TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking——COLING2020
论文代码链接
解决了什么问题
关系重叠问题
- Normal:两个实体一个关系,正常且普通
- SEO(SingleEntityOverlap):一个实体与其他实体存在关系
- EPO(EntityPairOverlap):一对实体存在多个关系

暴露偏差问题
暴露偏差问题指的是在关系抽取任务中,训练阶段输入的是gold entity(ground truth entity),而在预测阶段是实体识别模型预测的实体。
- 例如基于解码器的方法,在训练时,使用真值token作为上下文。而在推理时,模型生成的前一个token作为上下文输入。
- 基于分解的方法将 gold实体(ground truth entity)作为特定的输入,在训练过程中指导模型提取对象实体和关系,而在推理时,输入的核心实体由模型给出。
导致训练和推理之间存在差距。
TPLinger介绍
基础方法
TPLinker整体标注Tag框架是基于token pair进行的,其本质上就是一个span矩阵。这种方法也可以成为Multi-Head方法。
Multi-Head方法重点在于构建一个==[batch_size, seq_len, seq_len, hidden]==维度的矩阵(后续成为table),相当于每一个token embedding都逐个乘以sequence中的其他token embedding,得到token与其他所有token之间一种交互特征,每一个单元格都可以代表一个token pair,进而通过其他方提取实体关系及关系类型。

提出的标注框架
TPLinker将联合抽取任务转化为Token Pair Linking问题。给定一个句子,两个位置p1,p2和一个特定的关系r,TPLinker回答三个Yes / No伪问题:
" p1和p2分别是否是同一个实体的起点和终点? ",
" p1和p2分别是否是两个具有r关系的实体的起点? ",
" p1和p2分别是否是两个具有r关系的实体的终点? "。
为此设计了一个为每个关系标注3个token链接矩阵的握手标注方案来回答上述3个问题。我们在上述提到的table为基础,构建了如下的标注框架。
- 紫色标注:EH to EH,表示一个实体的头尾。如两个实体:New York City:M(New, City) =1; De Blasio:M(De, Blasio) =1。
- 红色标注:SH to OH,表示subject和object的头部token间的关系。如下图中三元组(New York City, mayor,De Blasio),标注方式就是红色(New, De)=2。
- 蓝色标注:ST to OT,表示subject和object的尾部token间的关系。如下图中三元组(New York City, mayor,De Blasio),标注方式就是蓝色(City, Blasio)=2。
其中的1和2的区别就是关系方向的问题。我们看到在下三角矩阵当中也有1存在,文章为了为防止稀疏计算,下三角矩阵不参与计算;虽然实体标注不会存在于下三角矩阵种,但关系标注是会存在的。如果关系存在于下三角,则将其转置到上三角,并有“标记1”变为“标记2”。
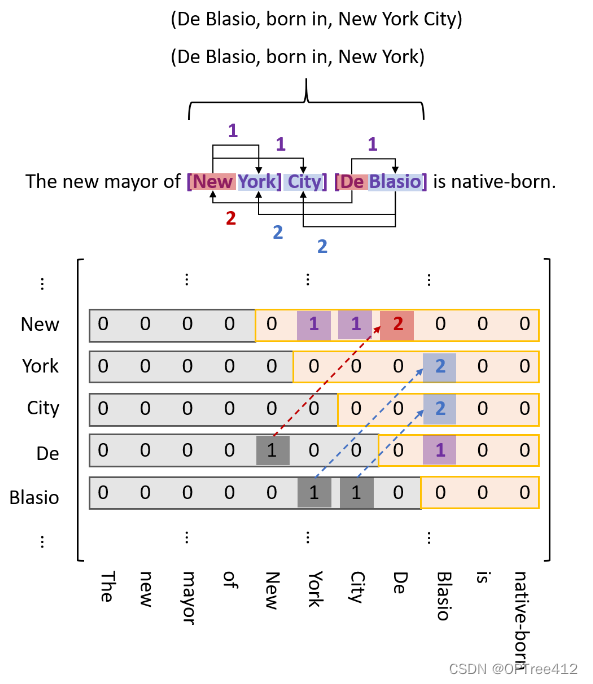
如此已经解决的上面提到的SEO问题了(关系重叠问题当中说了),但是EPO的问题在这里还没有解决,因此论文使用了下面的”硬核“解决办法。
解码过程
在这里联合抽取任务被解构为2N + 1个序列标注子任务,其中N表示预定义关系类型的数量(关系标签个数),每个子任务构n*(n+1)/2的标建一个长度为签序列,其中n为输入句子的长度。
红色为实体对的头,蓝色为实体对的尾,紫色为检测到的实体,1和2代表这对实体关系的方向。
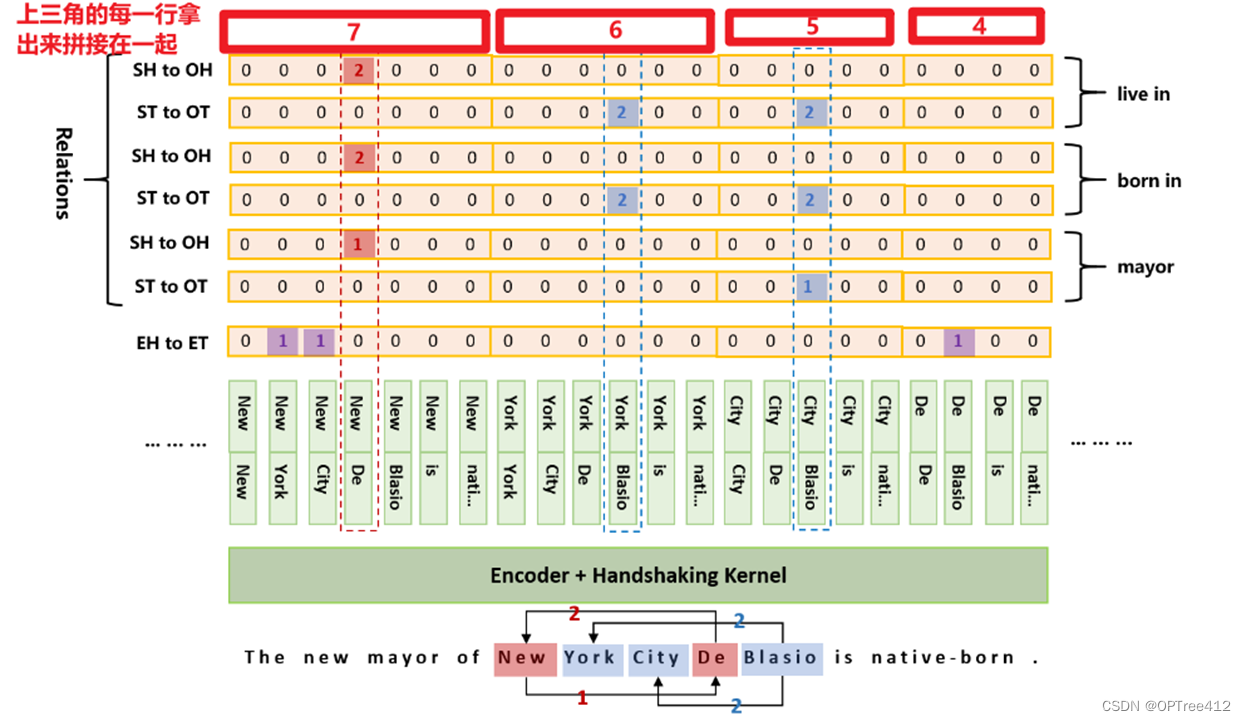
TPLinker的解码过程为:
- 解码EH-to-ET可以得到句子中所有的实体,用实体头token idx作为key,实体作为value,存入字典D中;
- 对每种关系r,解码ST-to-OT得到token对存入集合E中
- 解码SH-to-OH得到token对并在字典D中关联其token idx的实体value;
- 对上一步中得到的SH-to-OH token对的所有实体value对,在集合E中依次查询是否其尾token对在E中,进而可以得到三元组信息。
在这里可以明显地察觉到,TPLinker在遇到存在复杂关系的数据集时会比较费劲。为了解决EPO问题将存在关系的实体对在每个关系标签上都要进行判断,但文章中说的是。。。

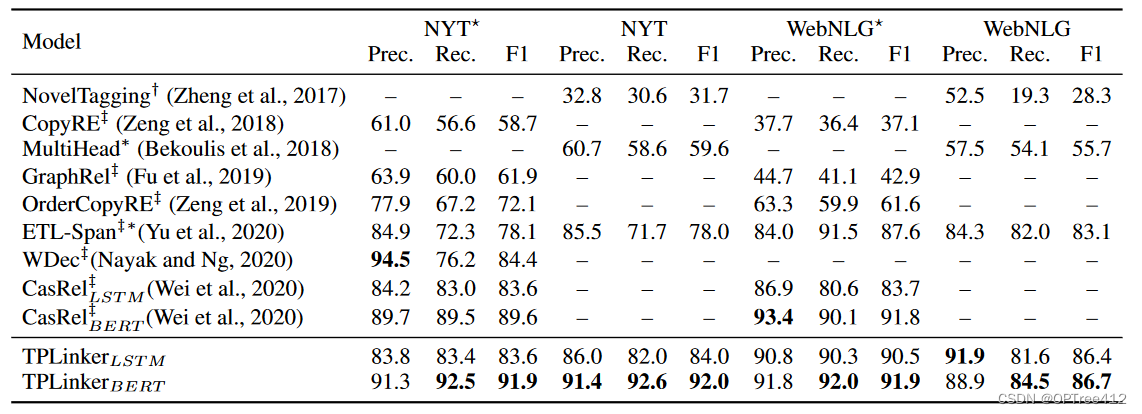
TPLinker的实验结果
总结
优点:
- TPLinker这种one-stage的联合抽取模型解决了暴露偏差和误差传递的问题,同时理论上能够解决SEO、EPO、SOO等关系重叠问题
缺点:
- TPLinker的标注复杂度高,存在很多冗余的操作和信息,若关系数目很大,需要标注
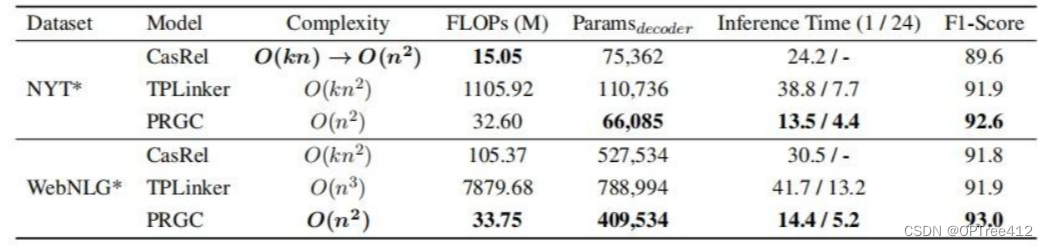
2N+1个标签表,就像1.2中PRGC提到的关系冗余,导致解码部分矩阵参数量很大,标签表会非常稀疏,训练收敛速度慢 - TPLinker的解码效率并不是很高,下图为1.2中PRGC论文中的模型效率对比图,可以发现TPLinker的计算复杂度和解码效率并不是很高
- 实体和关系各自进行标注抽取,实体和关系没有进行很深的交互和关联