一、Seq2seq模型
机器学习实战(第二版)读书笔记(1)——循环神经网络(RNN) 中详细介绍了RNN如下图1所示,可以发现RNN结构大多数对序列长度比较局限,对于机器翻译等任务(输入输出长度不想等N to M),RNN没办法处理,这便有了seq2seq模型,本文以编码器-解码器模型(模型有两部分组成即编码器和解码器)为例。
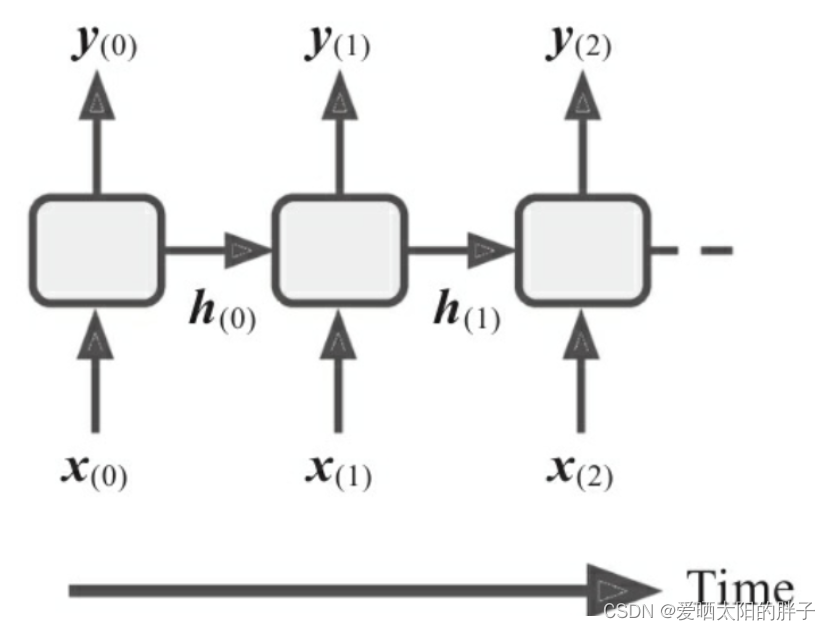
注:RNN在时间步t的输入为(,
) 即(当前时间步输入信息,上一时间步的隐藏状态),状态的传递使得模型具有记忆力,这也是其可以处理序列的原因。并且RNN只能做 1 to n ,n to n,n to 1 任务。
1.1 编码器(Encoder)
编码器一般使用普通的RNN结构,作用是学习输入序列的表征,将输入编码成对任务最有用的向量C(上下文向量)。

上下文向量C的计算方式如下:
- c =
(最后一个时间步的隐藏状态
- c = f(
- c = f(
,
,⋯,
1.2 解码器(Decoder)
解码器一般也是用普通RNN结构,作用是将编码器的输出向量C转换为任务目标输出。根据对C的利用方式的不同可以分成如下几种:
- 上下文向量C只作为解码器第一个时间步的输入。第二个时间步开始以上一时间步的神经元状态作为输入。

图3:示例1 - 解码器时间步t的输入为(
,
)
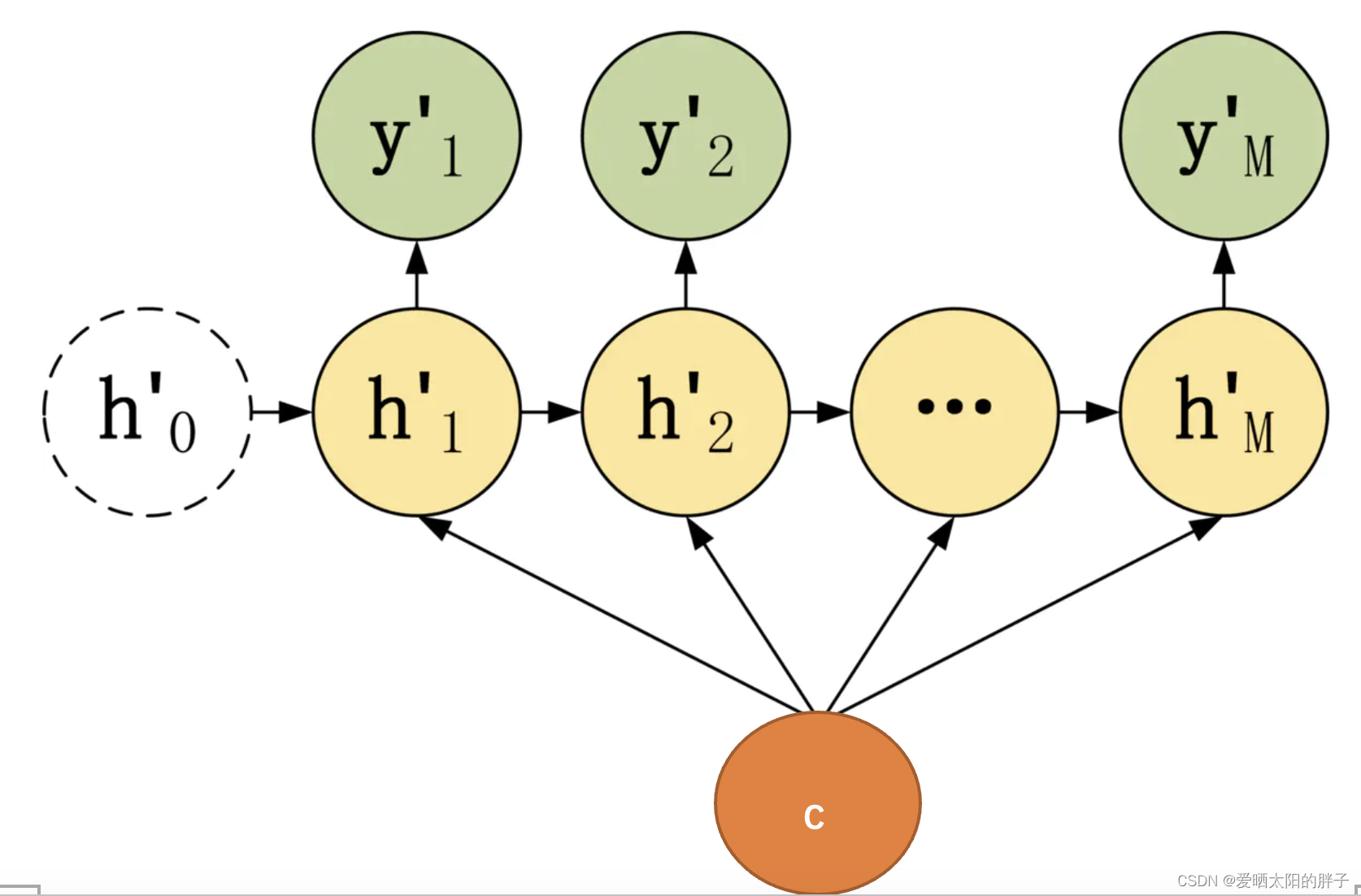
- 解码器时间步t的输入为(
)

存在问题:存在短期记忆问题,当序列过长C表征输入序列能力下降,并存在梯度消失等问题。下面要说的注意力机制可以缓解这种问题。
二、注意力机制
前言
注意力机制由一种称为对齐模型(或注意力层)的小型神经网络生成,该网络与整个模型一起训练,可以缓解RNN短期记忆的问题。BahdanauAttention和LuongAttention论文提出的attention机制都是基于机器翻译,当然也可以应用于其他领域,如推荐系统。
2.1 Bahdanau Attention
链接:NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
2.1.1 编码器
Bahdanau的encoder部分,使用的是双重循环神经网络,神经单元是GRU。论文中对每个时间步输出的两个隐藏状态做的是连接。
2.1.2 解码器
本论文中解码器在时间步t的输入为(,
,
)即(上一次预测结果,时间步t-1隐藏状态,时间不t上下文)。可以发现
是有下标的,和上文介绍的不太一样。这是为什么呢?因为每个步都是不一样的,接下来让我们看看
是怎么计算的。
其中
是编码器生成的隐藏状态序列,可见
是编码器隐藏状态的加权求和。
原文中计算过程描述如下:

上图操作,可以图8的神经网络实现:

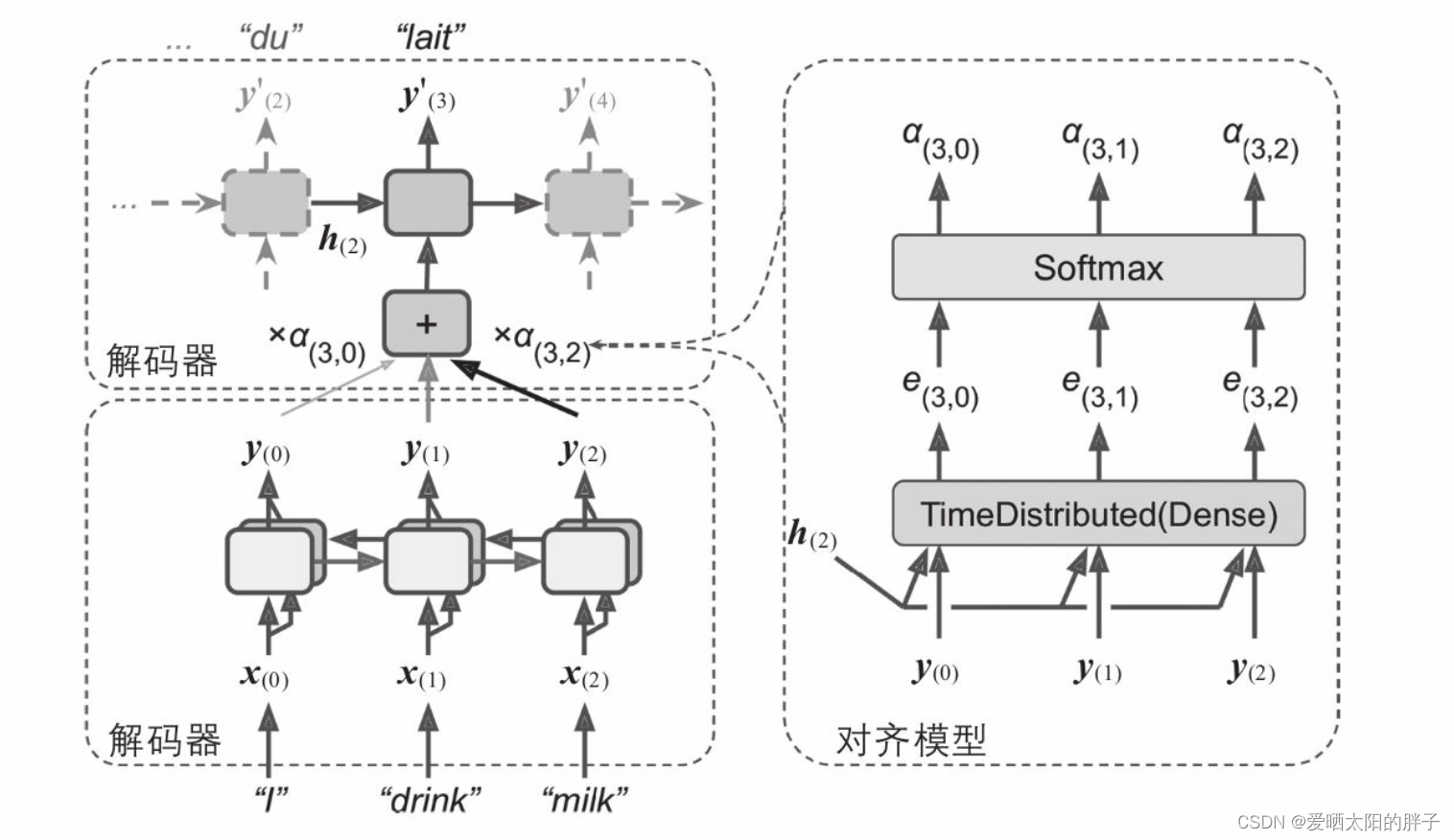
2.1.3 示例
下图为使用了Bahdanau 注意力的编码器-解码器网络在机器翻译上的使用。解码器的输入为
(,
),可发现编码器隐藏状态经过变过后得到
再送入解码器。
2.2 Luong Attention
Luong等人在2015年发表的论文中提出由于注意力机制的目的是测量编码器的输出之一与解码器的先前隐藏状态之间的相似性,因此作者提出了简单地计算这两个向量的点积。作为在本论文中提出两种注意力机制:global attention、local attention。
链接:Effective Approaches to Attention-based Neural Machine Translation
2.2.1 Luong Attention 模型
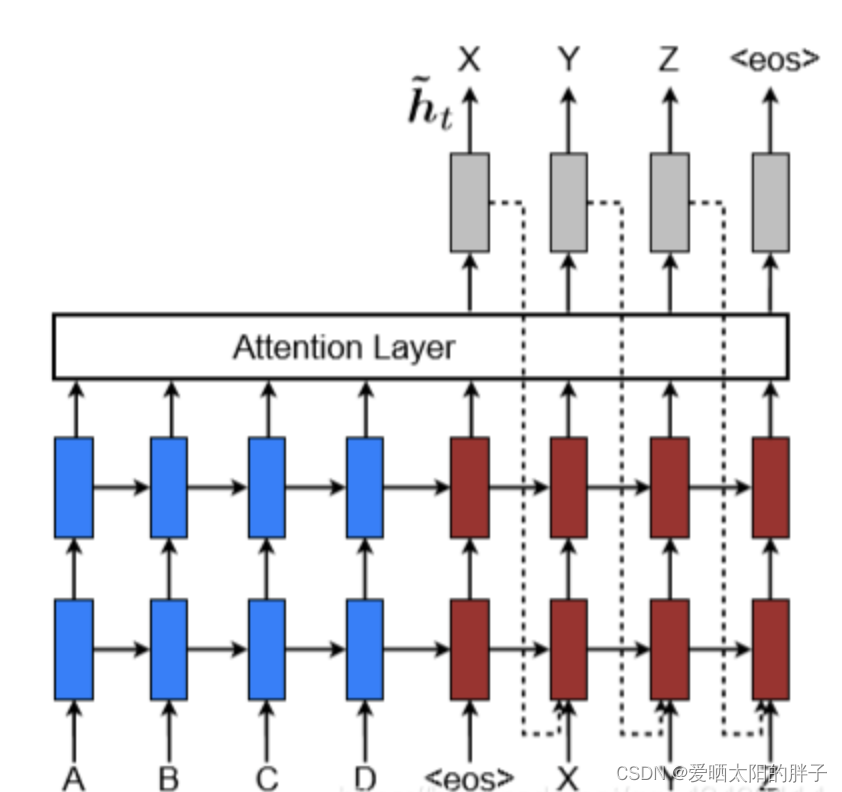
Luong在encoder-decoder模型中使用的是两层单向循环神经网络且神经单元为LSTM,如下图(蓝色部分为编码器,红色为解码器)。解码器的输入为 (,
),注意该模型的输入为上下文向量
和当前时刻的解码器隐藏状态
,可发现编码器隐藏状态未经过变换直接送入解码器(不是很好理解),这是与Bahdanau注意力区别之一。
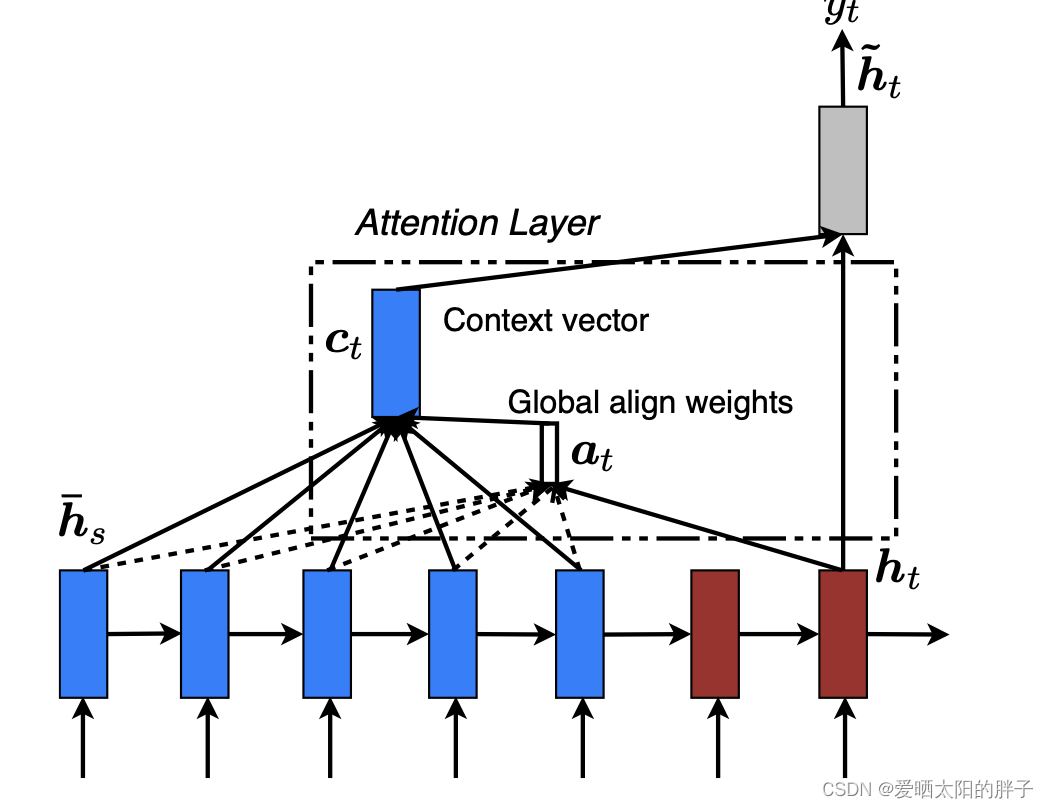
2.2.2 global attention
global attention考虑 encode所有隐藏状态,如下图11所示。
论文中给出的权重(weights) 计算公式如下,并给出了三种score计算方式
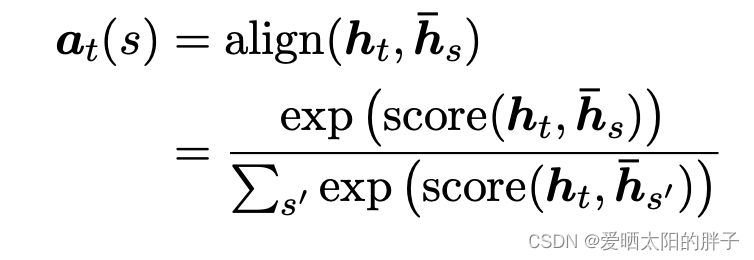
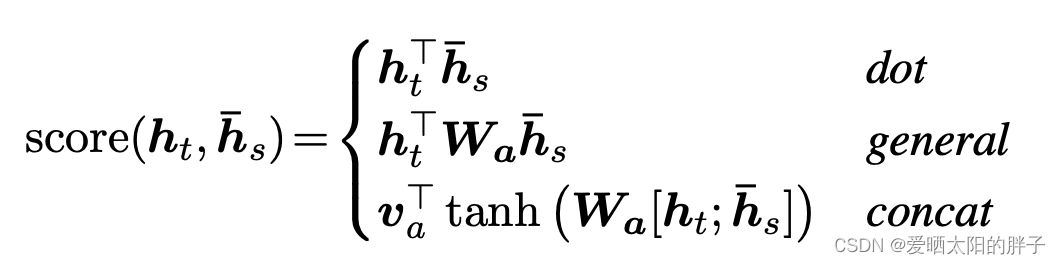
缺点:在预测很长的句子的时候,其预测结果可能会不符合文意。所以又提出了local attention
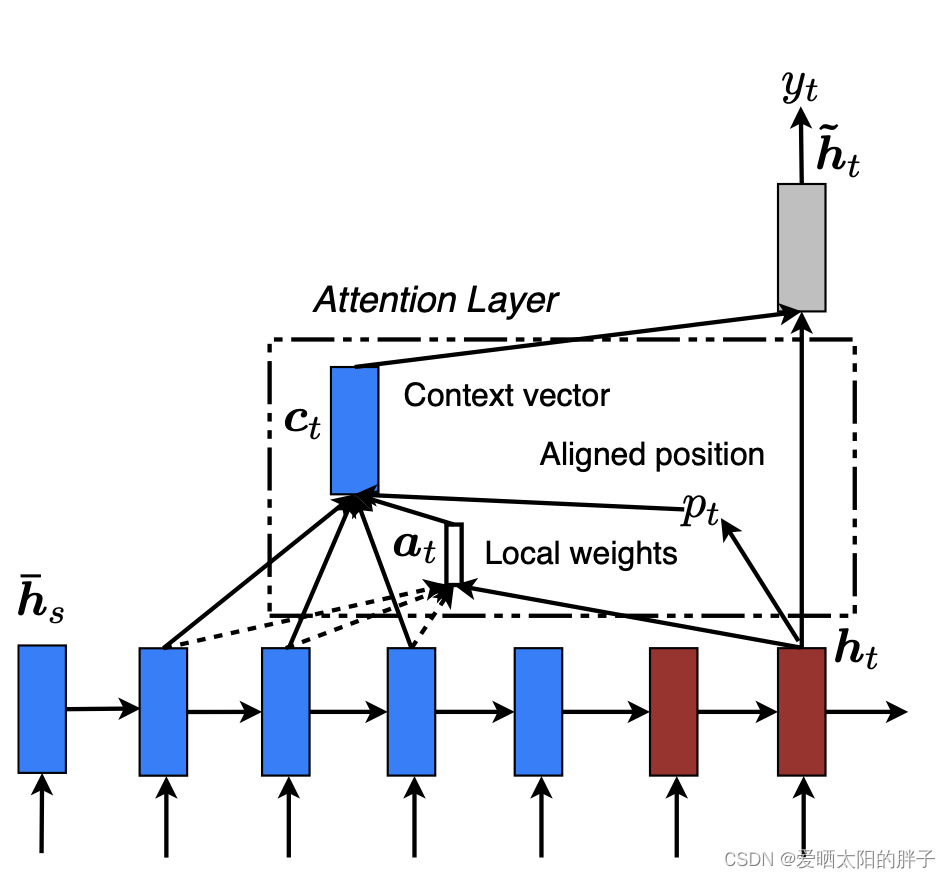
2.2.2 local attention
local注意力只关注编码器输出的隐藏状态的一部分。模型首先为每一个目标单词生成一个aligned position(),它是一个整数并且取值范围为[0,L](L为编码器隐藏状态的长度),解码阶段只关心
[-D,
+D]窗口范围内的encode隐藏状态(D根据经验设置)。