目录
2.3.1 实现attention机制(要求能够处理变长输入序列)
一 机器翻译及相关技术
机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。 主要特征:输出是单词序列而不是单个单词,且 输出序列的长度可能与源序列的长度不同;输入序列长度可变,输出序列长度可变。
我们来分析一下这些特征,
输入序列长度可变:不能直接使用多层感知机,因为它只能处理固定维度的输入(imput)
输入序列和输出序列长度可能不同:不能直接使用一个RNN
怎么办?Seq2Seq架构!整体上来看,如下图所示
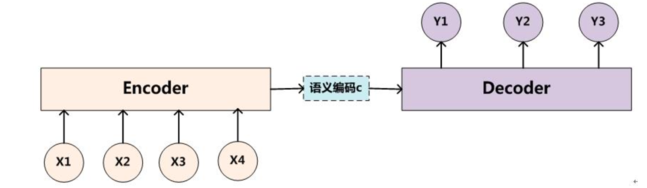
具体结构如下(基于RNN的Seq2Seq):

二 注意力机制与Seq2seq模型
2.1 注意力机制
“ 机器翻译及相关技术”中提到的Seq2Seq是一种静态的条件生成,因为在解码过程,条件永远都是context vector,这样做存在2个缺点:
- 当input的信息很复杂的时候,用一个context vector难以很好的描述这些信息
- 每次decoder都看到一样的东西,生成效果不好;
attention机制出现了,它可以在decoder的每一步只关注对当前词来说重要的信息,是一种动态的条件生成。
三个公式:给定query,(key,value)
在BahdanauAttention和LuongAttention里面,并没有区分key,value,而是一个叫做memory的变量(memory = key = value),(key,value)是在Transformer中出现的。
中score函数的计算方式有三种:
待更新……
2.2 seqseq模型
有了注意力机制加持的seq2seq模型,如下图所示
2.3 动手实践(tensorflow版本)
2.3.1 实现attention机制(要求能够处理变长输入序列)
hint:处理变长序列需要用到sequence mask
三 Transformer
RNN的一些变体捕捉长距离信息依然费力,而Transformer就厉害了,它的自注意力模块理论上可以捕捉任意距离的依赖关系。
学习顺序推荐,亲测可行!
1 推荐博客:图解Transformer(完整版),该博客可以让人对transformer有个初步的整体的了解
2《All attention is your need》是原始论文。
3 自己写代码实现下,若觉得太难,可去github找找相关代码参考下。
3.1 动手实践
这里主要记录一些编程中的二三事~
待更新
3.2 小测验
- 在Transformer模型中,注意力头数为h,嵌入向量和隐藏状态维度均为d,那么一个多头注意力层所含的参数量是
h个注意力头中,每个的参数量为,最后的输出层形状为
,所以参数量共为
。
- 下列对于层归一化叙述错误的是:C(C是批归一化(Batch Normalization)的描述)
A 层归一化有利于加快收敛,减少训练时间成本
B 层归一化对一个中间层的所有神经元进行归一化
C 层归一化对每个神经元的输入数据以mini-batch为单位进行汇总
D 层归一化的效果不会受到batch大小的影响
