5月25日更新:新图形(RNN动画,文字嵌入图),颜色编码,详细阐述了最后的注意事例。
**注意:**下面的动画是视频。 触摸或悬停它们(如果您使用鼠标)以获得播放控件,以便您可以根据需要暂停。
序列到序列模型是深度学习模型,在机器翻译,文本摘要和图像字幕等任务中取得了很大成功。 谷歌翻译在2016年底开始在生产中使用这种模型。这两个模型在两篇开创性的论文中进行了解释(Sutskever等,2014,Cho等,2014)。
然而,我发现,充分理解模型以实现它需要解开(unraveling)一系列相互叠加的概念。 我认为,如果以视觉方式表达,那么这些想法会更容易获得。 这就是我在这篇文章中(in this post)的目标。 您需要先前了解深度学习才能完成这篇文章。 我希望它能够成为阅读上述论文的有用伴侣(以及后期关注的论文)。
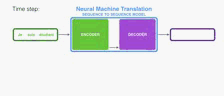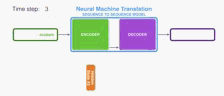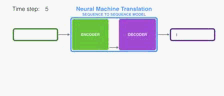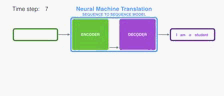
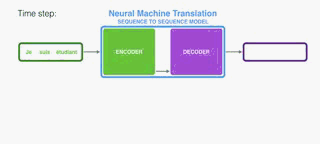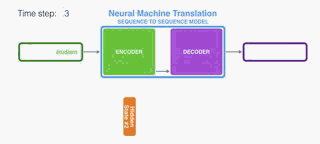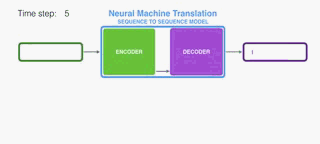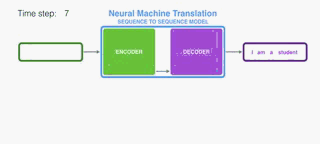
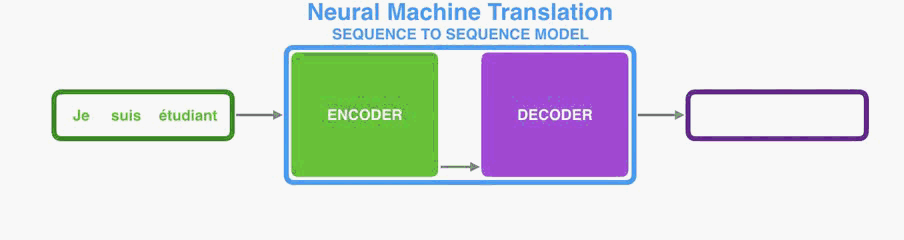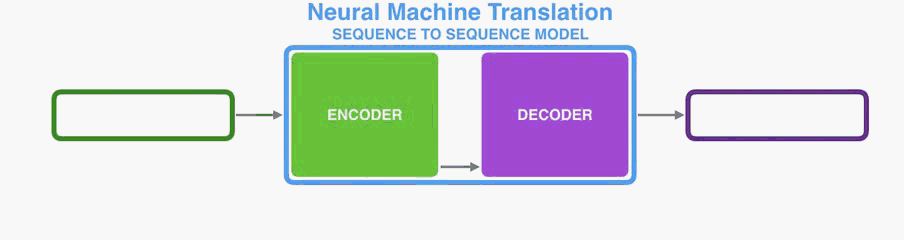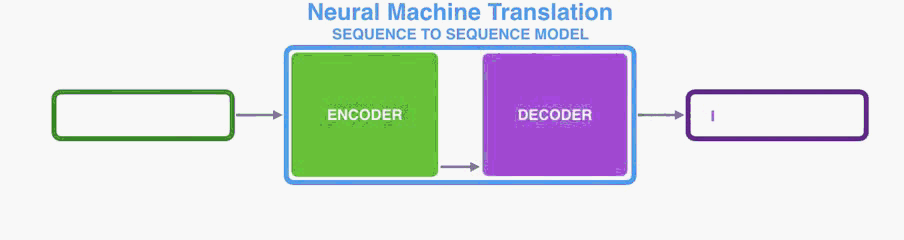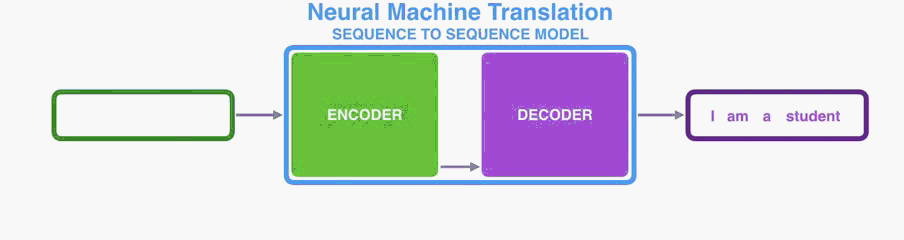
序列到序列模型是一个模型,它采用一系列items (单词,字母,图像的特征等)并输出另一个项目序列。 经过训练的模型可以这样工作:

在神经机器翻译中,序列是一系列单词,一个接一个地处理。 输出同样是一系列的词:

Looking under the hood
Under the hood, the model is composed of an encoder and a decoder.
在引擎盖下,该模型由编码器和解码器组成。
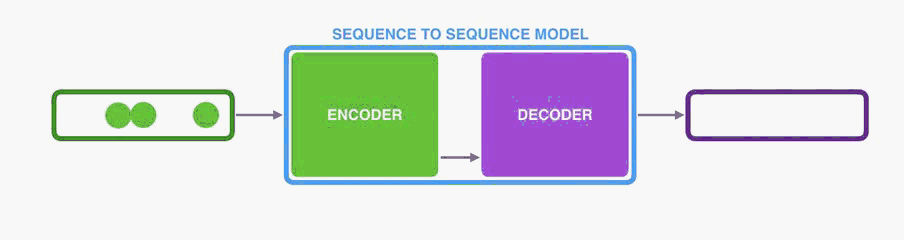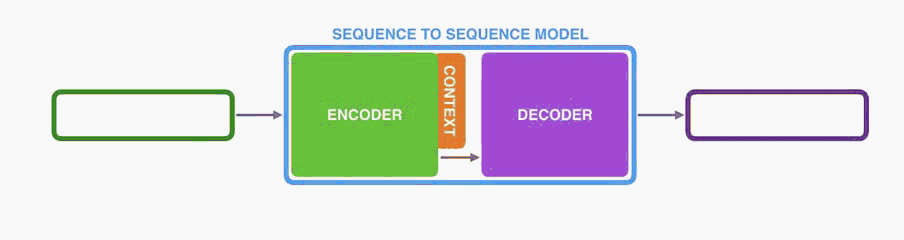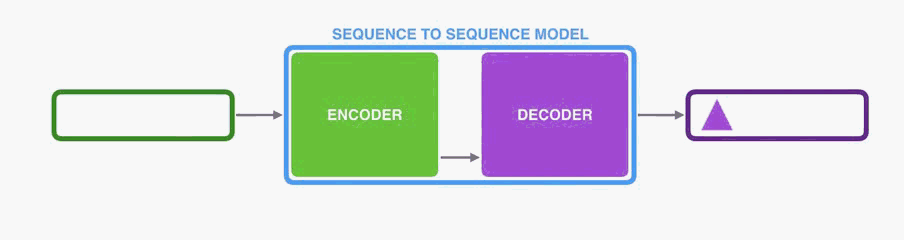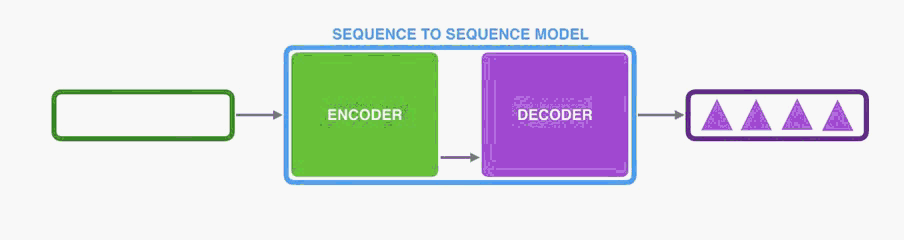
The encoder processes each item in the input sequence, it compiles the information it captures into a vector (called the context). After processing the entire input sequence, the encoder send the context over to the decoder, which begins producing the output sequence item by item.
编码器处理输入序列中的每个项目,它将捕获的信息编译成向量(称为上下文)。 在处理整个输入序列之后,编码器将上下文发送到解码器,解码器逐项开始产生输出序列。
he same applies in the case of machine translation.
他同样适用于机器翻译。
The context is a vector (an array of numbers, basically) in the case of machine translation. The encoder and decoder tend to both be recurrent neural networks (Be sure to check out Luis Serrano’s A friendly introduction to Recurrent Neural Networks for an intro to RNNs).
在机器翻译的情况下,上下文是向量(基本上是数字的数组)。 编码器和解码器往往都是循环神经网络(请务必查看路易斯·塞拉诺对回归神经网络的友好介绍以了解RNN的介绍)

The context is a vector of floats. Later in this post we will visualize vectors in color by assigning brighter colors to the cells with higher values.
上下文是浮点数的向量。 在本文后面,我们将通过为具有更高值的单元格指定更亮的颜色来可视化颜色的矢量。
You can set the size of the context vector when you set up your model. It is basically the number of hidden units in the encoder RNN. These visualizations show a vector of size 4, but in real world applications the context vector would be of a size like 256, 512, or 1024.
您可以在设置模型时设置上下文向量的大小。 它基本上是编码器RNN中隐藏单元的数量。 这些可视化显示了大小为4的向量,但在实际应用中,上下文向量的大小将为256,512或1024。
By design, a RNN takes two inputs at each time step: an input (in the case of the encoder, one word from the input sentence), and a hidden state. The word, however, needs to be represented by a vector. To transform a word into a vector, we turn to the class of methods called “word embedding” algorithms. These turn words into vector spaces that capture a lot of the meaning/semantic information of the words (e.g. king - man + woman = queen).
通过设计,RNN在每个时间步进行两个输入:输入(在编码器的情况下,输入句子中的一个单词)和隐藏状态。 然而,这个词需要用矢量来表示。 为了将单词转换为向量,我们转向称为“单词嵌入”算法的方法类。 这些将单词转换为向量空间,捕获单词的许多含义/语义信息(例如,王者 - 男人+女人=女王)。
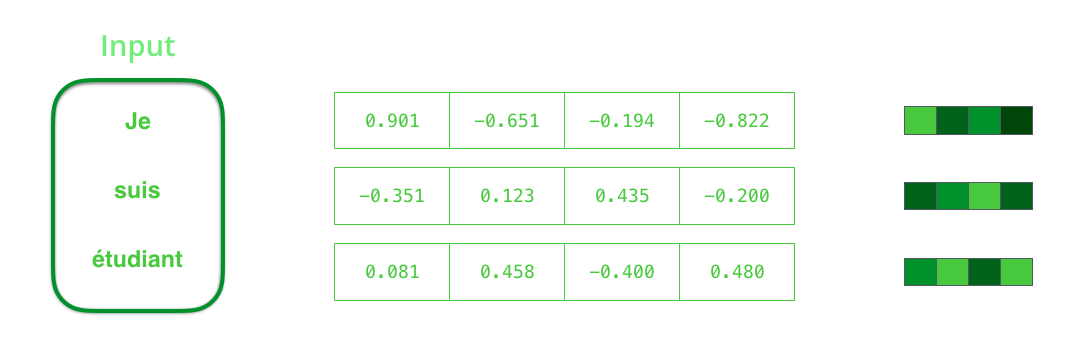
We need to turn the input words into vectors before processing them. That transformation is done using a word embedding algorithm. We can use pre-trained embeddings or train our own embedding on our dataset. Embedding vectors of size 200 or 300 are typical, we’re showing a vector of size four for simplicity.
我们需要在处理之前将输入字转换为矢量。 使用单词嵌入算法完成该转换。 我们可以使用预先训练的嵌入或在我们的数据集上训练我们自己的嵌入。 嵌入大小为200或300的向量是典型的,为简单起见,我们显示了大小为4的向量。
Now that we’ve introduced our main vectors/tensors, let’s recap the mechanics of an RNN and establish a visual language to describe these models:
现在我们已经介绍了我们的主要向量/张量,让我们回顾一下RNN的机制并建立一个可视语言来描述这些模型:
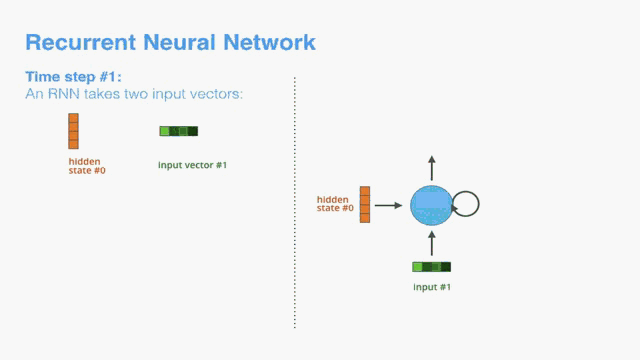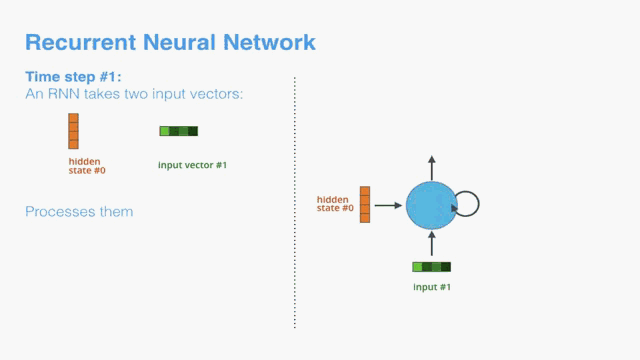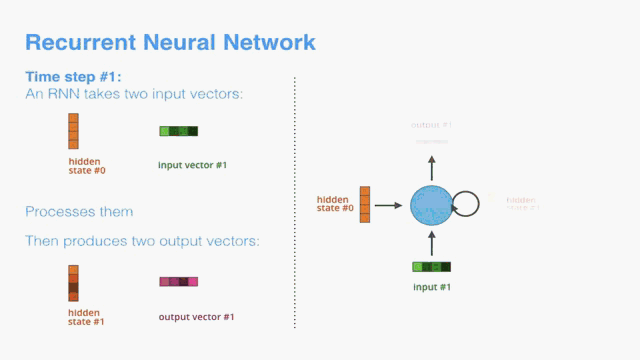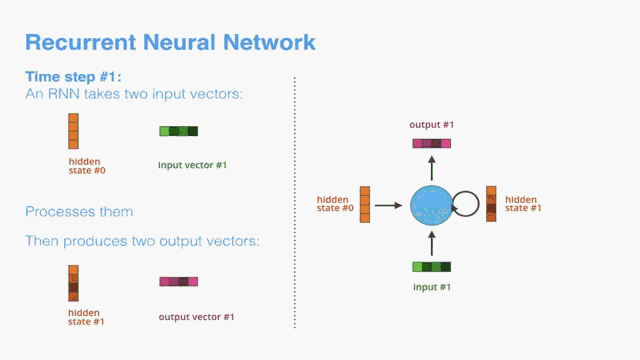
The next RNN step takes the second input vector and hidden state #1 to create the output of that time step. Later in the post, we’ll use an animation like this to describe the vectors inside a neural machine translation model.
下一个RNN步骤采用第二输入向量和隐藏状态#1来创建该时间步长的输出。 在帖子的后面,我们将使用这样的动画来描述神经机器翻译模型中的向量。
In the following visualization, each pulse for the encoder or decoder is that RNN processing its inputs and generating an output for that time step. Since the encoder and decoder are both RNNs, each time step one of the RNNs does some processing, it updates its hidden state based on its inputs and previous inputs it has seen.
在下面的可视化中,编码器或解码器的每个脉冲是RNN处理其输入并为该时间步产生输出。 由于编码器和解码器都是RNN,因此每当RNN的一个步骤进行一些处理时,它就根据其输入和之前看到的输入更新其隐藏状态。
Let’s look at the hidden states for the encoder. Notice how the last hidden state is actually the context we pass along to the decoder.
让我们看一下编码器的隐藏状态。 注意最后隐藏状态实际上是我们传递给解码器的上下文。