Adel, H. and H. Schütze “Global Normalization of Convolutional Neural Networks for Joint Entity and Relation Classification.”
abstract
- CNN+CRF>CNN+softmax
引入全局归一化卷积神经网络进行联合实体分类和关系提取。特别地,我们提出了一种利用线性链条件随机场输出层同时预测实体类型和实体之间关系的方法。实验结果表明,在基准数据集上,全局规格化的性能优于局部规格化的softmax层。
1.Introduction
- 命名实体类型和关系通常是相互依赖的。如果实体的类型已知,则它们之间可能的关系的搜索空间可以减少,反之亦然。
- 用CRF的损失函数训练我们的NN参数

与之前的工作不同,我们将联合实体和关系分类问题建模为CRF层长度为3的序列。特别地,我们识别给定句子的两个候选实体(单词或短语)的类型(我们称之为实体分类,以将其与标记任务NER区分开来)以及它们之间的关系。就我们所知,这种将实体分类和关系分类结合在一个神经网络中的结构是新颖的。图1显示了我们如何对任务建模的示例:对于每个句子,都标识了候选实体。然后,候选实体(查询实体对)的每个可能组合形成我们模型的输入,该模型预测两个查询实体的类以及它们之间的关系。
- 句子->CRF层长度为3的序列
- 我们:
- 对每个句子标示候选实体
- 候选实体排列组合形成模型输入
- 预测两个查询实体的类及其关系
- 任务:实体分类+关系分类(联合进行)
- 证明CNN+CRF > CNN+softmax
- 输入:单词的嵌入
- 首次使用NN的全局规格化
- 使用线性链CRF
2.相关工作
一些关于联合实体和关系分类的工作使用远程监控来构建他们自己的数据集,例如,(Yao et al., 2010;Yaghoobzadeh等人,2016)。其他的研究,这些将在下面详细描述,使用来自(Roth和Yih, 2004, 2007)的实体和关系识别(ERR)数据集,正如我们在本文中所做的。
Roth和Yih(2004)开发了约束,并使用线性规划对实体类型和关系进行全局规范化。
Giuliano等人(2007)使用实体类型信息进行关系提取,但不同时训练两个任务。
Kate和Mooney(2010)训练特定于任务的支持向量机,并开发一个卡片金字塔解析算法来联合建模这两个任务。
Miwa和Sasaki(2014)使用相同的数据集,但将任务建模为表填充问题(参见4.2节)。他们的模型同时使用局部和全局评分函数。
最近,Gupta等人(2016)应用递归神经网络来填充表格。他们以多任务的方式训练他们。
以前的工作还使用了各种语言特性,如词性标记。
相反,我们使用卷积神经网络,只使用单词嵌入作为输入。在此基础上,我们首次采用神经网络的全局规格化方法。
一些研究提出了用于信息提取任务的非神经CRF模型的不同变体,但将它们建模为标记标记问题(Sutton和McCallum, 2006;Sarawagi等人,2004;Culotta等人,2006;朱等,2005;彭和麦卡勒姆,2006)。
**CRF:**相比之下,我们提出了一个更简单的线性链CRF模型,它直接连接实体和关系类,而不是为输入序列的每个标记分配一个标签。这与Yao等人(2010)的因素图更相似,但在计算上更简单。徐和Sarikaya(2013)也在CNN获得的连续表示法上应用了CRF层。然而,他们将其用于标记任务(语义槽填充),而我们将该模型应用于句子分类任务,其动机是CNN为整个短语或句子创建单个表示。
3.Model

输入。给定一个输入语句和两个查询实体,我们的模型识别实体的类型和它们之间的关系;参见图1。输入标记由word2vec在Wikipedia上训练的词嵌入表示(Mikolov等人,2013)。为了识别一个实体ek的类,模型使用它左边的上下文、组成ek的单词和它右边的上下文。为了区分两个实体ei和ej之间的关系,这个句子被分成六个部分:ei的左边,ei的右边,ei的右边,ej的左边,ej的右边,ej的右边。对于图1中的示例句子和实体对(Anderson, chief),上下文分割是:[][Anderson] [, 41, was the chief Middle…41岁的安德森是《纽约时报》驻中东记者。
- 输入:划分为5部分:ei的左边,ei的右边,ei的右边,ej的左边,ej的右边,ej的右边。
- 句子表示:CNN得到句子表示,2个CNN层(实体和上下文的)
句子表示。为了表示输入句子的不同部分,我们使用了卷积神经网络(CNNs)。CNNs适用于RE,因为关系通常由整个短语或句子的语义来表示。此外,它们在之前的工作中已经证明对RE有效(Vu et al., 2016)。我们训练一个CNN层用于卷积实体,另一个用于上下文。使用两个CNN层而不是一个,使我们的模型更加灵活。由于实体通常比上下文短,因此实体的筛选器宽度可以比上下文小。此外,该体系结构简化了将实体表示从单词转换为字符的工作。
在卷积之后,我们对实体和上下文应用k-max池,并将结果连接起来。拼接后的向量c_z∈R^{C_z}, z∈{EC, RE}转发给尺寸为Hz的任务特定隐含层,该隐含层跨不同输入部分学习模式:
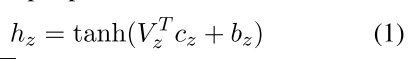
全局归一化层(使用线性链CRF)
- 一个线性层
对于全局归一化,我们采用Lample等(2016)的线性链CRF层。它期望不同的班级的分数作为输入。因此,我们首先应用一个线性层,将表示hz∈RHz映射到输出类N = N_{EC} +N_{RE}大小的向量vz:
扫描二维码关注公众号,回复: 9647329 查看本文章
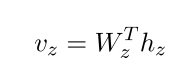
- 用这个来建模
对于句子分类任务,CRF层的输入序列不是很清楚。因此,我们建议使用以下分数序列来建模联合实体和关系分类问题(cf.,图2)
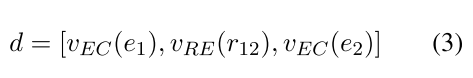
- 联合概率
- 我们的直觉是,关系与实体之间的依赖关系要强于实体与实体之间的依赖关系
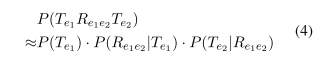
- 我们的直觉是,关系与实体之间的依赖关系要强于实体与实体之间的依赖关系
- 分数
- CRF层用开始和结束标记填充其长度为n = 3的输入,并为一系列预测y计算如下分数:
- :Qk,l为k类到l类的过渡分数,dp为q类在序列p位置的分数
- 因为CRF层的所有变量都在log空间中,所以对分数进行求和。
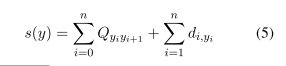
- 前向算法
- 向前算法计算所有可能的标签序列Y的分数得到正确的标签序列的对数概率ˆY
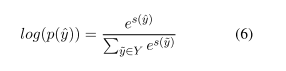
- 向前算法计算所有可能的标签序列Y的分数得到正确的标签序列的对数概率ˆY
- test:用维特比得到序列
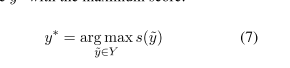
4.实验和分析
N-没关系
设置1:实体对关系。罗斯和Yih (2004,2007);Kate和Mooney(2010)在ERR数据集上分别训练EC和RE模型。对于RE,它们仅标识命名实体对之间的关系。在这个设置中,模型的查询实体只是命名实体对。注意,这有利于EC在我们的实验。
设置2:表填充。继Miwa和Sasaki(2014)之后;Gupta等人(2016)也将EC和RE的联合任务建模为填表任务。对于长度为m的句子,我们创建一个二次表。Cell (i, j)包含单词i和单词j之间的关系(没有关系的单词为N)。一个对角单元格(k, k)包含单词k的实体类型。根据前面的工作,我们只预测表的一半的类,即m(m + 1)/2个单元格。图3显示了图1中的示例句子的表。在这个设置中,i = j的每个单元格(i, j)都是模型的一个单独输入查询。我们的模型输出对单元格(i, j) (i和j之间的关系)的预测和对单元格(i, i)和(j, j) (i和j的类型)的预测。第4.4节表明,在几乎所有情况下,个人的预测都与多数票一致
设置3:没有实体边界的表填充。来自setup 2的表包含每个多令牌实体的一个行/列,利用ERR数据集的给定实体边界。为了研究实体边界对分类结果的影响,我们还考虑了另一个表填充设置,在这个设置中,我们忽略边界并为每个标记分配一个行/列。请注意,这种设置也用于以前的表格填充工作(Miwa和Sasaki, 2014;Gupta等人,2016)。对于评估,我们遵循Gupta等人(2016)的方法,如果一个多标记实体中至少有一个标记是正确的,我们就对其进行评分
比较。setup 1和setup 2之间最重要的区别是没有关系的实体对的数量(test set:≈3k for setup 1,≈121k for setup 2),这使得setup 2更具挑战性。同样适用于setup 3,它考虑与setup 2相同数量的没有关系的实体对。为了解决这个问题,我们在setup 2和setup 3的训练集中随机抽样了一些负面的实例。Setup 3考虑最多的查询由于多令牌实体被分割为包含它们的令牌,所以它们总共对实体进行了分组。但是,setup 3比setup 1或setup 2更符合实际,因为在大多数情况下,实体边界没有给出。为了将setup 1或setup 2应用到另一个没有实体边界的数据集,需要一个预处理步骤,例如实体边界识别或分块。
4.3实验结果
表1显示了全局规范化模型与局部规范化softmax输出层(一个用于EC,一个用于RE)的模型的比较结果。对于setup 1, CRF层的性能与softmax层相当或更好。对于setup 2和setup 3,改进更加明显。我们假设在表填充的情况下,模型可以从全局规范化中获得更多的好处,因为它是更具挑战性的设置。设置2和设置3之间的比较表明,该实体分类患有没有实体边界(在设置3)。一个原因可能是,该模型不能令牌卷积multi-token实体的映射进行了计算实体时表示如图2 B和D(上下文)。然而,分类性能相当的关系设置2和设置3。这表明该模型可以在内部解释由于缺少实体边界而可能出现的错误实体分类结果。
总的结果(Avg EC+RE)的CRF比结果的软max层所有三种设置。综上所述,线性链CRF的改进表明:(i)联合EC和RE受益于全局正规化;(ii)我们为关节EC和RE创建CRF输入序列的方法是有效的。
我们的结果是最好的可比(Gupta等人,2016),因为我们使用相同的设置和训练分割。然而,他们的模型更复杂,有许多手工制作的特性和实体和关系类之间的建模依赖的各种迭代。相反,我们只使用预先训练好的词嵌入,并且只对每个实体对进行一次迭代来训练我们的模型。当我们与没有附加特征的模型进行比较时(G et al. 2016(2)),我们的模型对EC表现较差,但对RE表现较好,对Avg EC+RE可比较。
总结
在这篇论文中,我们首次研究了一个句子分类任务的神经网络的全局规格化,而没有将其转化为一个标记标记问题。我们在联合实体和关系分类上训练了一个具有线性链条件随机场输出层的卷积神经网络,并证明了它在局部归一化softmax层上的性能。一个有趣的未来方向是对线性链CRF的扩展,以联合规范化单个模型遍历表填充的所有预测。此外,我们计划在未来的工作中在其他数据集上验证我们的结果。
