来自:http://www.cnblogs.com/pinard/p/6053344.html
在决策树算法原理(ID3,C4.5)中,提到C4.5的不足,比如模型是用较为复杂的熵来度量,使用了相对较为复杂的多叉树,只能处理分类不能处理回归。对这些问题,CART做了改进,可以处理分类,也可以处理回归。
1. CART分类树算法的最优特征选择方法
ID3中使用了信息增益选择特征,增益大优先选择。C4.5中,采用信息增益比选择特征,减少因特征值多导致信息增益大的问题。CART分类树算法使用基尼系数来代替信息增益比,基尼系数代表了模型的不纯度,基尼系数越小,不纯度越低,特征越好。这和信息增益(比)相反。
假设K个类别,第k个类别的概率为pk,基尼系数表达式:

如果是二分类问题,第一个样本输出概率为p,基尼系数的表达式为:
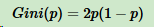
对于样本D,假设K个类别,第k个类别的数量为Ck,则样本D的基尼系数表达式:
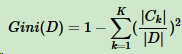
对于样本D,根据特征A的某个值a,把D分成D1和D2,则在特征A的条件下,样本D的基尼系数表达式为:
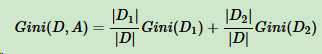
比较基尼系数和熵模型的表达式,二次运算比对数简单很多。尤其是二分类问题,更加简单。
和熵模型的度量方式比,基尼系数对应的误差有多大呢?对于二类分类,基尼系数和熵之半的曲线如下:
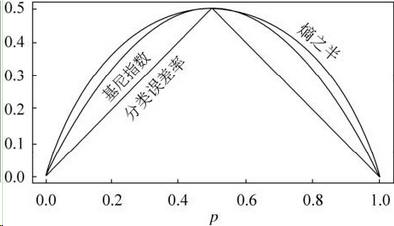
基尼系数和熵之半的曲线非常接近,仅在45度角附近误差稍大。因此,基尼系数可以做为熵模型的一个近似替代。
CART分类树算法每次仅对某个特征的值进行二分,而不是多分,这样CART分类树算法建立起来的是二叉树,而不是多叉树。