深度学习基础
线性回归的实现
本节将介绍如何只利用NDArray和autograd来实现一个线性回归的训练。
生成数据集
%matplotlib inline
from IPython import display
from matplotlib import pyplot as plt
from mxnet import autograd, nd
import random
我们构造一个简单的人工训练数据集,它可以使我们能够直观比较学到的参数和真实的模型参数的区别。设训练数据集样本数为1000,输入个数(特征数)为2。给定随机生成的批量样本特征 X ∈ R 1000 × 2 \boldsymbol{X} \in \mathbb{R}^{1000 \times 2} X∈R1000×2,我们使用线性回归模型真实权重 w = [ 2 , − 3.4 ] ⊤ \boldsymbol{w} = [2, -3.4]^\top w=[2,−3.4]⊤和偏差 b = 4.2 b = 4.2 b=4.2,以及一个随机噪声项 ϵ \epsilon ϵ来生成标签
y = X w + b + ϵ , \boldsymbol{y} = \boldsymbol{X}\boldsymbol{w} + b + \epsilon, y=Xw+b+ϵ,
其中噪声项 ϵ \epsilon ϵ服从均值为0、标准差为0.01的正态分布。噪声代表了数据集中无意义的干扰。下面,让我们生成数据集。
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = nd.random.normal(scale=1, shape=(num_examples, num_inputs))
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += nd.random.normal(scale=0.01, shape=labels.shape)
注意,features的每一行是一个长度为2的向量,而labels的每一行是一个长度为1的向量(标量)。
绘制散点图来看特征与结果之间的关系,这里以第二个特征为例:
plt.scatter(features[:, 1].asnumpy(), labels.asnumpy(),1); # 加分号只显示图,1控制散点的大小
读取数据集
在训练模型的时候,我们需要遍历数据集并不断读取小批量数据样本。这里我们定义一个函数:它每次返回batch_size(批量大小)个随机样本的特征和标签。
# 本函数已保存在d2lzh包中方便以后使用
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) # 样本的读取顺序是随机的
for i in range(0, num_examples, batch_size):
j = nd.array(indices[i: min(i + batch_size, num_examples)])
yield features.take(j), labels.take(j) # take函数根据索引返回对应元素
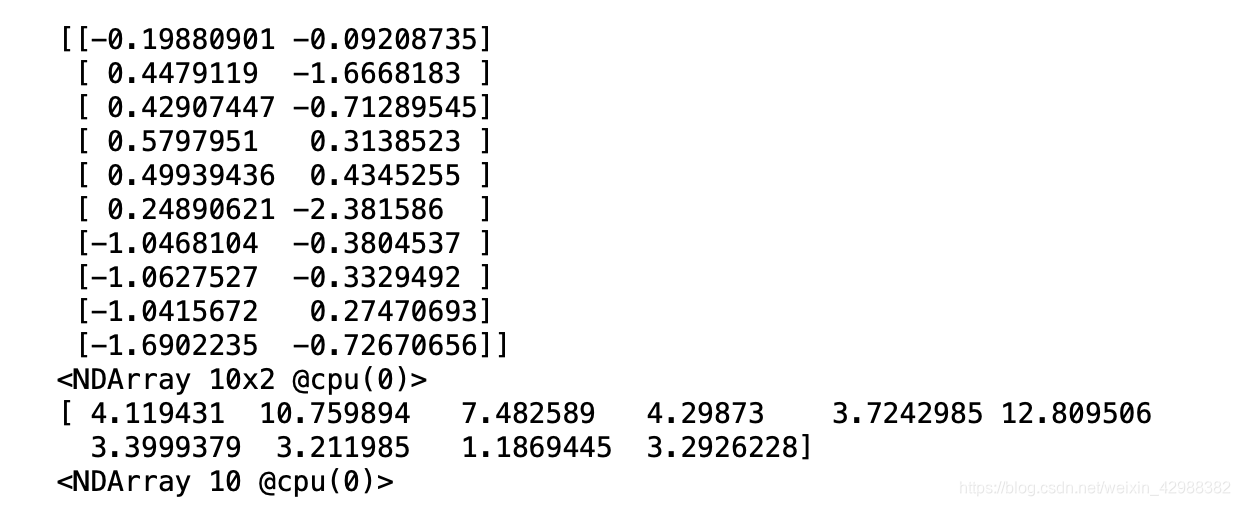
让我们读取第一个小批量数据样本并打印。每个批量的特征形状为(10, 2),分别对应批量大小和输入个数;标签形状为批量大小。
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, y)
break
初始化模型参数
我们将权重初始化成均值为0、标准差为0.01的正态随机数,偏差则初始化成0。
w = nd.random.normal(scale=0.01, shape=(num_inputs, 1)) #2行1列
b = nd.zeros(shape=(1,)) #是个一维数组,并且只有一个元素
之后的模型训练中,需要对这些参数求梯度来迭代参数的值,因此我们需要创建它们的梯度。
w.attach_grad()
b.attach_grad()
定义模型
下面是线性回归的矢量计算表达式的实现。我们使用dot函数做矩阵乘法。
def linreg(X, w, b): # 本函数已保存在d2lzh包中方便以后使用
return nd.dot(X, w) + b
定义损失函数
我们使用上一节描述的平方损失来定义线性回归的损失函数。在实现中,我们需要把真实值y变形成预测值y_hat的形状。以下函数返回的结果也将和y_hat的形状相同。
def squared_loss(y_hat, y): # 本函数已保存在d2lzh包中方便以后使用
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
定义优化算法
以下的sgd函数实现了上一节中介绍的小批量随机梯度下降算法。它通过不断迭代模型参数来优化损失函数。这里自动求梯度模块计算得来的梯度是一个批量样本的梯度和。我们将它除以批量大小来得到平均值。
def sgd(params, lr, batch_size): # 本函数已保存在d2lzh包中方便以后使用
for param in params:
param[:] = param - lr * param.grad / batch_size
训练模型
在训练中,我们将多次迭代模型参数。在每次迭代中,我们根据当前读取的小批量数据样本(特征X和标签y),通过调用反向函数backward计算小批量随机梯度,并调用优化算法sgd迭代模型参数。由于我们之前设批量大小batch_size为10,每个小批量的损失l的形状为(10, 1)。由于变量l并不是一个标量,运行l.backward()将对l中元素求和得到新的变量,再求该变量有关模型参数的梯度。
在一个迭代周期(epoch)中,我们将完整遍历一遍data_iter函数,并对训练数据集中所有样本都使用一次(假设样本数能够被批量大小整除)。这里的迭代周期个数num_epochs和学习率lr都是超参数,分别设3和0.03。在实践中,大多超参数都需要通过反复试错来不断调节。虽然迭代周期数设得越大模型可能越有效,但是训练时间可能过长。
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs): # 训练模型一共需要num_epochs个迭代周期
# 在每一个迭代周期中,会使用训练数据集中所有样本一次(假设样本数能够被批量大小整除)。X
# 和y分别是小批量样本的特征和标签
for X, y in data_iter(batch_size, features, labels):
with autograd.record():
l = loss(net(X, w, b), y) # l是有关小批量X和y的损失
l.backward() # 小批量的损失对模型参数求梯度
sgd([w, b], lr, batch_size) # 使用小批量随机梯度下降迭代模型参数
train_l = loss(net(features, w, b), labels)
print('epoch %d, loss %f' % (epoch + 1, train_l.mean().asnumpy()))
- 可以看出,仅使用
NDArray和autograd模块就可以很容易地实现一个模型。
利用gluon接口的简单线性回归实现
如果上面一节的线性回归过程觉得繁琐的话,可以直接看这一节的,通过调用接口来实现。
生成数据集
from mxnet import autograd, nd
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = nd.random.normal(scale=1, shape=(num_examples, num_inputs))
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += nd.random.normal(scale=0.01, shape=labels.shape)
读取数据集
Gluon提供了data包来读取数据。由于data常用作变量名,我们将导入的data模块用添加了Gluon首字母的假名gdata代替。在每一次迭代中,我们将随机读取包含10个数据样本的小批量。
from mxnet.gluon import data as gdata
batch_size = 10
# 将训练数据的特征和标签组合
dataset = gdata.ArrayDataset(features, labels)
# 随机读取小批量
data_iter = gdata.DataLoader(dataset, batch_size, shuffle=True)
所有的数据通过gdata.DataLoader函数整合成了batch_size的形式,我们读取并打印的第1个bacth_size的样本看看。
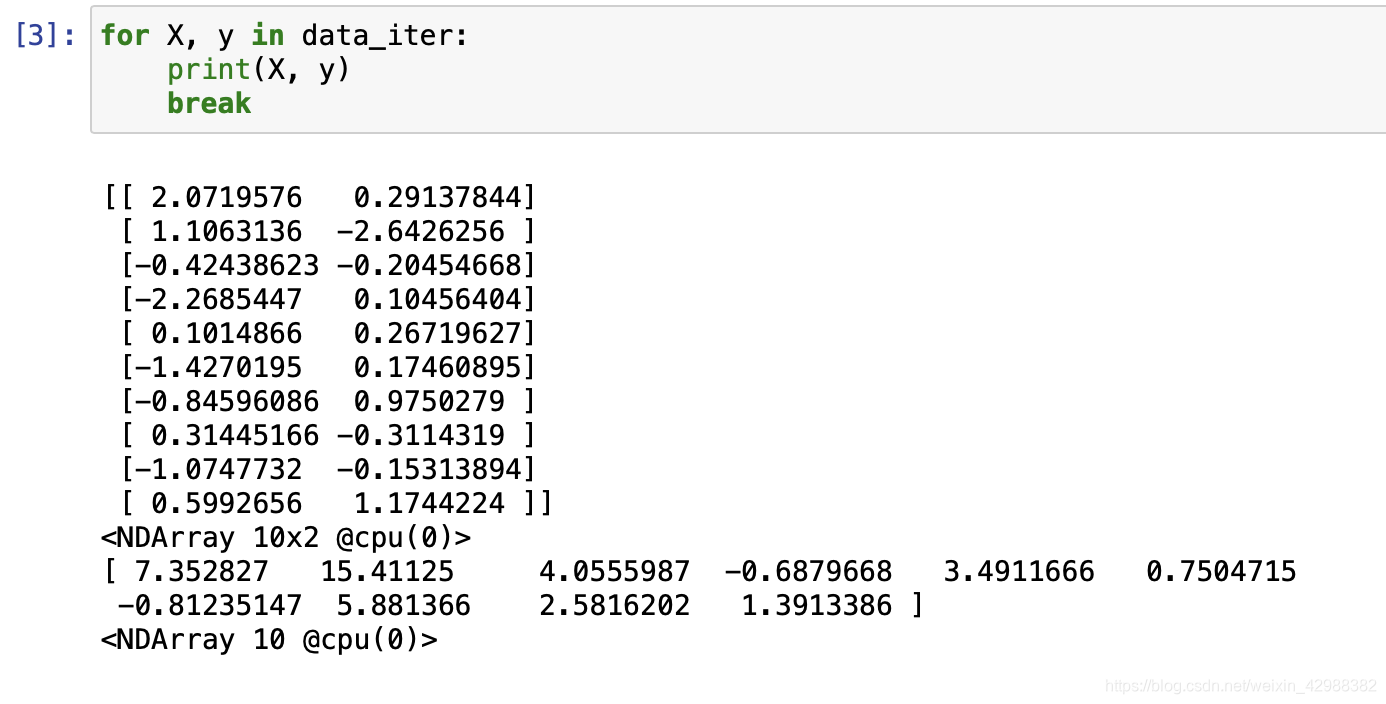
定义模型
在上一节从零开始的实现中,我们需要定义模型参数,并使用它们一步步描述模型是怎样计算的。当模型结构变得更复杂时,这些步骤将变得更烦琐。其实,Gluon提供了大量预定义的层,这使我们只需关注使用哪些层来构造模型。下面将介绍如何使用Gluon更简洁地定义线性回归。
首先,导入nn模块。实际上,“nn”是neural networks(神经网络)的缩写。顾名思义,该模块定义了大量神经网络的层。我们先定义一个模型变量net,它是一个Sequential实例。在Gluon中,Sequential实例可以看作是一个串联各个层的容器。在构造模型时,我们在该容器中依次添加层。当给定输入数据时,容器中的每一层将依次计算并将输出作为下一层的输入。
from mxnet.gluon import nn
net = nn.Sequential()
回顾图3.1中线性回归在神经网络图中的表示。作为一个单层神经网络,线性回归输出层中的神经元和输入层中各个输入完全连接。因此,线性回归的输出层又叫全连接层。在Gluon中,全连接层是一个Dense实例。我们定义该层输出个数为1。
net.add(nn.Dense(1))
值得一提的是,在Gluon中我们无须指定每一层输入的形状,例如线性回归的输入个数。当模型得到数据时,例如后面执行net(X)时,模型将自动推断出每一层的输入个数。我们将在之后“深度学习计算”一章详细介绍这种机制。Gluon的这一设计为模型开发带来便利。
初始化模型参数
在使用net前,我们需要初始化模型参数,如线性回归模型中的权重和偏差。我们从MXNet导入init模块。该模块提供了模型参数初始化的各种方法。这里的init是initializer的缩写形式。我们通过init.Normal(sigma=0.01)指定权重参数每个元素将在初始化时随机采样于均值为0、标准差为0.01的正态分布。偏差参数默认会初始化为零。
from mxnet import init
net.initialize(init.Normal(sigma=0.01))
定义损失函数
在Gluon中,loss模块定义了各种损失函数。我们用假名gloss代替导入的loss模块,并直接使用它提供的平方损失作为模型的损失函数。
from mxnet.gluon import loss as gloss
loss = gloss.L2Loss() # 平方损失又称L2范数损失
定义优化算法
同样,我们也无须实现小批量随机梯度下降。在导入Gluon后,我们创建一个Trainer实例,并指定学习率为0.03的小批量随机梯度下降(sgd)为优化算法。该优化算法将用来迭代net实例所有通过add函数嵌套的层所包含的全部参数。这些参数可以通过collect_params函数获取。
from mxnet import gluon
trainer = gluon.Trainer(net.collect_params(), 'sgd', {
'learning_rate': 0.03})
训练模型
在使用Gluon训练模型时,我们通过调用Trainer实例的step函数来迭代模型参数。上一节中我们提到,由于变量l是长度为batch_size的一维NDArray,执行l.backward()等价于执行l.sum().backward()。按照小批量随机梯度下降的定义,我们在step函数中指明批量大小,从而对批量中样本梯度求平均。
num_epochs = 3
for epoch in range(1, num_epochs + 1):
for X, y in data_iter:
with autograd.record():
l = loss(net(X), y)
l.backward()
trainer.step(batch_size)
l = loss(net(features), labels)
print('epoch %d, loss: %f' % (epoch, l.mean().asnumpy()))

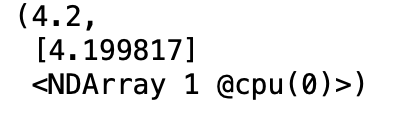
下面我们分别比较学到的模型参数和真实的模型参数。我们从net获得需要的层,并访问其权重(weight)和偏差(bias)。学到的参数和真实的参数很接近。
dense = net[0]
true_w, dense.weight.data()

true_b, dense.bias.data()
- 使用Gluon可以更简洁地实现模型。
- 在Gluon中,
data模块提供了有关数据处理的工具,nn模块定义了大量神经网络的层,loss模块定义了各种损失函数。 - MXNet的
initializer模块提供了模型参数初始化的各种方法。
softmax回归
前几节介绍的线性回归模型适用于输出为连续值的情景。在另一类情景中,模型输出可以是一个像图像类别这样的离散值。对于这样的离散值预测问题,我们可以使用诸如softmax回归在内的分类模型。和线性回归不同,softmax回归的输出单元从一个变成了多个,且引入了softmax运算使输出更适合离散值的预测和训练。本节以softmax回归模型为例,介绍神经网络中的分类模型。
让我们考虑一个简单的图像分类问题,其输入图像的高和宽均为2像素,且色彩为灰度。这样每个像素值都可以用一个标量表示。我们将图像中的4像素分别记为 x 1 , x 2 , x 3 , x 4 x_1, x_2, x_3, x_4 x1,x2,x3,x4。假设训练数据集中图像的真实标签为狗、猫或鸡(假设可以用4像素表示出这3种动物),这些标签分别对应离散值 y 1 , y 2 , y 3 y_1, y_2, y_3 y1,y2,y3。
我们通常使用离散的数值来表示类别,例如 y 1 = 1 , y 2 = 2 , y 3 = 3 y_1=1, y_2=2, y_3=3 y1=1,y2=2,y3=3。如此,一张图像的标签为1、2和3这3个数值中的一个。虽然我们仍然可以使用回归模型来进行建模,并将预测值就近定点化到1、2和3这3个离散值之一,但这种连续值到离散值的转化通常会影响到分类质量。因此我们一般使用更加适合离散值输出的模型来解决分类问题。
softmax回归跟线性回归一样将输入特征与权重做线性叠加。与线性回归的一个主要不同在于,softmax回归的输出值个数等于标签里的类别数。因为一共有4种特征和3种输出动物类别,所以权重包含12个标量(带下标的 w w w)、偏差包含3个标量(带下标的 b b b),且对每个输入计算 o 1 , o 2 , o 3 o_1, o_2, o_3 o1,o2,o3这3个输出:
o 1 = x 1 w 11 + x 2 w 21 + x 3 w 31 + x 4 w 41 + b 1 , o 2 = x 1 w 12 + x 2 w 22 + x 3 w 32 + x 4 w 42 + b 2 , o 3 = x 1 w 13 + x 2 w 23 + x 3 w 33 + x 4 w 43 + b 3 . \begin{aligned} o_1 &= x_1 w_{11} + x_2 w_{21} + x_3 w_{31} + x_4 w_{41} + b_1,\\ o_2 &= x_1 w_{12} + x_2 w_{22} + x_3 w_{32} + x_4 w_{42} + b_2,\\ o_3 &= x_1 w_{13} + x_2 w_{23} + x_3 w_{33} + x_4 w_{43} + b_3. \end{aligned} o1o2o3=x1w11+x2w21+x3w31+x4w41+b1,=x1w12+x2w22+x3w32+x4w42+b2,=x1w13+x2w23+x3w33+x4w43+b3.
softmax运算
既然分类问题需要得到离散的预测输出,一个简单的办法是将输出值 o i o_i oi当作预测类别是 i i i的置信度,并将值最大的输出所对应的类作为预测输出,即输出 * a r g m a x i o i \operatorname*{argmax}_i o_i *argmaxioi。例如,如果 o 1 , o 2 , o 3 o_1,o_2,o_3 o1,o2,o3分别为 0.1 , 10 , 0.1 0.1,10,0.1 0.1,10,0.1,由于 o 2 o_2 o2最大,那么预测类别为2,其代表猫。
然而,直接使用输出层的输出有两个问题。一方面,由于输出层的输出值的范围不确定,我们难以直观上判断这些值的意义。例如,刚才举的例子中的输出值10表示“很置信”图像类别为猫,因为该输出值是其他两类的输出值的100倍。但如果 o 1 = o 3 = 1 0 3 o_1=o_3=10^3 o1=o3=103,那么输出值10却又表示图像类别为猫的概率很低。另一方面,由于真实标签是离散值,这些离散值与不确定范围的输出值之间的误差难以衡量。
softmax运算符(softmax operator)解决了以上两个问题。它通过下式将输出值变换成值为正且和为1的概率分布:
y ^ 1 , y ^ 2 , y ^ 3 = softmax ( o 1 , o 2 , o 3 ) , \hat{y}_1, \hat{y}_2, \hat{y}_3 = \text{softmax}(o_1, o_2, o_3), y^1,y^2,y^3=softmax(o1,o2,o3),
其中
y ^ 1 = exp ( o 1 ) ∑ i = 1 3 exp ( o i ) , y ^ 2 = exp ( o 2 ) ∑ i = 1 3 exp ( o i ) , y ^ 3 = exp ( o 3 ) ∑ i = 1 3 exp ( o i ) . \hat{y}_1 = \frac{ \exp(o_1)}{\sum_{i=1}^3 \exp(o_i)},\quad \hat{y}_2 = \frac{ \exp(o_2)}{\sum_{i=1}^3 \exp(o_i)},\quad \hat{y}_3 = \frac{ \exp(o_3)}{\sum_{i=1}^3 \exp(o_i)}. y^1=∑i=13exp(oi)exp(o1),y^2=∑i=13exp(oi)exp(o2),y^3=∑i=13exp(oi)exp(o3).
交叉熵损失函数
前面提到,使用softmax运算后可以更方便地与离散标签计算误差。我们已经知道,softmax运算将输出变换成一个合法的类别预测分布。实际上,真实标签也可以用类别分布表达:对于样本 i i i,我们构造向量 y ( i ) ∈ R q \boldsymbol{y}^{(i)}\in \mathbb{R}^{q} y(i)∈Rq ,使其第 y ( i ) y^{(i)} y(i)(样本 i i i类别的离散数值)个元素为1,其余为0。这样我们的训练目标可以设为使预测概率分布 y ^ ( i ) \boldsymbol{\hat y}^{(i)} y^(i)尽可能接近真实的标签概率分布 y ( i ) \boldsymbol{y}^{(i)} y(i)。
改善上述问题的一个方法是使用更适合衡量两个概率分布差异的测量函数。其中,交叉熵(cross entropy)是一个常用的衡量方法:
H ( y ( i ) , y ^ ( i ) ) = − ∑ j = 1 q y j ( i ) log y ^ j ( i ) , H\left(\boldsymbol y^{(i)}, \boldsymbol {\hat y}^{(i)}\right ) = -\sum_{j=1}^q y_j^{(i)} \log \hat y_j^{(i)}, H(y(i),y^(i))=−j=1∑qyj(i)logy^j(i),
其中带下标的 y j ( i ) y_j^{(i)} yj(i)是向量 y ( i ) \boldsymbol y^{(i)} y(i)中非0即1的元素,需要注意将它与样本 i i i类别的离散数值,即不带下标的 y ( i ) y^{(i)} y(i)区分。在上式中,我们知道向量 y ( i ) \boldsymbol y^{(i)} y(i)中只有第 y ( i ) y^{(i)} y(i)个元素 y y ( i ) ( i ) y^{(i)}_{y^{(i)}} yy(i)(i)为1,其余全为0,于是 H ( y ( i ) , y ^ ( i ) ) = − log y ^ y ( i ) ( i ) H(\boldsymbol y^{(i)}, \boldsymbol {\hat y}^{(i)}) = -\log \hat y_{y^{(i)}}^{(i)} H(y(i),y^(i))=−logy^y(i)(i)。也就是说,交叉熵只关心对正确类别的预测概率,因为只要其值足够大,就可以确保分类结果正确。当然,遇到一个样本有多个标签时,例如图像里含有不止一个物体时,我们并不能做这一步简化。但即便对于这种情况,交叉熵同样只关心对图像中出现的物体类别的预测概率。
假设训练数据集的样本数为 n n n,交叉熵损失函数定义为
ℓ ( Θ ) = 1 n ∑ i = 1 n H ( y ( i ) , y ^ ( i ) ) , \ell(\boldsymbol{\Theta}) = \frac{1}{n} \sum_{i=1}^n H\left(\boldsymbol y^{(i)}, \boldsymbol {\hat y}^{(i)}\right ), ℓ(Θ)=n1i=1∑nH(y(i),y^(i)),
其中 Θ \boldsymbol{\Theta} Θ代表模型参数。同样地,如果每个样本只有一个标签,那么交叉熵损失可以简写成 ℓ ( Θ ) = − ( 1 / n ) ∑ i = 1 n log y ^ y ( i ) ( i ) \ell(\boldsymbol{\Theta}) = -(1/n) \sum_{i=1}^n \log \hat y_{y^{(i)}}^{(i)} ℓ(Θ)=−(1/n)∑i=1nlogy^y(i)(i)。从另一个角度来看,我们知道最小化 ℓ ( Θ ) \ell(\boldsymbol{\Theta}) ℓ(Θ)等价于最大化 exp ( − n ℓ ( Θ ) ) = ∏ i = 1 n y ^ y ( i ) ( i ) \exp(-n\ell(\boldsymbol{\Theta}))=\prod_{i=1}^n \hat y_{y^{(i)}}^{(i)} exp(−nℓ(Θ))=∏i=1ny^y(i)(i),即最小化交叉熵损失函数等价于最大化训练数据集所有标签类别的联合预测概率。
模型预测及评价
在训练好softmax回归模型后,给定任一样本特征,就可以预测每个输出类别的概率。通常,我们把预测概率最大的类别作为输出类别。如果它与真实类别(标签)一致,说明这次预测是正确的。
- softmax回归适用于分类问题。它使用softmax运算输出类别的概率分布。
- softmax回归是一个单层神经网络,输出个数等于分类问题中的类别个数。
- 交叉熵适合衡量两个概率分布的差异。
softmax回归的简单实现
获取和读取数据
我们仍然使用Fashion-MNIST数据集和上一节中设置的批量大小。
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
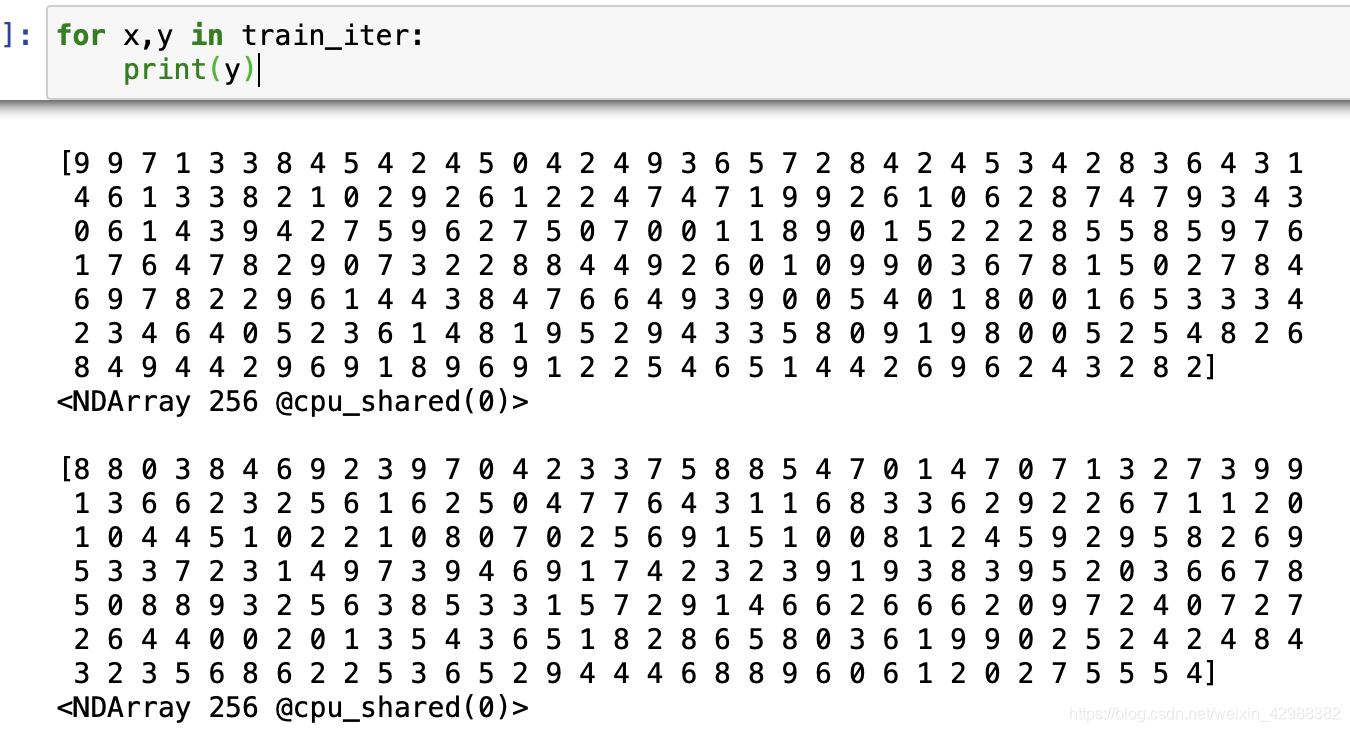
x是数据,y是标签。
定义和初始化模型
softmax回归的输出层是一个全连接层。因此,我们添加一个输出个数为10的全连接层。我们使用均值为0、标准差为0.01的正态分布随机初始化模型的权重参数。
net = nn.Sequential()
net.add(nn.Dense(10))
net.initialize(init.Normal(sigma=0.01))
softmax和交叉熵损失函数
分开定义softmax运算和交叉熵损失函数可能会造成数值不稳定。因此,Gluon提供了一个包括softmax运算和交叉熵损失计算的函数。它的数值稳定性更好。
loss = gloss.SoftmaxCrossEntropyLoss()
定义优化算法
我们使用学习率为0.1的小批量随机梯度下降作为优化算法。
trainer = gluon.Trainer(net.collect_params(), 'sgd', {
'learning_rate': 0.1})
训练模型
接下来,我们使用训练函数来训练模型。
num_epochs = 5
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, None,
None, trainer)
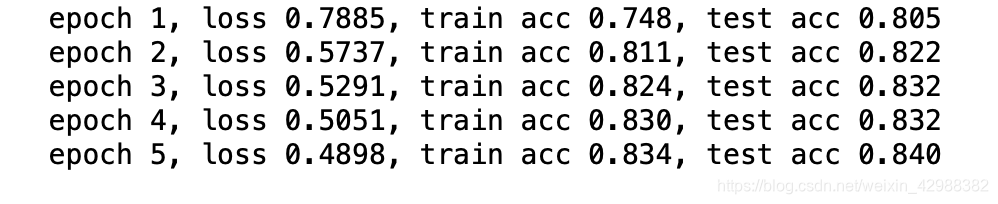
- Gluon提供的函数往往具有更好的数值稳定性。
- 可以使用Gluon更简洁地实现softmax回归。
Fashion-MNIST介绍
在介绍softmax回归的实现前我们先引入一个多类图像分类数据集。它将在后面的章节中被多次使用,以方便我们观察比较算法之间在模型精度和计算效率上的区别。图像分类数据集中最常用的是手写数字识别数据集MNIST。但大部分模型在MNIST上的分类精度都超过了95%。为了更直观地观察算法之间的差异,我们将使用一个图像内容更加复杂的Fashion-MNIST数据集。
首先先导入需要的包:
%matplotlib inline
import d2lzh as d2l
from mxnet.gluon import data as gdata
import sys
import time
下面通过Gluon来下载数据集:
mnist_train = gdata.vision.FashionMNIST(train=True)
mnist_test = gdata.vision.FashionMNIST(train=False)
训练集中和测试集中的每个类别的图像数分别为6,000和1,000。因为有10个类别,所以训练集和测试集的样本数分别为60,000和10,000

我们可以通过方括号[]来访问任意一个样本,下面获取第一个样本的图像和标签。
feature, label = mnist_train[0]
变量feature对应高和宽均为28像素的图像。每个像素的数值为0到255之间8位无符号整数(uint8)。它使用三维的NDArray存储。其中的最后一维是通道数。因为数据集中是灰度图像,所以通道数为1。为了表述简洁,我们将高和宽分别为 h h h和 w w w像素的图像的形状记为 h × w h \times w h×w或(h,w)。

dtype查看数组元素的类型,type是该数组的类型。
Fashion-MNIST中一共包括了10个类别,分别为t-shirt(T恤)、trouser(裤子)、pullover(套衫)、dress(连衣裙)、coat(外套)、sandal(凉鞋)、shirt(衬衫)、sneaker(运动鞋)、bag(包)和ankle boot(短靴)。以下函数可以将数值标签转成相应的文本标签。
# 本函数已保存在d2lzh包中方便以后使用
def get_fashion_mnist_labels(labels):
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
下面定义一个可以在一行里画出多张图像和对应标签的函数。
# 本函数已保存在d2lzh包中方便以后使用
def show_fashion_mnist(images, labels):
d2l.use_svg_display()
# 这里的_表示我们忽略(不使用)的变量
_, figs = d2l.plt.subplots(1, len(images), figsize=(12, 12))
for f, img, lbl in zip(figs, images, labels):
f.imshow(img.reshape((28, 28)).asnumpy())
f.set_title(lbl)
f.axes.get_xaxis().set_visible(False)
f.axes.get_yaxis().set_visible(False)
现在,我们看一下训练数据集中前9个样本的图像内容和文本标签。

读取批量数据
我们将在训练数据集上训练模型,并将训练好的模型在测试数据集上评价模型的表现。虽然我们可以通过yield来定义读取小批量数据样本的函数,但为了代码简洁,这里我们直接创建DataLoader实例。该实例每次读取一个样本数为batch_size的小批量数据。这里的批量大小batch_size是一个超参数。
在实践中,数据读取经常是训练的性能瓶颈,特别当模型较简单或者计算硬件性能较高时。Gluon的DataLoader中一个很方便的功能是允许使用多进程来加速数据读取(暂不支持Windows操作系统)。这里我们通过参数num_workers来设置4个进程读取数据。
此外,我们通过ToTensor实例将图像数据从uint8格式变换成32位浮点数格式,并除以255使得所有像素的数值均在0到1之间。ToTensor实例还将图像通道从最后一维移到最前一维来方便之后介绍的卷积神经网络计算。通过数据集的transform_first函数,我们将ToTensor的变换应用在每个数据样本(图像和标签)的第一个元素,即图像之上。
batch_size = 256
transformer = gdata.vision.transforms.ToTensor()
if sys.platform.startswith('win'):
num_workers = 0 # 0表示不用额外的进程来加速读取数据
else:
num_workers = 4
train_iter = gdata.DataLoader(mnist_train.transform_first(transformer),
batch_size, shuffle=True,
num_workers=num_workers)
test_iter = gdata.DataLoader(mnist_test.transform_first(transformer),
batch_size, shuffle=False,
num_workers=num_workers)
我们将获取并读取Fashion-MNIST数据集的逻辑封装在d2lzh.load_data_fashion_mnist函数中。该函数将返回train_iter和test_iter两个变量。我们会进一步改进该函数。
- Fashion-MNIST是一个10类服饰分类数据集,之后章节里将使用它来检验不同算法的表现。
- 我们将高和宽分别为 h h h和 w w w像素的图像的形状记为 h × w h \times w h×w或
(h,w)。
多层感知机
多层感知机就是含有至少一个隐藏层的由全连接层组成的神经网络,且每个隐藏层的输出通过激活函数进行变换。多层感知机的层数和各隐藏层中隐藏单元个数都是超参数。以单隐藏层为例并沿用本节之前定义的符号,多层感知机按以下方式计算输出:
H = ϕ ( X W h + b h ) , O = H W o + b o , \begin{aligned} \boldsymbol{H} &= \phi(\boldsymbol{X} \boldsymbol{W}_h + \boldsymbol{b}_h),\\ \boldsymbol{O} &= \boldsymbol{H} \boldsymbol{W}_o + \boldsymbol{b}_o, \end{aligned} HO=ϕ(XWh+bh),=HWo+bo,
其中 ϕ \phi ϕ表示激活函数。在分类问题中,我们可以对输出 O \boldsymbol{O} O做softmax运算,并使用softmax回归中的交叉熵损失函数。
在回归问题中,我们将输出层的输出个数设为1,并将输出 O \boldsymbol{O} O直接提供给线性回归中使用的平方损失函数。
多层感知机的简单实现
import d2lzh as d2l
from mxnet import gluon, init
from mxnet.gluon import loss as gloss, nn
定义模型
net = nn.Sequential()
net.add(nn.Dense(256, activation='relu'))
net.add(nn.Dense(10))
net.initialize(init.Normal(sigma=0.01))
训练模型
我们使用与训练softmax回归几乎相同的步骤来读取数据并训练模型。
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
loss = gloss.SoftmaxCrossEntropyLoss()
trainer = gluon.Trainer(net.collect_params(), 'sgd', {
'learning_rate': 0.5})
num_epochs = 5
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, None,
None, trainer)
权重衰减(正则化)
上一节中我们观察了过拟合现象,即模型的训练误差远小于它在测试集上的误差。虽然增大训练数据集可能会减轻过拟合,但是获取额外的训练数据往往代价高昂。本节介绍应对过拟合问题的常用方法:权重衰减(weight decay)。
方法
权重衰减等价于 L 2 L_2 L2范数正则化(regularization)。正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。我们先描述 L 2 L_2 L2范数正则化,再解释它为何又称权重衰减。
L 2 L_2 L2范数正则化在模型原损失函数基础上添加 L 2 L_2 L2范数惩罚项,从而得到训练所需要最小化的函数。 L 2 L_2 L2范数惩罚项指的是模型权重参数每个元素的平方和与一个正的常数的乘积。以“线性回归”一节中的线性回归损失函数
ℓ ( w 1 , w 2 , b ) = 1 n ∑ i = 1 n 1 2 ( x 1 ( i ) w 1 + x 2 ( i ) w 2 + b − y ( i ) ) 2 \ell(w_1, w_2, b) = \frac{1}{n} \sum_{i=1}^n \frac{1}{2}\left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right)^2 ℓ(w1,w2,b)=n1i=1∑n21(x1(i)w1+x2(i)w2+b−y(i))2
为例,其中 w 1 , w 2 w_1, w_2 w1,w2是权重参数, b b b是偏差参数,样本 i i i的输入为 x 1 ( i ) , x 2 ( i ) x_1^{(i)}, x_2^{(i)} x1(i),x2(i),标签为 y ( i ) y^{(i)} y(i),样本数为 n n n。将权重参数用向量 w = [ w 1 , w 2 ] \boldsymbol{w} = [w_1, w_2] w=[w1,w2]表示,带有 L 2 L_2 L2范数惩罚项的新损失函数为
ℓ ( w 1 , w 2 , b ) + λ 2 n ∥ w ∥ 2 , \ell(w_1, w_2, b) + \frac{\lambda}{2n} \|\boldsymbol{w}\|^2, ℓ(w1,w2,b)+2nλ∥w∥2,
其中超参数 λ > 0 \lambda > 0 λ>0。当权重参数均为0时,惩罚项最小。当 λ \lambda λ较大时,惩罚项在损失函数中的比重较大,这通常会使学到的权重参数的元素较接近0。当 λ \lambda λ设为0时,惩罚项完全不起作用。上式中 L 2 L_2 L2范数平方 ∥ w ∥ 2 \|\boldsymbol{w}\|^2 ∥w∥2展开后得到 w 1 2 + w 2 2 w_1^2 + w_2^2 w12+w22。有了 L 2 L_2 L2范数惩罚项后,在小批量随机梯度下降中,我们将“线性回归“中权重 w 1 w_1 w1和 w 2 w_2 w2的迭代方式更改为
w 1 ← ( 1 − η λ ) w 1 − η ∣ B ∣ ∑ i ∈ B x 1 ( i ) ( x 1 ( i ) w 1 + x 2 ( i ) w 2 + b − y ( i ) ) , w 2 ← ( 1 − η λ ) w 2 − η ∣ B ∣ ∑ i ∈ B x 2 ( i ) ( x 1 ( i ) w 1 + x 2 ( i ) w 2 + b − y ( i ) ) . \begin{aligned} w_1 &\leftarrow \left(1- \eta\lambda \right)w_1 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}x_1^{(i)} \left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right),\\ w_2 &\leftarrow \left(1- \eta\lambda \right)w_2 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}x_2^{(i)} \left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right). \end{aligned} w1w2←(1−ηλ)w1−∣B∣ηi∈B∑x1(i)(x1(i)w1+x2(i)w2+b−y(i)),←(1−ηλ)w2−∣B∣ηi∈B∑x2(i)(x1(i)w1+x2(i)w2+b−y(i)).
可见, L 2 L_2 L2范数正则化令权重 w 1 w_1 w1和 w 2 w_2 w2先自乘小于1的数,再减去不含惩罚项的梯度。因此, L 2 L_2 L2范数正则化又叫权重衰减。权重衰减通过惩罚绝对值较大的模型参数为需要学习的模型增加了限制,这可能对过拟合有效。实际场景中,我们有时也在惩罚项中添加偏差元素的平方和。
在和以前的处理数据方法对接时也可采用,现在DataFrame中操作,然后通过.values得到numpy类型,再通过nd.array来转换为mxnet能输入的形式
n_train = train_data.shape[0]
train_features = nd.array(all_features[:n_train].values)
test_features = nd.array(all_features[n_train:].values)
train_labels = nd.array(train_data.SalePrice.values).reshape((-1, 1))
注:这里-1相当于是个任意值,这个reshape是把数据变成1列,但具体多少行都行。