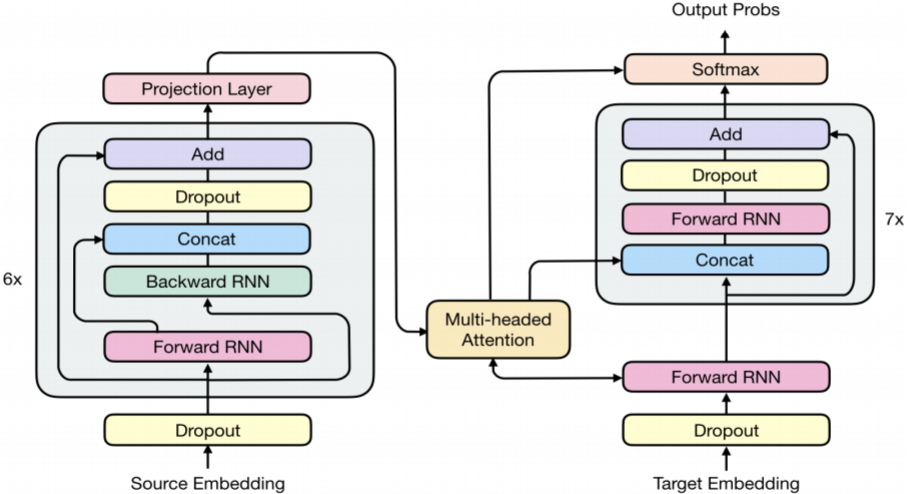
transformer是一种不同于RNN的架构,模型同样包含 encoder 和 decoder ,但是encoder 和 decoder 抛弃 了RNN,而使用各种前馈层堆叠在一起。
Encoder:
编码器是由N个完全一样的层堆叠起来的,每层又包括两个子层(sub-layer),第一个子层是multi-head self-attention mechanism层,第二个子层是一个简单的多层全连接层(fully connected feed-forward network)
Decoder:
解码器也是由N 个相同层的堆叠起来的。 但每层包括三个子层(sub-layer),第一个子层是multi-head self-attention层,第二个子层是multi-head context-attention 层,第三个子层是一个简单的多层全连接层(fully connected feed-forward network)
模型的架构如下

一 module
(1)multi-head self-attention
multi-head self-attention是key=value=query=隐层的注意力机制
Encoder的multi-head self-attention是key=value=query=编码层隐层的注意力机制
Decoder的multi-head self-attention是key=value=query=解码层隐层的注意力机制
这里介绍自注意力机制(self-attention)也就是key=value=query=H的情况下的输出
隐层所有时间序列的状态H,$h_{i}$代表第i个词对应的隐藏层状态
\[H = \left[ \begin{array}{l}
{h_1}\\
{h_2}\\
...\\
{h_n}
\end{array} \right] \in {R^{n \times \dim }}{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {h_i} \in {R^{1 \times \dim }}\]
H的转置为
\[{H^T} = [h_1^T,h_2^T,...,h_n^T] \in {R^{\dim \times n}}{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {h_i} \in {R^{1 \times \dim }}\]
如果只计算一个单词对应的隐层状态$h_{i}$的self-attention
\[\begin{array}{l}
weigh{t_{_{{h_i}}}}{\rm{ = softmax}}(({h_i}W_{query}^i)*(W_{key}^i*\left[ {\begin{array}{*{20}{c}}
{h_1^T}&{h_2^T}&{...}&{h_n^T}
\end{array}} \right])) = \left[ {\begin{array}{*{20}{c}}
{weigh{t_{i1}},}&{weigh{t_{i2}},}&{...}&{weigh{t_{in}}}
\end{array}} \right]\\
{\rm{value = }}\left[ {\begin{array}{*{20}{l}}
{{h_1}}\\
{{h_2}}\\
{...}\\
{{h_n}}
\end{array}} \right]*W_{value}^i = \left[ {\begin{array}{*{20}{l}}
{{h_1}W_{value}^i}\\
{{h_2}W_{value}^i}\\
{...}\\
{{h_n}W_{value}^i}
\end{array}} \right]\\
Attentio{n_{{h_i}}} = weigh{t_{_{{h_i}}}}*value = \sum\limits_{k = 1}^n {({h_k}W_{value}^i} )(weigh{t_{ik}})
\end{array}\]
同理,一次性计算所有单词隐层状态$h_{i}(1<=i<=n)$的self-attention
\[\begin{array}{l}
{\rm{weight}}{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\rm{ = softmax}}(\left[ {\begin{array}{*{20}{l}}
{{h_1}}\\
{{h_2}}\\
{...}\\
{{h_n}}
\end{array}} \right]W_{query}^i*(W_{key}^i*\left[ {\begin{array}{*{20}{c}}
{h_1^T}&{h_2^T}&{...}&{h_n^T}
\end{array}} \right])\\
{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\rm{ = softmax}}(\left[ {\begin{array}{*{20}{l}}
{{h_1}W_{query}^i}\\
{{h_2}W_{query}^i}\\
{...}\\
{{h_n}W_{query}^i}
\end{array}} \right]*\left[ {\begin{array}{*{20}{c}}
{W_{key}^ih_1^T}&{W_{key}^ih_2^T}&{...}&{W_{key}^ih_n^T}
\end{array}} \right]\\
{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\rm{ = softmax}}(\left[ {\begin{array}{*{20}{c}}
{({h_1}W_{query}^i)(W_{key}^ih_1^T)}&{({h_1}W_{query}^i)(W_{key}^ih_2^T)}&{...}&{({h_1}W_{query}^i)(W_{key}^ih_n^T)}\\
{({h_2}W_{query}^i)(W_{key}^ih_1^T)}&{({h_2}W_{query}^i)(W_{key}^ih_2^T)}&{...}&{({h_2}W_{query}^i)(W_{key}^ih_n^T)}\\
{...}&{...}&{...}&{...}\\
{({h_n}W_{query}^i)(W_{key}^ih_1^T)}&{({h_n}W_{query}^i)(W_{key}^ih_2^T)}&{...}&{({h_n}W_{query}^i)(W_{key}^ih_n^T)}
\end{array}} \right])\\
{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\rm{ = }}\left[ {\begin{array}{*{20}{c}}
{{\rm{softmax}}(({h_1}W_{query}^iW_{key}^ih_1^T)}&{({h_1}W_{query}^iW_{key}^ih_2^T)}&{...}&{({h_1}W_{query}^iW_{key}^ih_n^T))}\\
{{\rm{softmax}}(({h_2}W_{query}^iW_{key}^ih_1^T)}&{({h_2}W_{query}^iW_{key}^ih_2^T)}&{...}&{({h_2}W_{query}^iW_{key}^ih_n^T))}\\
{...}&{...}&{...}&{...}\\
{{\rm{softmax}}(({h_n}W_{query}^iW_{key}^ih_1^T)}&{({h_n}W_{query}^iW_{key}^ih_2^T)}&{...}&{({h_n}W_{query}^iW_{key}^ih_n^T))}
\end{array}} \right]
\end{array}\]
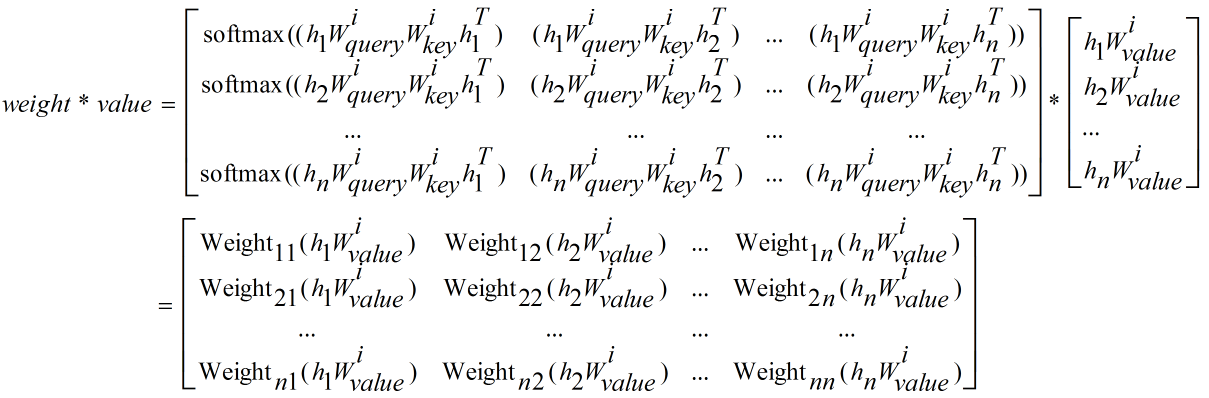
\[\begin{array}{l}
{\rm{sum}}(weight*value) = \left[ \begin{array}{l}
{\rm{Weigh}}{{\rm{t}}_{11}}({h_1}W_{value}^i) + {\rm{Weigh}}{{\rm{t}}_{12}}({h_2}W_{value}^i) + ...{\kern 1pt} {\kern 1pt} + {\rm{Weigh}}{{\rm{t}}_{1n}}({h_n}W_{value}^i)\\
{\rm{Weigh}}{{\rm{t}}_{21}}({h_1}W_{value}^i) + {\rm{Weigh}}{{\rm{t}}_{22}}({h_2}W_{value}^i) + ... + {\rm{Weigh}}{{\rm{t}}_{2n}}({h_n}W_{value}^i)\\
{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} ......\\
{\rm{Weigh}}{{\rm{t}}_{n1}}({h_1}W_{value}^i) + {\rm{Weigh}}{{\rm{t}}_{n2}}({h_2}W_{value}^i) + ... + {\rm{Weigh}}{{\rm{t}}_{nn}}({h_n}W_{value}^i)
\end{array} \right]\\
{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} = {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} \left[ \begin{array}{l}
\sum\limits_{k = 1}^n {{\rm{Weigh}}{{\rm{t}}_{1k}}({h_k}W_{value}^i)} \\
\sum\limits_{k = 1}^n {{\rm{Weigh}}{{\rm{t}}_{2k}}({h_k}W_{value}^i)} \\
{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} .......\\
\sum\limits_{k = 1}^n {{\rm{Weigh}}{{\rm{t}}_{nk}}({h_k}W_{value}^i)}
\end{array} \right]
\end{array}\]
所以最后的注意力向量为$head_{i}$
\[\begin{array}{l}
hea{d_i} = Attention(QW_{query}^i,KW_{query}^i,VW_{query}^i)\\
{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\rm{ = }}{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\rm{sum}}(weight*value)\\
{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} = {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} \left[ \begin{array}{l}
\sum\limits_{k = 1}^n {{\rm{Weigh}}{{\rm{t}}_{1k}}({h_k}W_{value}^i)} \\
\sum\limits_{k = 1}^n {{\rm{Weigh}}{{\rm{t}}_{2k}}({h_k}W_{value}^i)} \\
{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} .......\\
\sum\limits_{k = 1}^n {{\rm{Weigh}}{{\rm{t}}_{nk}}({h_k}W_{value}^i)}
\end{array} \right]
\end{array}\]
softmax函数需要加一个平滑系数$ \sqrt {{{\rm{d}}_k}} $
\[\begin{array}{l}
hea{d_i} = Attention(QW_{query}^i,KW_{key}^i,VW_{value}^i)\\
{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} = {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\rm{softmax}}(\frac{{(QW_{query}^i){{(KW_{key}^i)}^T}}}{{\sqrt {{d_k}} }})VW_{value}^i\\
{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} = {\rm{softmax}}(\left[ {\begin{array}{*{20}{c}}
{\frac{{({h_1}W_{query}^i)(W_{key}^ih_1^T)}}{{\sqrt {{d_k}} }}}&{\frac{{({h_1}W_{query}^i)(W_{key}^ih_2^T)}}{{\sqrt {{d_k}} }}}&{...}&{\frac{{({h_1}W_{query}^i)(W_{key}^ih_n^T)}}{{\sqrt {{d_k}} }}}\\
{\frac{{({h_2}W_{query}^i)(W_{key}^ih_1^T)}}{{\sqrt {{d_k}} }}}&{\frac{{({h_2}W_{query}^i)(W_{key}^ih_2^T)}}{{\sqrt {{d_k}} }}}&{...}&{\frac{{({h_2}W_{query}^i)(W_{key}^ih_n^T)}}{{\sqrt {{d_k}} }}}\\
{...}&{...}&{...}&{...}\\
{\frac{{({h_n}W_{query}^i)(W_{key}^ih_1^T)}}{{\sqrt {{d_k}} }}}&{\frac{{({h_n}W_{query}^i)(W_{key}^ih_2^T)}}{{\sqrt {{d_k}} }}}&{...}&{\frac{{({h_n}W_{query}^i)(W_{key}^ih_n^T)}}{{\sqrt {{d_k}} }}}
\end{array}} \right])VW_{value}^i\\
{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} = s{\rm{um}}({\rm{weigh}}{{\rm{t}}_{\sqrt {{d_k}} }}*value)
\end{array}\]
MultiHead注意力向量由多个$head_{i}$拼接后过一个线性层得到最终的MultiHead Attention
\[\begin{array}{l}
MulitiHead = Concat(hea{d_1},hea{d_2},...,hea{d_n}){W^o}{\kern 1pt} {\kern 1pt} {\kern 1pt} \\
where{\kern 1pt} {\kern 1pt} hea{d_i} = Attention(QW_{query}^i,KW_{key}^i,VW_{value}^i) = {\rm{softmax}}(\frac{{(QW_{query}^i){{(KW_{key}^i)}^T}}}{{\sqrt {{d_k}} }})VW_{value}^i
\end{array}\]
(2)LayerNorm+Position-wise Feed-Forward Networks
\[FFN(x) = \max (0,x{W_1} + {b_1}){W_2} + {b_2}\]
注意这里实现上和论文中有点区别,具体实现是先LayerNorm然后再FFN
class PositionwiseFeedForward(nn.Module): """ A two-layer Feed-Forward-Network with residual layer norm. Args: d_model (int): the size of input for the first-layer of the FFN. d_ff (int): the hidden layer size of the second-layer of the FNN. dropout (float): dropout probability(0-1.0). """ def __init__(self, d_model, d_ff, dropout=0.1): super(PositionwiseFeedForward, self).__init__() self.w_1 = nn.Linear(d_model, d_ff) self.w_2 = nn.Linear(d_ff, d_model) self.layer_norm = onmt.modules.LayerNorm(d_model) self.dropout_1 = nn.Dropout(dropout) self.relu = nn.ReLU() self.dropout_2 = nn.Dropout(dropout) def forward(self, x): """ Layer definition. Args: input: [ batch_size, input_len, model_dim ] Returns: output: [ batch_size, input_len, model_dim ] """ inter = self.dropout_1(self.relu(self.w_1(self.layer_norm(x)))) output = self.dropout_2(self.w_2(inter)) return output + x
(3)Layer Normalization
\[{\rm{x = }}\left[ {\begin{array}{*{20}{c}}
{{x_1}}&{{x_2}}&{...}&{{x_n}}
\end{array}} \right]\] $x_{1}, x_{2}, x_{3},... ,x_{n}$为样本$x$的不同特征
\[{{\hat x}_i} = \frac{{{x_i} - E(x)}}{{\sqrt {Var(x)} }}\]
\[{\rm{\hat x = }}\left[ {\begin{array}{*{20}{c}}
{{{\hat x}_1}}&{{{\hat x}_2}}&{...}&{{{\hat x}_n}}
\end{array}} \right]\]
最终$\hat x$为layer normalization的输出,并且$\hat x$均值为0,方差为1:
\[\begin{array}{l}
E({\rm{\hat x}}) = \frac{1}{n}\sum\limits_{i = 1}^n {{{\hat x}_i}} = \frac{1}{n}\sum\limits_{i = 1}^n {\frac{{{x_i} - E(x)}}{{\sqrt {Var(x)} }} = } \frac{1}{n}\frac{{[({x_1} + {x_2} + ... + {x_n}) - nE(x)]}}{{\sqrt {Var(x)} }} = 0\\
Var({\rm{\hat x}}) = \frac{1}{{n - 1}}\sum\limits_{i = 1}^n {{{({\rm{\hat x}} - E({\rm{\hat x}}))}^2}} = \frac{1}{{n - 1}}\sum\limits_{i = 1}^n {{{{\rm{\hat x}}}^2}} = \frac{1}{{n - 1}}\sum\limits_{i = 1}^n {\frac{{{{({x_i} - E(x))}^2}}}{{Var(x)}} = } \frac{{\frac{1}{{n - 1}}\sum\limits_{i = 1}^n {{{({x_i} - E(x))}^2}} }}{{Var(x)}} = \frac{{Var(x)}}{{Var(x)}} = 1
\end{array}\]
但是通常引入两个超参数w和bias, w和bias通过反向传递更新,但是初始值$w_{initial}=1, bias_{bias}=0$,$\varepsilon$防止分母为0:
\[{{\hat x}_i} = w*\frac{{{x_i} - E(x)}}{{\sqrt {Var(x) + \varepsilon } }} + bias\]
伪代码如下:
class LayerNorm(nn.Module): """ Layer Normalization class """ def __init__(self, features, eps=1e-6): super(LayerNorm, self).__init__() self.a_2 = nn.Parameter(torch.ones(features)) self.b_2 = nn.Parameter(torch.zeros(features)) self.eps = eps def forward(self, x): """ x=[-0.0101, 1.4038, -0.0116, 1.4277], [ 1.2195, 0.7676, 0.0129, 1.4265] """ mean = x.mean(-1, keepdim=True) """ mean=[[ 0.7025], [ 0.8566]] """ std = x.std(-1, keepdim=True) """ std=[[0.8237], [0.6262]] """ return self.a_2 * (x - mean) / (std + self.eps) + self.b_2 """ self.a_2=[1,1,1,1] self.b_2=[0,0,0,0] return [[-0.8651, 0.8515, -0.8668, 0.8804], [ 0.5795, -0.1422, -1.3475, 0.9101]] """
(4)Embedding
位置向量 Position Embedding
\[\begin{array}{l}
P{E_{pos,2i}} = \sin (\frac{{pos}}{{{\rm{1000}}{{\rm{0}}^{\frac{{{\rm{2i}}}}{{{{\rm{d}}_{\bmod el}}}}}}}})\\
P{E_{pos,2i + 1}} = \cos (\frac{{pos}}{{{\rm{1000}}{{\rm{0}}^{\frac{{{\rm{2i}}}}{{{{\rm{d}}_{\bmod el}}}}}}}})
\end{array}\]
计算Position Embedding举例:
输入句子$S=[w_1,w_2,...,w_{max\_len}]$, m为句子长度 ,假设max_len=3,且$d_{model}=4$:
pe = torch.zeros(max_len, dim)
position = torch.arange(0, max_len).unsqueeze(1) #position=[0,1,2] position.shape=(3,1) div_term = torch.exp((torch.arange(0, dim, 2, dtype=torch.float) *-(math.log(10000.0) / dim))) """ torch.arange(0, dim, 2, dtype=torch.float)=[0,2,4] shape=(3) -(math.log(10000.0) / dim)=-1.5350567286626973 (torch.arange(0, dim, 2, dtype=torch.float) *-(math.log(10000.0) / dim))=[0,2,4]*-1.5350567286626973=[-0.0000, -3.0701, -6.1402] div_term=exp([-0.0000, -3.0701, -6.1402])=[1.0000, 0.0464, 0.0022] """ pe[:, 0::2] = torch.sin(position.float() * div_term) """ pe=[[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000], [ 0.8415, 0.0000, 0.0464, 0.0000, 0.0022, 0.0000], [ 0.9093, 0.0000, 0.0927, 0.0000, 0.0043, 0.0000]] """ pe[:, 1::2] = torch.cos(position.float() * div_term) """ pe=[[ 0.0000, 1.0000, 0.0000, 1.0000, 0.0000, 1.0000], [ 0.8415, 0.5403, 0.0464, 0.9989, 0.0022, 1.0000], [ 0.9093, -0.4161, 0.0927, 0.9957, 0.0043, 1.0000]] """ pe = pe.unsqueeze(1) #pe.shape=[3,1,6]
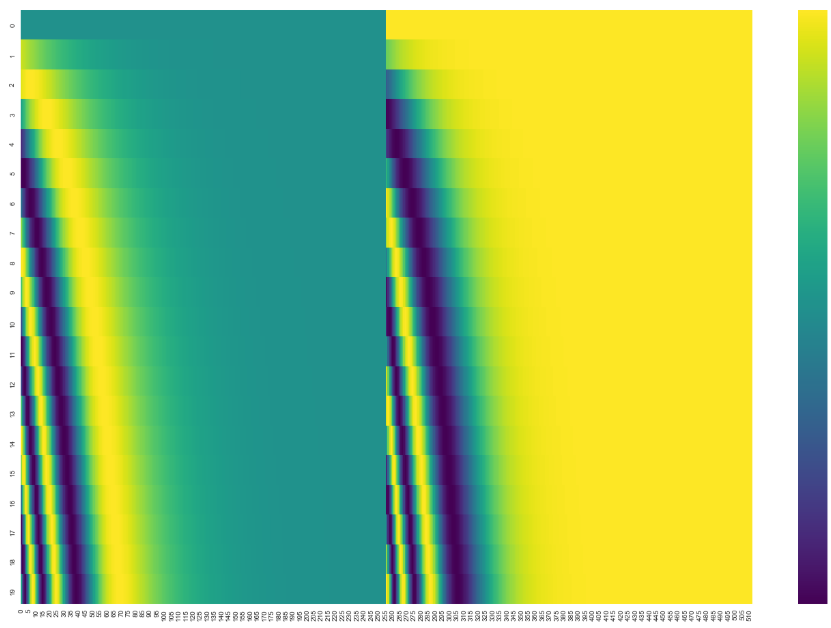
max_len=20,$d_{model}=4$Position Embedding,可以观察到同一个时间序列内t位置内大约只有前半部分起到区分位置的作用:
语义向量normal Embedding:
$x=[x_1,x_2,x_3,...,x_n]$,$x_i$为one-hot行向量
那么,代表语义的embedding是$emb=[emb_{1},emb_{2},emb_{3},...,emb_{n}$ $emb_{i}=x_iW$,transformer中的词向量表示为语义向量emb_{i}和位置向量pe_{i}之和
$emb^{final}_{i}=emb_{i}+pe_{i}$
二 Encoder
(1)Encoder是由多个相同的层堆叠在一起的:$[input\rightarrow embedding\rightarrow self-attention \rightarrow Add Norm \rightarrow FFN \rightarrow Add Norm]$:
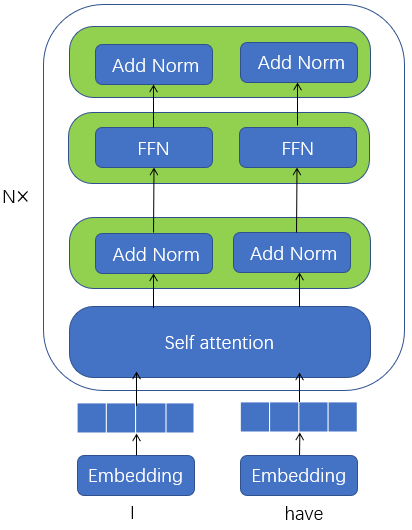
(2)Encoder的self-attention是既考虑前面的词也考虑后面的词的,而Decoder的self-attention只考虑前面的词,因此mask矩阵是全1。因此encoder的self-attention如下图:
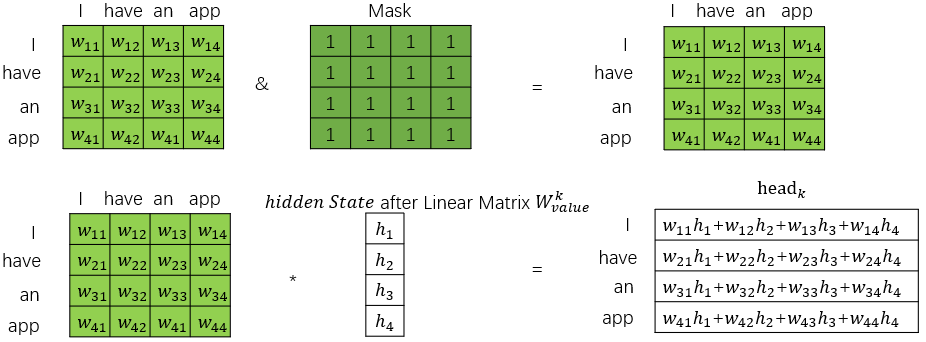
伪代码如下:
class TransformerEncoderLayer(nn.Module): """ A single layer of the transformer encoder. Args: d_model (int): the dimension of keys/values/queries in MultiHeadedAttention, also the input size of the first-layer of the PositionwiseFeedForward. heads (int): the number of head for MultiHeadedAttention. d_ff (int): the second-layer of the PositionwiseFeedForward. dropout (float): dropout probability(0-1.0). """ def __init__(self, d_model, heads, d_ff, dropout): super(TransformerEncoderLayer, self).__init__() self.self_attn = onmt.modules.MultiHeadedAttention( heads, d_model, dropout=dropout) self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout) self.layer_norm = onmt.modules.LayerNorm(d_model) self.dropout = nn.Dropout(dropout) def forward(self, inputs, mask): """ Transformer Encoder Layer definition. Args: inputs (`FloatTensor`): `[batch_size x src_len x model_dim]` mask (`LongTensor`): `[batch_size x src_len x src_len]` Returns: (`FloatTensor`): * outputs `[batch_size x src_len x model_dim]` """ input_norm = self.layer_norm(inputs) context, _ = self.self_attn(input_norm, input_norm, input_norm, mask=mask) out = self.dropout(context) + inputs return self.feed_forward(out)
二 Decoder
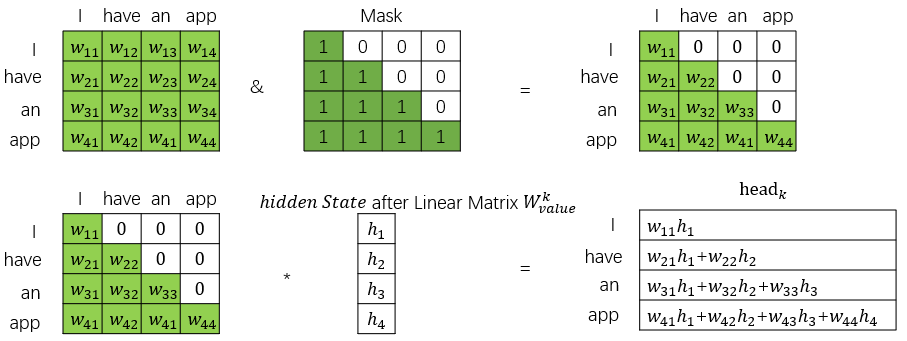
(1)decoder中的self attention层在计算self attention的时候,因为实际预测中只能知道前面的词,因此在训练过程中只需要计算当前位置和前面位置的self attention,通过掩码来计算Masked Multi-head Attention层。
例如"I have an app",中翻译出第一个词后"I",
"I"的self attention只计算与"I"与自己的self attention: Attention("I","I"),来预测下一个词
翻译出"I have"后,计算"have"与"have","have"与"I"的self attention: Attention("have","I"), Attention("have","have"),来预测下一个词
翻译出"I have an"后,计算"an"与"an","an"与"have","an"与"I"的self attention: Attention("an","an"), Attention("an","have"),Attention("an","I")来预测下一个词
可以用下图来表示:
self-attention的伪代码如下:
class MultiHeadedAttention(nn.Module): """ Args: head_count (int): number of parallel heads model_dim (int): the dimension of keys/values/queries, must be divisible by head_count dropout (float): dropout parameter """ def __init__(self, head_count, model_dim, dropout=0.1): assert model_dim % head_count == 0 self.dim_per_head = model_dim // head_count self.model_dim = model_dim super(MultiHeadedAttention, self).__init__() self.head_count = head_count self.linear_keys = nn.Linear(model_dim,model_dim) self.linear_values = nn.Linear(model_dim,model_dim) self.linear_query = nn.Linear(model_dim,model_dim) self.softmax = nn.Softmax(dim=-1) self.dropout = nn.Dropout(dropout) self.final_linear = nn.Linear(model_dim, model_dim) def forward(self, key, value, query, mask=None, layer_cache=None, type=None): """ Compute the context vector and the attention vectors. Args: key (`FloatTensor`): set of `key_len` key vectors `[batch, key_len, dim]` value (`FloatTensor`): set of `key_len` value vectors `[batch, key_len, dim]` query (`FloatTensor`): set of `query_len` query vectors `[batch, query_len, dim]` mask: binary mask indicating which keys have non-zero attention `[batch, query_len, key_len]` Returns: (`FloatTensor`, `FloatTensor`) : * output context vectors `[batch, query_len, dim]` * one of the attention vectors `[batch, query_len, key_len]` """ batch_size = key.size(0) dim_per_head = self.dim_per_head head_count = self.head_count key_len = key.size(1) query_len = query.size(1) def shape(x): """ projection """ return x.view(batch_size, -1, head_count, dim_per_head) \ .transpose(1, 2) def unshape(x): """ compute context """ return x.transpose(1, 2).contiguous() \ .view(batch_size, -1, head_count * dim_per_head) # 1) Project key, value, and query. if layer_cache is not None: key = self.linear_keys(key) #key.shape=[batch_size,key_len,dim] => key.shape=[batch_size,key_len,dim] value = self.linear_values(value) #value.shape=[batch_size,key_len,dim] => key.shape=[batch_size,key_len,dim] query = self.linear_query(query) #query.shape=[batch_size,key_len,dim] => key.shape=[batch_size,key_len,dim] key = shape(key) #key.shape=[batch_size,head_count,key_len,dim_per_head] value = shape(value) #value.shape=[batch_size,head_count,value_len,dim_per_head] query = shape(query) #query.shape=[batch_size,head_count,query_len,dim_per_head] key_len = key.size(2) query_len = query.size(2) # 2) Calculate and scale scores. query = query / math.sqrt(dim_per_head) scores = torch.matmul(query, key.transpose(2, 3)) #query.shape=[batch_size,head_count,query_len,dim_per_head] #key.transpose(2, 3).shape=[batch_size,head_count,dim_per_head,key_len] #scores.shape=[batch_size,head_count,query_len,key_len] if mask is not None: mask = mask.unsqueeze(1).expand_as(scores) scores = scores.masked_fill(mask, -1e18) # 3) Apply attention dropout and compute context vectors. attn = self.softmax(scores) #scores.shape=[batch_size,head_count,query_len,key_len] drop_attn = self.dropout(attn) context = unshape(torch.matmul(drop_attn, value)) #drop_attn.shape=[batch_size,head_count,query_len,key_len] #value.shape=[batch_size,head_count,value_len,dim_per_head] #torch.matmul(drop_attn, value).shape=[batch_size,head_count,query_len,dim_per_head] #context.shape=[batch_size,query_len,head_count*dim_per_head] output = self.final_linear(context) #context.shape=[batch_size,query_len,head_count*dim_per_head] return output
(2)Decoder的结构为$[input\rightarrow embedding\rightarrow self-attention \rightarrow Add Norm \rightarrow context-attention \rightarrow FFN \rightarrow Add Norm]$:
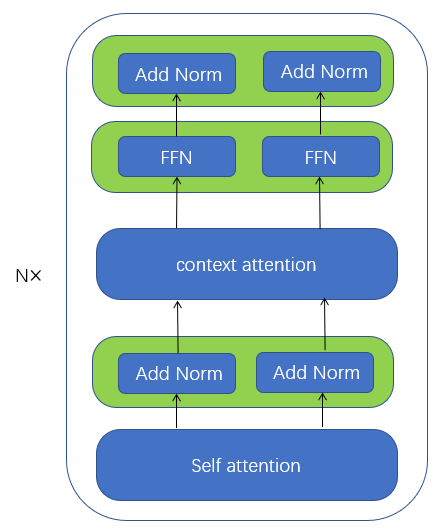
class TransformerDecoderLayer(nn.Module): """ Args: d_model (int): the dimension of keys/values/queries in MultiHeadedAttention, also the input size of the first-layer of the PositionwiseFeedForward. heads (int): the number of heads for MultiHeadedAttention. d_ff (int): the second-layer of the PositionwiseFeedForward. dropout (float): dropout probability(0-1.0). self_attn_type (string): type of self-attention scaled-dot, average """ def __init__(self, d_model, heads, d_ff, dropout, self_attn_type="scaled-dot"): super(TransformerDecoderLayer, self).__init__() self.self_attn_type = self_attn_type if self_attn_type == "scaled-dot": self.self_attn = onmt.modules.MultiHeadedAttention( heads, d_model, dropout=dropout) elif self_attn_type == "average": self.self_attn = onmt.modules.AverageAttention( d_model, dropout=dropout) self.context_attn = onmt.modules.MultiHeadedAttention( heads, d_model, dropout=dropout) self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout) self.layer_norm_1 = onmt.modules.LayerNorm(d_model) self.layer_norm_2 = onmt.modules.LayerNorm(d_model) self.dropout = dropout self.drop = nn.Dropout(dropout) mask = self._get_attn_subsequent_mask(MAX_SIZE) # Register self.mask as a buffer in TransformerDecoderLayer, so # it gets TransformerDecoderLayer's cuda behavior automatically. self.register_buffer('mask', mask) def forward(self, inputs, memory_bank, src_pad_mask, tgt_pad_mask, previous_input=None, layer_cache=None, step=None): """ Args: inputs (`FloatTensor`): `[batch_size x 1 x model_dim]` memory_bank (`FloatTensor`): `[batch_size x src_len x model_dim]` src_pad_mask (`LongTensor`): `[batch_size x 1 x src_len]` tgt_pad_mask (`LongTensor`): `[batch_size x 1 x 1]` Returns: (`FloatTensor`, `FloatTensor`, `FloatTensor`): * output `[batch_size x 1 x model_dim]` * attn `[batch_size x 1 x src_len]` * all_input `[batch_size x current_step x model_dim]` """ dec_mask = torch.gt(tgt_pad_mask + self.mask[:, :tgt_pad_mask.size(1), :tgt_pad_mask.size(1)], 0) input_norm = self.layer_norm_1(inputs) all_input = input_norm if previous_input is not None: all_input = torch.cat((previous_input, input_norm), dim=1) dec_mask = None if self.self_attn_type == "scaled-dot": query, attn = self.self_attn(all_input, all_input, input_norm, mask=dec_mask, layer_cache=layer_cache, type="self") elif self.self_attn_type == "average": query, attn = self.self_attn(input_norm, mask=dec_mask, layer_cache=layer_cache, step=step) query = self.drop(query) + inputs query_norm = self.layer_norm_2(query) mid, attn = self.context_attn(memory_bank, memory_bank, query_norm, mask=src_pad_mask, layer_cache=layer_cache, type="context") output = self.feed_forward(self.drop(mid) + query) return output, attn, all_input
五 label smoothing (标签平滑)
普通的交叉熵损失函数:
\[\begin{array}{l}
{\rm{loss}} = - \sum\limits_{k = 1}^K {tru{e_k}log (p(k|x))} \\
p(k|x) = softmax (\log it{s_k})\\
\log it{s_k} = \sum\limits_i {{w_{ik}}{z_i}}
\end{array}\]
梯度为:
\[\begin{array}{l}
\Delta {w_{ik}} = \frac{{\partial loss}}{{\partial {w_{ik}}}} = \frac{{\partial loss}}{{\partial logit{s_{ik}}}}\frac{{\partial logits}}{{\partial {w_{ik}}}} = ({y_k} - labe{l_k}){z_k}\\
label = [\begin{array}{*{20}{c}}
{\begin{array}{*{20}{c}}
{\frac{\alpha }{4}}&{\frac{\alpha }{4}}
\end{array}}&{1 - \alpha }&{\frac{\alpha }{4}}&{\frac{\alpha }{4}}
\end{array}]
\end{array}\]
有一个问题
只有正确的那一个类别有贡献,其他标注数据中不正确的类别概率是0,无贡献,朝一个方向优化,容易导致过拟合
因此提出label smoothing 让标注数据中正确的类别概率小于1,其他不正确类别的概率大于0:
也就是之前$label=[0,0,0,1,0]$,通过标签平滑,给定一个固定参数$\alpha$, 概率为1地方减去这个小概率,标签为0的地方平分这个小概率$\alpha$变成:
\[labe{l^{new}} = [\begin{array}{*{20}{c}}
{\begin{array}{*{20}{c}}
{\frac{\alpha }{4}}&{\frac{\alpha }{4}}
\end{array}}&{1 - \alpha }&{\frac{\alpha }{4}}&{\frac{\alpha }{4}}
\end{array}]\]
损失函数为
\[loss = - \sum\limits_{k = 1}^K {label_k^{new}\log p(k|x)} \]
引入相对熵函数:
\[{D_{KL}}(Y||X) = \sum\limits_i {Y(i)\log (\frac{{Y(i)}}{{X(i)}})} = \sum\limits_i {Y(i)\log Y(i)} - Y(i)\log X(i)\]
令$Y=label^{new}, X=p(k|x)$
label smoothing 可以防止模型把预测值过度集中在概率较大类别上,把一些概率分到其他概率较小类别上
附: Transformer与RNN的结合RNMT+(The Best of Both Worlds: Combining Recent Advances in Neural Machine Translation)
(1)RNN:难以训练并且表达能力较弱 trainability versus expressivity
(2)Transformer:有很强的特征提取能力(a strong feature extractor),但是没有memory机制,因此需要额外引入位置向量。