学习地址:https://www.kesci.com/org/boyuai/project/5e48089f17aec8002dc5f4d0
优化算法进阶
Momentum
目标函数有关自变量的梯度代表了目标函数在自变量当前位置下降最快的方向。因此,梯度下降也叫作最陡下降(steepest descent)。在每次迭代中,梯度下降根据自变量当前位置,沿着当前位置的梯度更新自变量。然而,如果自变量的迭代方向仅仅取决于自变量当前位置,这可能会带来一些问题。对于noisy gradient,我们需要谨慎的选取学习率和batch size, 来控制梯度方差和收敛的结果。
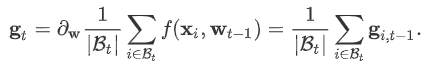
An ill-conditioned Problem

Maximum Learning Rate

Supp: Preconditioning

Momentum Algorithm

AdaGrad
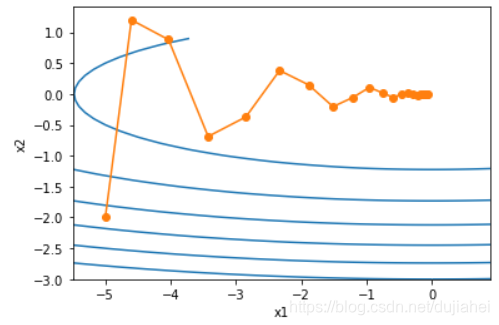
AdaGrad算法,它根据自变量在每个维度的梯度值的大小来调整各个维度上的学习率,从而避免统一的学习率难以适应所有维度的问题。
Algorithm

Feature
需要强调的是,小批量随机梯度按元素平方的累加变量St出现在学习率的分母项中。因此,如果目标函数有关自变量中某个元素的偏导数一直都较大,那么该元素的学习率将下降较快;反之,如果目标函数有关自变量中某个元素的偏导数一直都较小,那么该元素的学习率将下降较慢。然而,由于St一直在累加按元素平方的梯度,自变量中每个元素的学习率在迭代过程中一直在降低(或不变)。所以,当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到一个有用的解。
RMSProp
当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到一个有用的解。为了解决这一问题,RMSProp算法对AdaGrad算法做了修改。该算法源自Coursera上的一门课程,即“机器学习的神经网络”。
Algorithm

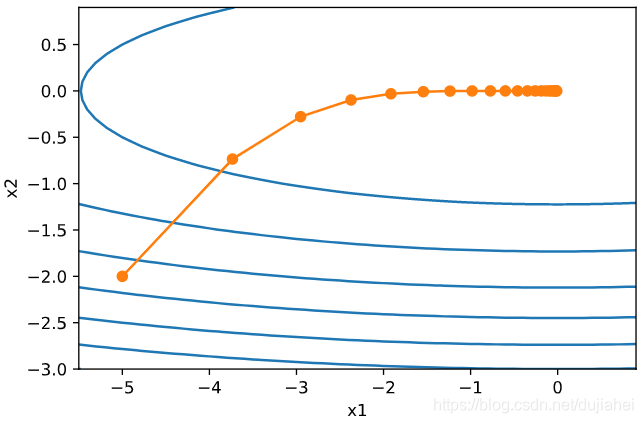
AdaDelta
AdaDelta算法没有学习率这一超参数。
Algorithm

Adam
Adam算法在RMSProp算法基础上对小批量随机梯度也做了指数加权移动平均。
Algorithm

word2vec 词嵌入基础
使用 one-hot 向量表示单词,虽然它们构造起来很容易,但通常并不是一个好选择。一个主要的原因是,one-hot 词向量无法准确表达不同词之间的相似度,如我们常常使用的余弦相似度。
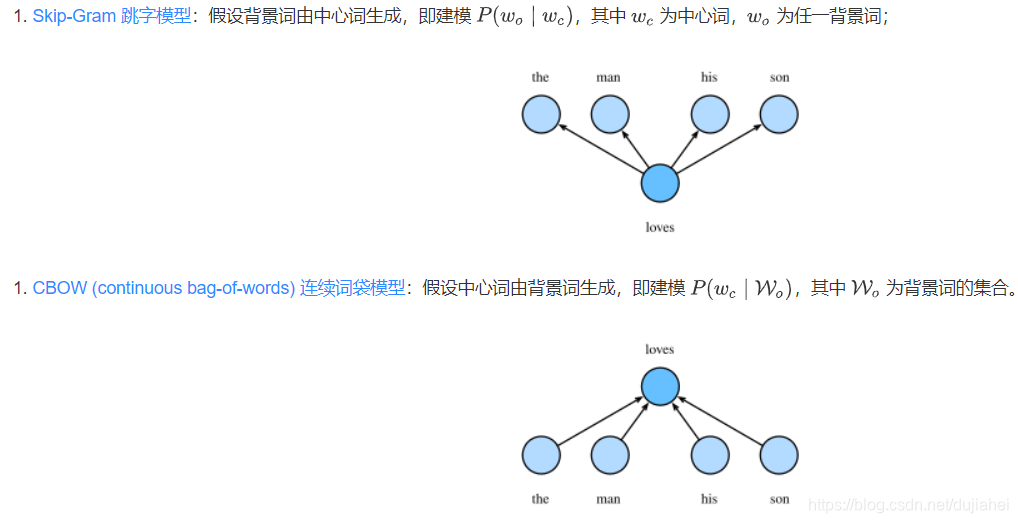
Word2Vec 词嵌入工具的提出正是为了解决上面这个问题,它将每个词表示成一个定长的向量,并通过在语料库上的预训练使得这些向量能较好地表达不同词之间的相似和类比关系,以引入一定的语义信息。基于两种概率模型的假设,我们可以定义两种 Word2Vec 模型:
PTB数据集
简单来说,Word2Vec 能从语料中学到如何将离散的词映射为连续空间中的向量,并保留其语义上的相似关系。那么为了训练 Word2Vec 模型,我们就需要一个自然语言语料库,模型将从中学习各个单词间的关系,这里我们使用经典的 PTB 语料库进行训练。PTB (Penn Tree Bank) 是一个常用的小型语料库,它采样自《华尔街日报》的文章,包括训练集、验证集和测试集。我们将在PTB训练集上训练词嵌入模型。
Skip-Gram 跳字模型

负采样近似

词嵌入进阶
虽然 Word2Vec 已经能够成功地将离散的单词转换为连续的词向量,并能一定程度上地保存词与词之间的近似关系,但 Word2Vec 模型仍不是完美的,它还可以被进一步地改进:
子词嵌入(subword embedding):FastText 以固定大小的 n-gram 形式将单词更细致地表示为了子词的集合,而 BPE (byte pair encoding) 算法则能根据语料库的统计信息,自动且动态地生成高频子词的集合;
GloVe 全局向量的词嵌入: 通过等价转换 Word2Vec 模型的条件概率公式,我们可以得到一个全局的损失函数表达,并在此基础上进一步优化模型。
实际中,我们常常在大规模的语料上训练这些词嵌入模型,并将预训练得到的词向量应用到下游的自然语言处理任务中。本节就将以 GloVe 模型为例,演示如何用预训练好的词向量来求近义词和类比词。
GloVe 全局向量的词嵌入
GloVe 模型
先简单回顾以下 Word2Vec 的损失函数(以 Skip-Gram 模型为例,不考虑负采样近似):
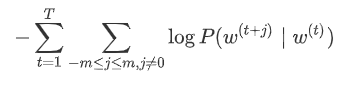
其中



