一、分类树
1.1特征选择(基尼指数)
在构建cart决策树的时候,是通过选择基尼系数来评价特征的重要性,选择基尼指数最小的来作为划分依据。
基尼指数最早是应用在经济学当中,主要用来衡量收入分配公平度的指标,cart决策树中用它来衡量数据的不纯度或者不确定性。
公式如下:
G i n i ( D ) = 1 − ∑ p i 2 Gini(D)=1-\sum{p_i}^{2} Gini(D)=1−∑pi2
在分类问题中,样本点属于第i类的概率为pi
基尼指数越小,说明数据很纯。
G i n i ( D , a ) = ∑ v ∣ D v ∣ ∣ D ∣ G i n i ( D v ) Gini(D,a)=\sum_{v} \frac{|D_v|}{|D|}Gini(D_v) Gini(D,a)=v∑∣D∣∣Dv∣Gini(Dv)
对于特征A,将集合D划分成D1和D2,基尼指数Gini(D,A)表示经过A=a划分后集合D的不确定性。
上述公式表示某个特征是a时,数据集根据这个特征的取值来划分成两个不同的数据集,在两个数据集中分别计算基尼指数。
1.2建树流程
举个例子:
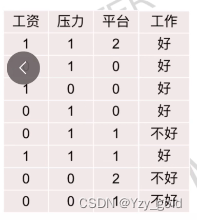
这儿有个数据集
按工资这个特征算,工资中有三个数据是1,5个数据是0,那么可以划分成0,1两个数据集,这两个数据集分别在算基尼指数。注意算基尼系数是针对样本结果来说,这里3个中全部是好,5个中3个好,2个不好.
G i n i ( D , 工 资 ) = 3 8 ( 1 − ( 3 3 ) 2 − ( 0 3 ) 2 + 1 − ( 3 5 ) 2 − ( 2 5 ) 2 ) = 0.3 Gini(D,工资)= \frac{3}{8}(1-(\frac{3}{3})^2-(\frac{0}{3})^2+1-(\frac{3}{5})^2-(\frac{2}{5})^2)=0.3 Gini(D,工资)=83(1−(33)2−(30)2+1−(53)2−(52)2)=0.3
同理可以算的其他的特征:

注意这里面平台这个特征可以取三个值,所以对于每个特征取值的时候,要拆分为平台等于0和平台不等于0这样去计算。
得到所有的值,选择最小的基尼函数的特征作为划分依据。选择工资作为划分标准。
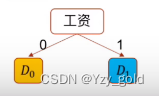
可以发现工资为1的工作都是1。
继续第二轮选择,除开工资,计算其他的特征
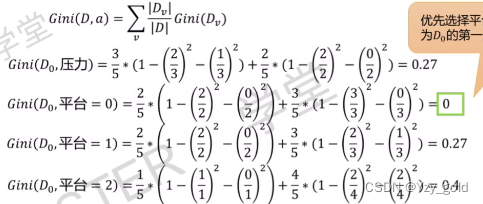
选择平台作为第二层划分的特征。
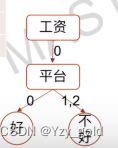
划分到这里之后,发现都是不好的数据了,停止划分,得到如下的一个决策树。

cart算法构造出来的决策树一定是2叉树。
二、回归树
2.1特征选择(平方误差)
回归树和分类树的区别在于标签是否连续,分类树的标签是工作好或者不好,回归树的标签是一系列连续的值来评价工作好坏情况。
回归树采取平方误差来选择特征划分。
如图,一个数据集如下:
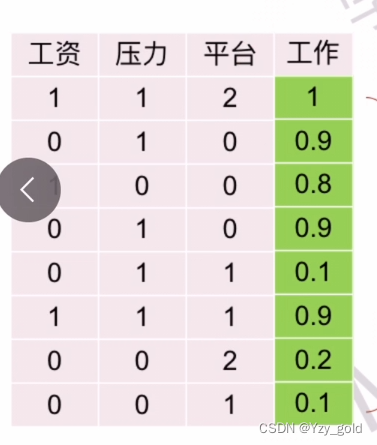
那么平均误差计算为:
可以看到数据的方差乘以数据的长度等于平方误差。
2.2建树流程
遍历所有特征,比如工资可以取0和1,那么可以把数据分为≤0的和大于0的两个数据集,计算两个数据集label的方差。分别乘上两个数据集的长度得到平均误差。
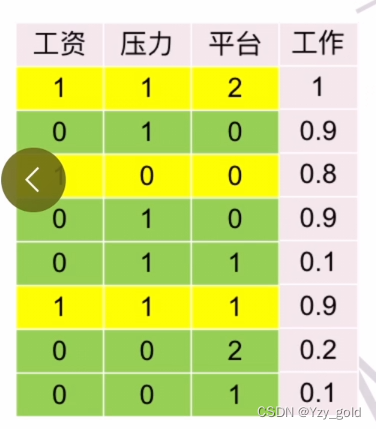
如上图,工资数据分为≤0的数据集的标签方差为0.1421,工资数据大于0的数据集的方差为0.0067,数据长度分别为5和3。得到如下公式。
黄色的部分是工资小于0的,绿色的部分是工资大于0的。

注意平台这个特征,也是要遍历所以特征的值,来把数据划分为两个部分。
可以发现工资的平方误差最小,所以选择工资这个特征作为第一层。
在剩下的数据中继续建树。

选择平台小于0作为划分特征。
直到划分到没有数据,停止建树。
回归树的叶子节点的取值等于该叶子节点里面所有的样本的label的平均值。
关于训练结束的标志:
1.确定叶子节点的个数或者树的深度
2.确定叶子节点包含的样本数
3.给定确定的精度