间步骤z<= t 及其相应的标签嵌入b<= t。我们只压栈顶部的令牌被预测为隐层表示non-O‘s之前的时间步骤如图2所示。我们在t时刻的译码表示是zt和bt的拼接,注意概率可以计算如下
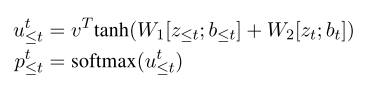
- p对应到目前为止序列中每个令牌在第t步与当前令牌相关的概率。对于没有关系的情况,t时刻的令牌与自身相关。
我们还想找出关系的类型。为了实现这一点,我们向v添加了一个额外的维度,该维度与关系类型R空间的大小相对应。因此,ui t不再是一个分数,而是一个R维向量。然后我们对这个大小为O(|z≤t|×R)的向量取softmax,以找到指向相关实体及其关系类型的最可能的指针元组。
3.5双向编码
- biLSTMs比单向更好地获取上下文
- –>在输出层双向编码
- bi-LSTM+另一个隐层,对从右到左的输出序列编码–>实体标记和关系标记
基于它们在各种NLP任务上的性能(Irsoy和Cardie, 2014),双向lstm被发现能够比普通的从左到右lstm更好地捕获上下文。此外,Sutskever等(2014)发现,在训练过程中,他们在机器翻译任务中的表现随着输入句子的倒排而提高。受这些开发的启发,我们在输出层试验了双向编码。我们在图2的Bi-LSTM上添加了另一个顶层隐藏层,它对从右到左的输出序列进行编码。除了顶层隐藏层外,这两种编码共享相同的多层双向LSTM。因此,我们的网络中有两个输出层,分别输出实体标记和关系标记。在推理时,我们使用启发式来合并两个方向的输出。
4.训练
我们通过最大化正确实体E和关系R标签序列的logprobability来训练我们的网络
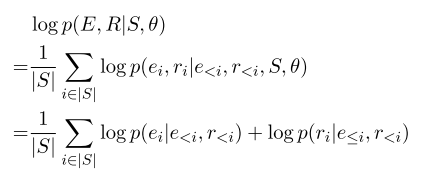
我们可以将目标分解为实体序列和关系序列的对数概率和。我们在培训时使用黄金实体标签。如图2所示,在当前时间步长中,我们将之前的时间步长嵌入到顶层隐藏层的标签与其他循环输入一起输入。在训练过程中,我们将金标签嵌入到下一个时间步中,这使得我们的模型能够得到更好的训练。但是,在测试时,当gold标签不可用时,我们使用先前时间步骤的预测标签作为当前步骤的输入。
因为,我们添加了另一个顶层,按照章节3.5中解释的相反顺序对标记序列进行编码,所以输出中可能会有冲突。我们选择了与Miwa和Bansal(2016)类似的积极和更自信的标签。
- 贪婪解码
我们提取关系的方法不同于Miwa和Bansal(2016)。Miwa和Bansal(2016)将每一对实体提交到其关系分类模型中。在我们的方法中,我们使用指针网络来标识相关实体。因此,对于目前所描述的方法,如果我们只计算目标上的argmax,那么我们将模型限制为每个标记只输出一个关系标签。但是,从我们对数据集的分析来看,一个实体可能与句子中的多个实体相关。因此,我们修改目标以包含多个关系。在图2中,令牌Safwan与实体Martin Geissler的令牌Martin和Geissler都相关,因此我们将概率赋值为0.5送给这两个token。这可以很容易地扩展为包含来自其他相关实体的令牌,这样我们就可以分配相等的概率1/N到所有tokens.取决于这些相关令牌的数量N。
-
实体部分的log-probability与我们在第4节中讨论的目标相同,但是我们将关系log-probability修改如下
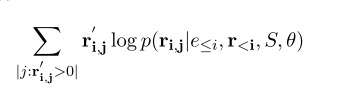
-
ri’系数,因此使用交叉熵目标函数
-
我们也可以使用Sparsemax (Martins and Astudillo, 2016)来代替softmax,后者更适合于稀疏分布。然而,我们把它留给未来的工作。
-
在推理时,我们输出所有概率值超过一定阈值的标签。我们根据验证集调整这个阈值。
5.实验
5.2 evaluation metrics
为了将我们的系统与之前的系统进行比较,我们报告了与Li和Ji(2014)以及Miwa和Bansal(2016)类似的实体和关系的微观f1分数、精确度和召回率。如果我们能正确识别实体的头部和实体类型,则认为实体是正确的。如果我们能够识别参数实体的头部和关系类型,则关系被认为是正确的。当参数实体和关系都正确时,我们也报告一个合并的分数。
5.3 基线和以前的模型
我们将我们的方法与前面的两种方法进行比较。Li和Ji(2014)提出的模型是一种基于特征的结构化感知器模型,具有高效的波束搜索。他们使用基于分段的译码器而不是基于符号的译码器。他们的模型比之前最先进的流水线模型要好。Miwa和Sasaki (2014) (SPTree)最近提出了一个基于lstm的模型,其中包含一个用于实体识别的序列层,以及一个基于树的依赖层,该依赖层使用候选实体之间的最短依赖路径来识别候选实体对之间的关系。我们还使用了之前的方法(Katiyar和Cardie, 2016)来提取意见实体和与此任务的关系。我们发现,与上面提到的两种方法相比,这种方法的性能并不具有竞争力,在关系上的性能降低了10个百分点。因此,我们不包括表1中的结果。Li和Ji(2014)也表明,联合模型的性能优于流水线方法。因此,我们不包括任何管道基线。
5.4 超参数
使用300维word2vec (Mikolov et al., 2013)对谷歌新闻数据集进行单词嵌入训练。我们的网络中有3个隐藏层,隐藏单元的维度是100。网络中的所有权值都是由小的随机均匀噪声初始化的。我们基于ACE05开发集调整超参数,并使用它们对ACE04数据集进行培训。
6.结果
- 我们的联合模型在实体和关系上都显著优于联合结构化感知器模型(Li和Ji, 2014),尽管还缺乏依赖树、POS标签等特性。然而,如果我们将我们的模型与SPTree模型进行比较,我们会发现它们的模型在实体和关系上有更好的回忆。
- 我们发现将目标修改为包含多个关系可以提高系统对关系的回忆,从而略微提高系统的整体性能。但是,仔细调整阈值可以进一步提高精度。
- 双向编码很有用。
