文章目录
本文:Miwa, M. and M. Bansal “End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures.”
abstract
提出了一种新的端到端神经网络模型来提取实体及其之间的关系。我们的递归神经网络模型通过在双向序列LSTM-RNNs上叠加双向树型结构LSTM-RNNs来捕获单词序列和依赖树的子结构信息。这使得我们的模型可以在单个模型中使用共享参数联合表示实体和关系。我们进一步鼓励在训练期间发现实体,并通过实体培训前和计划抽样在关系提取中使用实体信息。我们的模型在基于端到端关系提取的最先进特征模型的基础上进行了改进,分别实现了ACE2005和ACE2004上的F1score的12.1%和5.7%的相对误差降低。我们还表明,我们基于LSTMRNN的模型在名义关系分类(SemEval-2010 Task 8)方面优于最先进的基于CNN的模型(F1-score)。最后,我们提出了一个广泛的烧蚀分析的几个模型组件(an extensive ablation analysis of several model components)。
- model:端到端神经网络模型来提取实体及其之间的关系
- 递归神经网络:双向序列LSTM-RNNs上叠加双向树型结构LSTM-RNNs–> 捕获单词序列和依赖树的子结构信息
- 共享参数
- extensive ablation analysis 组件
- 在训练中发现尸体,在关系抽取中使用实体信息
1.introduction
(联合)实体和关系的建模对高性能很重要(Li和Ji, 2014;(Miwa and Sasaki, 2014)因为关系与实体信息密切互动。例如,Toefting和Bolton在Toefting转移到Bolton这句话中有一个Organization (ORG-AFF)关系,Toefting和Bolton是个体和组织实体的实体信息是重要的。反过来,这些实体的提取又受到转到表示雇佣关系的上下文词的鼓励。之前的联合模型采用了基于特征的结构化学习。这种端到端关系提取任务的另一种方法是通过基于神经网络(NN)的模型实现自动特征学习。
- 以前:管道(两个任务分开处理)
- 端到端:联合模型更好
- 关系与实体密切相关
- 以前的模型:基于特征的结构化学习
- 本文:基于NN的自动特征学习
使用神经网络表示实体之间的关系有两种方法:递归神经网络(RNNs)和卷积神经网络(CNNs)。其中,RNNs可以直接表示基本的语言结构,即,单词序列(Hammerton, 2001)和成分/依赖树(Tai et al., 2015)。尽管有这种表示能力,但在关系分类任务中,之前报道的基于长短时记忆(LSTM)的RNNs的性能(Xu et al., 2015b;Li et al., 2015)比使用CNNs更糟糕(dos Santos et al., 2015)。这些以前的基于lstm的系统大多包括有限的语言结构和神经结构,并且不联合建模实体和关系。我们能够通过基于包含互补语言结构的更丰富的LSTM-RNN体系结构的实体和关系的端到端建模来实现对最先进模型的改进。
- NN的方法
- RNNs:直接表示基本的语言结构
- 但LSTM<CNNs
- 原因:以前的基于lstm的系统大多包括有限的语言结构和神经结构,并且不联合建模实体和关系
- 但LSTM<CNNs
- CNNs:
- 本文:通过基于包含互补语言结构的更丰富的LSTM-RNN体系结构的实体和关系的端到端建模来实现对最先进模型的改进。
- RNNs:直接表示基本的语言结构
词序列和树结构是提取关系的互补信息。例如,单词之间的依赖关系仅仅预测来源和美国在句子This is…一位美国消息人士说,这个语境词是这个预测所需要的。许多传统的基于特征的关系分类模型从序列和解析树中提取特征(Zhou et al., 2005)。然而,以往基于RNN的模型只关注这些语言结构中的一种(Socher et al., 2012)。
- 词序列和树结构是提取关系的互补信息
- 往基于RNN的模型只关注这些语言结构中的一种(词序列或树结构
我们提出了一种新的端到端模型来提取词序列和依赖树结构上实体之间的关系。我们的模型通过使用双向顺序(从左到右和从右到左)和双向树结构(自底向上和自顶向下)LSTM-RNNs,允许在单个模型中对实体和关系进行联合建模。我们的模型首先检测实体,然后使用单个增量解码的神经网络结构提取被检测实体之间的关系,并使用实体和关系标签联合对神经网络参数进行更新。与传统的增量端到端关系提取模型不同,我们的模型在训练中进一步加入了两个增强:实体预训练(对实体模型进行预训练)和计划抽样(Bengio et al., 2015),后者以一定的概率将(不可靠的)预测标签替换为黄金标签。这些增强减轻了在培训的早期阶段发现性能低下的实体的问题,并允许实体信息进一步帮助下游关系分类。
- NN:
- 使用双向顺序(从左到右和从右到左)和双向树结构(自底向上和自顶向下)LSTM-RNNs
- 允许在单个模型中对实体和关系进行联合建模
- 操作:
- 先检测实体,
- 然后使用单个增量解码的神经网络结构提取被检测实体之间的关系,
- 并使用实体和关系标签联合对神经网络参数进行更新。
- 两个增强:
- 实体预训练(对实体模型进行预训练
- 计划抽样(Bengio et al., 2015)
- 后者以一定的概率将(不可靠的)预测标签替换为黄金标签
- 作用:减轻了在培训的早期阶段发现性能低下的实体的问题,并允许实体信息进一步帮助下游关系分类。
在端到端关系提取方面,我们改进了最先进的基于特征的模型,在F1-score中减少了12.1% (ACE2005)和5.7% (ACE2004)的相对错误。在名义关系分类(SemEval-2010 Task 8)上,我们的模型在F1-score上优于最先进的基于cnn的模型。最后,我们还对我们的各种模型组件进行了删减和比较,得出了关于不同RNN结构、输入依赖关系结构、不同解析模型、外部资源和联合学习设置的贡献和有效性的一些关键结论(积极的和消极的)。
- 改进了最先进的基于特征的模型
- 组件删减和比较
2.相关工作
LSTM-RNNs被广泛用于顺序标记,如从句识别(Hammerton, 2001)、语音标记(Graves and Schmidhuber, 2005)和NER (Hammerton, 2003)。最近,Huang等人(2015)证明了这一点在双向LSTM-RNNs上构建条件随机域(CRF)层的性能与partof-speech (POS)标记、分块和NER中的最新方法相当。
- 对于关系分类,除了传统的基于特征/内核的方法外(Zelenko et al., 2003;Bunescu和Mooney(2005)在semevalv -2010 Task 8 (Hendrickx et al., 2010)中提出了几种神经模型,包括
- 基于嵌入的模型(Hashimoto et al., 2015)、
- 基于cnn的模型(dos Santos et al., 2015)和
- 基于rnn的模型(Socher et al., 2012)。
- 最近,Xu et al. (2015a)和Xu et al. (2015b)表明,基于特征/内核的系统中使用的关系参数之间的最短依赖路径在基于nn-based的模型中也很有用(Bunescu和Mooney, 2005)。
- Xu等人(2015b)也表明LSTMRNNs在关系分类中是有用的,但其性能不如基于cnn的模型。
- Li等(2015)使用基本的RNN模型结构,比较了单独的基于序列和树型的LSTM-RNNs在关系分类上的差异。
树结构LSTM-RNNs的研究(Tai et al., 2015)修正了从下到上的信息传播方向,也不能像类型化依赖树那样处理任意数量的类型化子节点。此外,没有一种基于RNNbased的关系分类模型同时使用词序列和依赖树信息。我们提出了几个这样的新模型结构和训练设置,研究了同时使用双向顺序和双向树状结构LSTM-RNNs来联合捕获线性和依赖上下文来提取实体之间的关系。
- 没有一种基于RNNbased的关系分类模型同时使用词序列和依赖树信息
- 本文用了
对于实体间关系的端到端(联合)提取,现有的模型都是基于特征的系统(没有提出基于nn的模型)。这些模型包括结构化预测(Li和Ji, 2014;Miwa和Sasaki, 2014),整数线性规划(Roth和Yih, 2007;Yang和Cardie, 2013),卡片金字塔解析(Kate和Mooney, 2010),全球概率图形模型(Yu和Lam, 2010;辛格等人,2013)。其中,结构化预测方法在一些语料库上是最先进的。我们提出了一种改进的基于nn的端到端关系提取方法。
- 以前只有基于特征的联合抽取
- 本文提出了基于nn的联合抽取
3.model

我们使用表示字序列和依赖树结构的LSTM-RNNs来设计我们的模型,并在这些RNNs之上执行实体之间关系的端到端提取。图1为模型概述。该模型主要由三层表示层组成:单词嵌入层(embeddings layer,即嵌入层)、基于单词序列的LSTM-RNN层(sequence layer,即序列层),最后是基于依赖子树的LSTM-RNN层(dependency layer,即依赖层)。在解码过程中,我们在序列层上建立贪婪的从左到右的实体检测,在依赖层上实现关系分类,每个基于LSTM-RNN的子树对应两个被检测实体之间的关系候选。在解码整个模型结构之后,我们通过时间反向传播(BPTT)同时更新参数(Werbos, 1990)。依赖层叠加在序列层上,嵌入层和序列层由实体检测和关系分类共享,共享参数由实体标签和关系标签共同影响。
- 三层
- 嵌入层
- lstm-rnn层(序列层
- 依赖层(基于依赖子树的LSTM-RNN层
- 解码
- 贪婪的实体检测(左-》右)
- 在依赖层上实现关系分类
- 每个基于LSTM-RNN的子树对应两个被检测实体之间的关系候选
- 参数更新
- BPTT(同时更新
- 共享参数
- 依赖层叠加在序列层上,嵌入层和序列层由实体检测和关系分类共享,共享参数由实体标签和关系标签共同影响。
3.1嵌入层
- 向量表示
3.2 序列层
序列层使用来自嵌入层的表示以线性序列表示单词。该层表示句子上下文信息并维护实体,如图1左下角所示
我们用双向LSTM-RNNs表示句子中的单词序列(Graves et al., 2013)。第t字处的LSTM单元由一组nls维向量组成:一个输入门it、一个遗忘门ft、一个输出门ot、一个存储单元ct和一个隐藏状态ht。该单元接收一个n维输入向量xt、先前的隐藏状态ht 1和内存单元ct 1,并使用以下方程计算新的向量
- KaTeX parse error: Undefined control sequence: \sigmoid at position 1: \̲s̲i̲g̲m̲o̲i̲d̲:是sigmoid函数(log…
- 输出向量的两个方向也联合成一个st

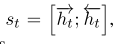
3.3实体检测
我们将实体检测视为一个序列标记任务。我们使用一个常用的编码方案BILOU (Begin, Inside, Last, Outside, Unit)为每个单词分配一个实体标记(Ratinov和Roth, 2009),其中每个实体标记表示实体类型和单词在实体中的位置。例如,在图1中,我们将B-PER和L-PER(分别表示person实体类型的开头和结尾)分配给Sidney Yates中的每个单词,以将该短语表示为PER (person)实体类型。
- 序列标注问题
- 使用BILOU(Begin, Inside, Last, Outside, Unit)
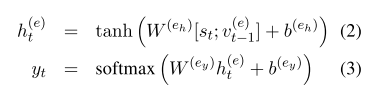
- 使用BILOU(Begin, Inside, Last, Outside, Unit)
我们以贪婪的从左到右的方式为单词分配实体标签。在这个解码过程中,我们使用一个单词的预测标签来预测下一个单词的标签,从而考虑到标签的相关性。上面的NN接收它在序列层中相应输出的拼接和它前面单词的标签嵌入(图1)。
3.4 依赖层
- 找一对目标词之间的最短路径
- 我们使用双向树结构的LSTM-RNNs(即。底->上,上->下)
- 我们提出了一种新的树结构LSTM-RNN的变体,它可以共享同类型子节点的权矩阵,并且允许子节点的数目是可变的。
依赖层表示依赖树中一对目标词(对应关系分类中的关系候选词)之间的关系,负责关系的特定表示,如图1右上角所示。这一层主要关注依赖树中一对目标词之间的最短路径。因为这些路径被证明在关系分类中是有效的(Xu et al., 2015a)。例如,我们在图1的底部显示了Yates和Chicago之间的最短路径,这条路径很好地捕捉了他们关系的关键短语,即borin-in。
我们使用双向树结构的LSTM-RNNs(即。底->上,上->下)通过捕获目标词对周围的依赖关系结构来表示候选关系。这种双向结构不仅向每个节点传播来自叶节点的信息,而且还传播来自根节点的信息。这对于关系分类特别重要,因为它利用了树底部附近的参数节点,而我们的自顶向下LSTM-RNN将树顶部的信息发送到这些近叶节点(与标准的自底向上LSTM-RNNs不同)。注意,Tai等人(2015)提出的树结构LSTM-RNNs的两个变体不能表示我们的目标结构,这些目标结构的子类型数量是可变的:子和树lstm不处理类型,而N-ary树假设有固定数量的子类型。因此,我们提出了一种新的树结构LSTM-RNN的变体,它可以共享同类型子节点的权矩阵,并且允许子节点的数目是可变的。对于该变量,我们使用以下公式计算LSTM单元第t个节点上的nlt维向量和C(t)个子节点上的nlt维向量

- m–一种映射函数
为了研究合适的结构来表示两个目标词对之间的关系,我们用三种结构选项进行了实验。我们主要使用最短路径结构(SPTree),它捕获目标词对之间的核心依赖路径,广泛用于关系分类模型,例如Bunescu和Mooney, 2005; Xu et al., 2015a). 我们还尝试了另外两种依赖结构:SubTree 和FullTree。SubTree 是目标词对的最低共同祖先的子树。这为SPTree中的路径和单词对提供了额外的修饰符信息。FullTree是完整的依赖树。这捕获了整个句子的上下文。当我们为SPTree使用一个节点类型时,我们为子树和FullTree定义了两个节点类型,即,一个用于最短路径上的节点,另一个用于所有其他节点。我们使用类型映射function m(·)来区分这两个节点类型。
- 用了三种结构选项实验
- 最短路径结构(SPTree),它捕获目标词对之间的核心依赖路径
- SubTree :目标词对的最低共同祖先的子树
- FullTree:完整的依赖树,这捕获了整个句子的上下文。
3.5 Stacking Sequence and Dependency Layers
我们将依赖层(对应于候选关系)堆叠在序列层的顶部,以便将单词序列和依赖树结构信息合并到输出中。
- 第t个字的依赖层LSTM单元接收xt作为输入
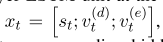
3.6关系分类
- 我们使用检测到的实体的最后几个字的所有可能组合,逐步构建候选关系。
- 负关系:实体错误或没关系–无方向
- 关系标签:类型+方向
- 将关联候选向量构造为串联KaTeX parse error: Undefined control sequence: \toparrow at position 6: d_p=[\̲t̲o̲p̲a̲r̲r̲o̲w̲ ̲h_{pA};\downarr…
我们使用检测到的实体的最后几个字的所有可能组合,逐步构建候选关系。即是说,译码过程中,BILOU方案中带有L或U标签的单词。例如,在图1中,我们使用带有L-PER标签的Yates和带有U-LOC标签的Chicago来构建关系候选。对于每个关系候选对象,我们实现了与关系候选对象中对p之间的路径相对应的依赖层dp(如上所述),神经网络接收由依赖树层输出构造的关系候选向量,并预测其关系标签。当被检测到的实体是错误的或者是没有关系的时候,我们将一对视为负关系。除了没有方向的负关系外,我们用类型和方向来表示关系标签。
我们从基于顺序LSTM-RNNs+树型LSTM-RNNs的关系分类中构造了输入dp,因此序列层对输入的贡献是间接的。此外,我们的模型使用单词来表示实体,因此它不能完全使用实体信息。为了缓解这些问题,我们直接将从序列层到输入dp再到关系分类的每个实体的隐藏状态向量的平均值连接起来
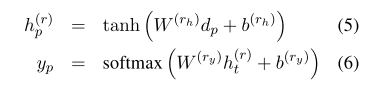
- 问题
- 贡献是简介的
- 不能完全使用实体信息
- 解决:直接将从序列层到输入dp再到关系分类的每个实体的隐藏状态向量的平均值连接起来–dp’=
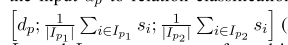
此外,由于我们同时考虑了从左到右和从右到左的方向,所以我们在预测时为每个词对分配了两个标签。当预测的标签不一致时,我们选择积极和更自信的标签,类似于Xu等人(2015a)。
3.7 训练
更新:权重,bias,embeddings
- 方法
- BPTT
- adam(梯度裁剪)
- 参数平均
- L2-regularization(W,U),不对biases正则化
- dropout
- 嵌入层
- 实体检测的最后一层的隐层
- 关系分类
- 两个增强
- 为了减轻培训初期实体预测不可靠的问题和鼓励从被检测的实体构建积极的关系实例
- scheduled sampling
- 实体预训练
4 实验
为了分析我们的端到端关系提取模型的各个组成部分的贡献和影响,我们对ACE05开发集进行了消融测试(表2)。在不进行计划采样的情况下,性能略有下降,在去除实体预训练或同时去除实体预训练或同时去除两者时,性能显著下降(p<0.05)。这是合理的,因为模型只能在发现两个实体时创建关系实例,如果没有这些增强,发现一些关系可能就太晚了。


我们还展示了在不共享参数的情况下的性能,即、嵌入层和序列层,用于检测实体和关系(共享参数);我们首先训练实体检测模型,用模型检测实体,然后利用被检测实体建立一个单独的关系提取模型,即,没有实体检测。这个设置可以看作是一个流水线模型,因为两个单独的模型是按顺序训练的。在没有共享参数的情况下,实体检测和关系分类的性能都略有下降,尽管存在差异但不重要。当我们删除所有的增强时,即的性能显著低于SPTree (p<0.01),表明这些增强为端到端关系提取提供了互补优势
总结
提出了一种基于双向序列和双向树结构的LSTM-RNNs的端到端关系抽取模型,该模型同时表示字序列和依赖树结构。这允许我们代表实体和关系在一个模型中,实现先进的收益,基于功能的系统端到端关系提取(ACE04和ACE05),并显示类似的性能要优于最新最先进的CNNbased模型名义关系分类任务(semeval - 2010 8)。我们的评估和烧蚀导致三个重要发现。首先,单词序列和依赖树结构的使用是有效的。其次,使用共享参数进行训练可以提高关系提取的准确性,特别是在使用实体预训练、计划抽样和标签嵌入时。最后,在关系分类中得到广泛应用的最短路径也适用于神经LSTM模型中树结构的表示。
