(一)远程监督的思想
这篇论文首先回顾了关系抽取的监督学习、无监督学习和Bootstrapping算法的优缺点,进而结合监督学习和Bootstrapping的优点,提出了用远程监督做关系抽取的算法。
远程监督算法有一个非常重要的假设:对于一个已有的知识图谱(论文用的Freebase)中的一个三元组(由一对实体和一个关系构成),假设外部文档库(论文用的Wikipedia)中任何包含这对实体的句子,在一定程度上都反映了这种关系。基于这个假设,远程监督算法可以基于一个标注好的小型知识图谱,给外部文档库中的句子标注关系标签,相当于做了样本的自动标注,因此是一种半监督的算法。
具体来说,在训练阶段,用命名实体识别工具,把训练语料库中句子的实体识别出来。如果多个句子包含了两个特定实体,而且这两个实体是Freebase中的实体对(对应有一种关系),那么基于远程监督的假设,认为这些句子都表达了这种关系。于是从这几个句子中提取文本特征,拼接成一个向量,作为这种关系的一个样本的特征向量,用于训练分类器。
论文中把Freebase的数据进行了处理,筛选出了94万个实体、102种关系和180万实体对。下面是实体对数量最多的23种关系。
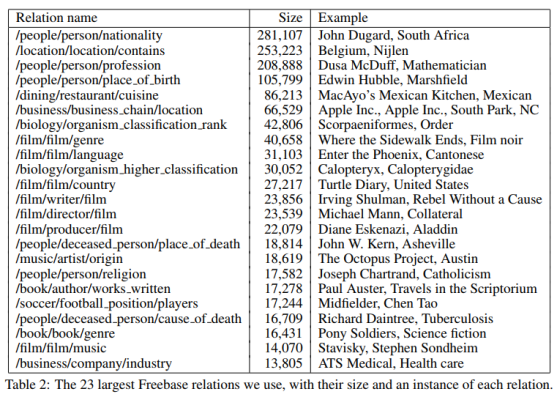
关系种类相当于分类的类别,那么有102类;每种关系对应的所有实体对就是样本;从Wikipedia中所有包含某实体对的句子中抽取特征,拼接成这个样本的特征向量。最后训练LR多分类器,用One-vs-Rest,而不是softmax,也就是训练102个LR二分类器——把某种关系视为正类,把其他所有的关系视为负类。
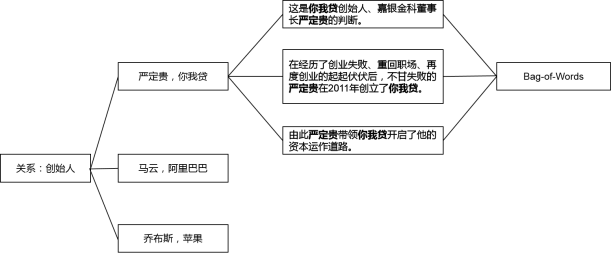
因为远程监督算法可以使用大量无标签的数据,Freebase中的每一对实体在文档库中可能出现在多个句子中。从多个句子中抽出特征进行拼接,作为某个样本(实体对)的特征向量,有两个好处:
一是单独的某个句子可能仅仅包含了这个实体对,并没有表达Freebase中的关系,那么综合多个句子的信息,就可以消除噪音数据的影响。
二是可以从海量无标签的数据中获取更丰富的信息,提高分类器的准确率。
但是问题也来了,这个假设一听就不靠谱!哪能说一个实体对在Freebase中,然后只要句子中出现了这个实体对,就假定关系为Freebase中的这种关系呢?一个实体对之间的关系可能有很多啊,比如马云和阿里巴巴的关系,就有“董事长”、“工作”等关系,哪能断定就是“创始人”的关系呢?
这确实是个大问题,在本篇论文中也没有提出解决办法。
(二)分类器的特征
论文中使用了三种特征:词法特征(Lexical features)、句法特征(Syntactic features)和实体标签特征(Named entity tag features)。
1、词法特征
词法特征描述的是实体对中间或两端的特定词汇相关的信息。比如有:
- 两个实体中间的词语和词性
- 实体1左边的k个词语和词性,k取{0,1,2}
- 实体2右边的k个词语和词性,k取{0,1,2}
然后把这些特征表示成向量再拼接起来。比如用词袋模型,把词语和词性都表示为向量。
2、句法特征
论文中的句法特征就是对句子进行依存句法分析(分析词汇间的依存关系,如并列、从属、递进等),得到一条依存句法路径,再把依存句法路径中的各成分作为向量,拼接起来。
如下为一个句子的依存句法路径,我不太懂,不多说。

3、命名实体标签特征
论文中做命名实体识别用的是斯坦福的NER工具包。把两个实体的标签也作为特征,拼接起来。
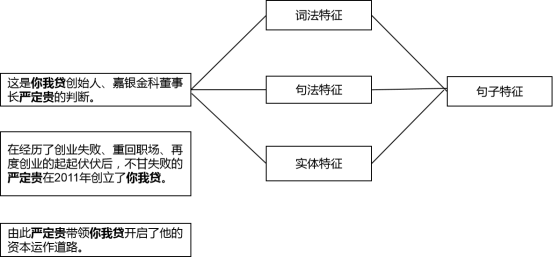
总结一下,论文中使用的特征不是单个特征,而是多种特征拼接起来的。有多个句子包含某实体对,可以从每个句子中抽取出词法特征、句法特征和实体特征,拼接起来,得到一个句子的特征向量,最后把多个句子的特征向量再拼接起来,得到某实体对(一个样本)的特征向量。
不过作者为了比较词法特征和句法特征的有效性,把特征向量分为了3种情况:只使用词法特征,只使用句法特征,词法特征与句法特征拼接。

(三)实验细节
1、数据集说明
知识图谱或者说标注数据为Freebase,非结构化文本库则是Wikipedia中的文章。
论文中把Freebase的三元组进行了筛选,筛选出了94万个实体、102种关系和相应的180万实体对。用留出法进行自动模型评估时,一半的实体对用于训练,一半的实体对用于模型评估。
同样对Wikipedia中的文章进行筛选,得到了180万篇文章,平均每篇文章包含约14.3个句子。从中选择80万条句子作为训练集,40万条作为测试集。
2、构造负样本
由于对于每种关系,都要训练一个LR二分类器,所以需要构造负样本。这里的负样本不是其他101种关系的训练样本,而是这样的句子:从训练集中的句子中抽取实体对,如果实体对不在Freebase中,那么就随机挑选这样的句子就作为负样本。
3、训练过程
LR分类器以实体对的特征向量为输入,输出关系名和概率值。每种关系训练一个二分类器,一共训练102个分类器。
训练好分类器后,对测试集中的所有实体对的关系进行预测,并得到概率值。然后对所有实体对按概率值进行降序排列,从中挑选出概率最高的N个实体对(概率值大于0.5),作为发现的新实体对。
4、测试方法和结论
测试的指标采用查准率,方法采用了留出法(自动评估)和人工评估两种方法。留出法的做法是,把Freebase中的180万实体对的一半作为测试集(另一半用于训练)。新发现的N个实体对中,如果有n个实体对在Freebase的测试集中,那么查准率为n/N。人工评估则采用多数投票的方法。
模型评估的结果表明,远程监督是一种较好的关系抽取算法。在文本特征的比较上,词法特征和句法特征拼接而成的特征向量,优于单独使用其中一种特征的情况。此外,句法特征在远程监督中比词法特征更有效,尤其对于依存句法结构比较短而实体对之间的词语非常多的句子。

(四)评价
这篇论文把远程监督的思想引入了关系抽取中,充分利用未标注的非结构化文本,从词法、句法和实体三方面构造特征,最后用留出法和人工校验两种方法进行模型评估,是一种非常完整规范的关系抽取范式。
不足之处有两点:
第一个是前面所提到的问题,那就是远程监督所基于的假设是一个非常强的假设。哪能说一个实体对在Freebase中存在一种关系,那么只要外部语料库中的句子中出现了这个实体对,就假定关系为Freebase中的关系呢?还可能是其他关系啊?
Bootstrapping中也有这个问题,称为语义漂移问题,但Bootstrapping本身通过给新发现的规则模板和实体对打分,在一定程度上缓解了这个问题,而这篇论文并没有提到这个问题,更没有涉及到解决办法。我猜这是因为Freebase中的实体对和关系主要就是从Wikipedia中抽取出来的,而且关系属于比较典型的关系。
这点就成了后续远程监督关系抽取算法的一个改进方向,后面的研究人员提出了利用多实例学习和句子级别的注意力机制来解决这个问题。
第二个是论文中用到了三种特征,貌似一顿操作猛如虎,但实际上构造这些特征非常繁琐,而且词性标注和依存句法分析依赖于NLP工具库,因此工具库在标注和解析中所产生的误差,自然会影响到文本特征的准确性。
这点也是后续研究的一个改进方向,后面的研究人员用神经网络作为特征提取器,代替人工提取的特征,并用词嵌入作为文本特征。