基本的决策树知识不再赘述,只记录难点
决策树节点的划分依据:
1.基于信息增益的划分(ID3算法:信息增益;C4.5算法:信息增益率)
2.基于基尼系数的划分(CART算法)(更常用)
信息增益的预备知识:信息熵
定义:信息的混杂度,熵值越大,信息越混杂;熵值越小,信息越纯
公式:
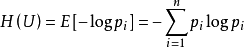
公式解读:
- pi是概率值,取值范围在0-1
- 对于对数函数来说,若定义域是0-1,值域则为负无穷到0.公式中加符号代表相反数,使得结果更直观。
- 若概率值越大,考虑log图像,-logpi越小。
- 所以上述公式可以很好地代表熵的定义。
信息增益:
定义:信息不确定性(熵)的减小程度。
原理:初始熵-条件熵(以某个节点为划分依据时的熵);信息增益越大,节点分类效果越好。
缺点:举例来说:对于ID列(每个ID都不相同,属于稀疏特征,信息混杂度较高),若以ID列作为划分节点,其划分结果必定100%准确(每个ID都能准确的划分出唯一的对应样本),所以条件熵的结果为0,信息增益为初始熵-0,信息增益达到最大。但是这样的划分节点明显没有用处。总结来说,对于稀疏特征来说,信息增益不可靠
信息增益的改进:信息增益率
原理:某个划分节点的信息增益/该节点的信息熵,信息熵越混杂(如ID列,每个ID都不相同),信息熵越大,分母越大,信息增益率越小。通过这种方法,调节了只依靠信息增益的偏差性。
基尼系数
原理类似于熵的原理,只是计算公式不同。概率越大,基尼系数越小,信息纯度越高;概率越小,基尼系数越大,信息杂度越高。
决策树的剪枝:
目的:防止决策树过拟合。
预剪枝(更常用):在决策树生成过程中进行剪枝,剪枝标准有:树的深度、叶子结点的个数、信息增益。可以通过K折交叉验证来选择最佳参数。
后剪枝(了解):在决策树生成后再进行剪枝。
补充:贪心算法将连续变量离散化
对于年龄、身高、体重等连续变量,要实现分类目标,必须划分界值(如身高低于180的为一类,高于180的为另一类)
假设“年龄”变量有3个值:23,34,19
首先对其排序:19,23,34
然后再该序列不同位置依次切刀:19|23,34;19,23|34
分别计算上述两个切分结果的信息增益,信息增益大的作为划分依据(假设19|23,34这个切分结果信息增益较大,就以该切分点作为划分界值,约为20.5岁)
