作者述:之前有学习过一遍,但是一段时间过后,很多细节地方已经模糊。最近重新推导了一遍,为了尽可能保留推导思路,特地写作此博文。一方面供自己日后回忆,另一方面方便跟大家交流学习。
关于本博文,说明如下:
1. 本博文不保证推导过程完全正确,如有问题,欢迎指正。
2. 如果需要,欢迎大家转载,唯一的要求是请注明出处。
本文会从最基本的神经网络结构开始,一步步推导,最终得到一个神经网络利用BP算法进行训练的完整过程,以及中间会用到的公式的推导。
神经网络
神经网络结构如下图所示,总体上由三部分组成:输入层、隐藏层(为方便起见,图中给出一层,实际中可以有多层)和输出层。对于每一层,都是由若干个单元(神经元)组成。相邻两层的神经元之间是全连接的,但是同一层内,各神经元之间无连接。现在对各参数进行说明:X=[(x(1))T,(x(2))T,…,(x(m))T]T表示输入一个样本后的实际输出。
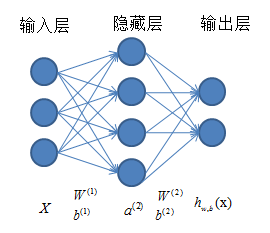
整个神经网络的工作过程是:从输入层开始输入数据,依靠线性组合,得到与输入层相邻层的各个神经元的值,然后用当前层作为输入,作用于下一层,依次进行,直到到达输出层,得到最终的输出。但是,如果仅仅进行线性变换,最终得到的输出结果仅仅是输入的线性表达。这显然不能满足我们的需求(我们需要得到输入的一个非线性表达),因此,通常在每个神经元进行线性组合之后,再经过一个激励函数,激励函的结果作为对应神经元的值。激励函数的选择有很多种,我使用的是f(z)=sigmoid(z)=11+e(−z)函数
前向传播与代价函数
从输入层开始,依次计算其余各层各神经元值的过程就是前向传播(十分形象)。对于每个待求的神经元,其过程是先利用前一层各个神经元的值和层间的权值与偏置进行线性组合,然后通过一个指定的激励函数f(z)为例:
第二层的各神经元:
z(2)1=∑3j=1(W(1)1jxj)+b(1)1
a(2)1=f(z(2)1)
z(2)2=∑3j=1(W(1)2jxj)+b(1)2
a(2)2=f(z(2)2)
z(2)3=∑3j=1(W(1)3jxj)+b(1)3
a(2)3=f(z(2)3)
z(2)4=∑3j=1(W(1)4jxj)+b(1)4
a(2)4=f(z(2)4)
第三层(输出层)的各神经元
z(3)1=∑4j=1(W(2)1ja(2)j)+b(2)1
a(3)1=f(z(3)1)
z(3)2=∑4j=1(W(2)2ja(2)j)+b(2)2
a(3)2=f(z(3)2)
当然,你也可以进行向量化:
z(2)=W(1)x+b(1)
a(2)=f(z(2))
z(3)=W(2)a(2)+b(2)
hW,b(x)=f(z(3))
请注意,上面向量化的过程中,z的维度与对应层中神经元的个数对应。

以上是以一个简单的例子介绍神经网络的前向传播过程,接下来进行一般化处理,并且得到代价函数。假设用l。
仍然以单样本(x,y)为例,定义如下的代价函数:
需要注意的是上面其实表示的是网络的输出与实际数据的欧式距离。它们其实是一个向量,向量的维度与神经网络输出层的神经元个数一致。如果考虑所有的样本数据,则总的代价函数如下:
说明:
1. 神经网络的目的是从大量的数据中寻求特征,以对新的数据进行预测。也就是说,我们在训练神经网络的时候,应该尽量调整网络参数,使得网络在输入数据下的输出值与实际样本值尽可能接近,而为满足这样条件的最直观的手段是使两者的距离最小。也就是上面代价函数的表示形式。
2. 上面代价函数的最右边一项我们称为正则化,它是为了防止网络过拟合。
梯度下降与BP算法
使用梯度下降算法求解上面的问题。根据梯度下降的原理,网络参数的更新如下:
其中:
为简单起见,现在仍然考虑单样本的情况。首先考虑求解∂J(W,b;x,y)∂W(l)ij。
考虑到:z(nl)k=∑Snl−1p=1[W(nl−1)kpa(nl−1)p+bnl−1k],上面的求偏导可以使用链式法则进行。
在这里,设定δ(nl)i=[f(z(nl)i)−yi]⋅f′(z(nl)i)参数与最后一层的残差以及倒数第二层各个神经元的值有关。
进行推广,我们其实可以得到:
∂J(W,b;x,y)∂W(l)ij=δ(l+1)i⋅a(l)j
上面的推导过程把复杂的求偏导的过程转化成两项的乘积,其中a(l)j参数的求解过程,如果能推出倒数第二层的残差与最后一层残差的关系,其他层之间的递推关系也就明确了。
之前推导到这里的时候犯了一个错误,直接写成∂12∑Snlk=1(f(znlk)−yk)2∂z(nl)i⋅∂znli∂z(nl−1)i个神经元的偏导关系。
从中我们可以总结出:
至此,按照正常的思路求解BP算法解过程便基本完成了。其中严格的推导过程并不仅仅是上面所写。上面的过程只是碰到这样的求解问题时,一种普通的思路历程。
由于本篇只是着眼于推导公式部分,所以训练的完整过程就不再叙述,后期会在做实验的篇章中进行详细描述。敬请关注。
参考文献
[1] Andrew Ng. ‘UFLDL’. http://ufldl.stanford.edu/wiki/index.php/UFLDL_Tutorial
<link rel="stylesheet" href="http://csdnimg.cn/release/phoenix/production/markdown_views-0bc64ada25.css">
</div>
作者述:之前有学习过一遍,但是一段时间过后,很多细节地方已经模糊。最近重新推导了一遍,为了尽可能保留推导思路,特地写作此博文。一方面供自己日后回忆,另一方面方便跟大家交流学习。
关于本博文,说明如下:
1. 本博文不保证推导过程完全正确,如有问题,欢迎指正。
2. 如果需要,欢迎大家转载,唯一的要求是请注明出处。
本文会从最基本的神经网络结构开始,一步步推导,最终得到一个神经网络利用BP算法进行训练的完整过程,以及中间会用到的公式的推导。
神经网络
神经网络结构如下图所示,总体上由三部分组成:输入层、隐藏层(为方便起见,图中给出一层,实际中可以有多层)和输出层。对于每一层,都是由若干个单元(神经元)组成。相邻两层的神经元之间是全连接的,但是同一层内,各神经元之间无连接。现在对各参数进行说明:X=[(x(1))T,(x(2))T,…,(x(m))T]T表示输入一个样本后的实际输出。
整个神经网络的工作过程是:从输入层开始输入数据,依靠线性组合,得到与输入层相邻层的各个神经元的值,然后用当前层作为输入,作用于下一层,依次进行,直到到达输出层,得到最终的输出。但是,如果仅仅进行线性变换,最终得到的输出结果仅仅是输入的线性表达。这显然不能满足我们的需求(我们需要得到输入的一个非线性表达),因此,通常在每个神经元进行线性组合之后,再经过一个激励函数,激励函的结果作为对应神经元的值。激励函数的选择有很多种,我使用的是f(z)=sigmoid(z)=11+e(−z)函数
前向传播与代价函数
从输入层开始,依次计算其余各层各神经元值的过程就是前向传播(十分形象)。对于每个待求的神经元,其过程是先利用前一层各个神经元的值和层间的权值与偏置进行线性组合,然后通过一个指定的激励函数f(z)为例:
第二层的各神经元:
z(2)1=∑3j=1(W(1)1jxj)+b(1)1
a(2)1=f(z(2)1)
z(2)2=∑3j=1(W(1)2jxj)+b(1)2
a(2)2=f(z(2)2)
z(2)3=∑3j=1(W(1)3jxj)+b(1)3
a(2)3=f(z(2)3)
z(2)4=∑3j=1(W(1)4jxj)+b(1)4
a(2)4=f(z(2)4)
第三层(输出层)的各神经元
z(3)1=∑4j=1(W(2)1ja(2)j)+b(2)1
a(3)1=f(z(3)1)
z(3)2=∑4j=1(W(2)2ja(2)j)+b(2)2
a(3)2=f(z(3)2)
当然,你也可以进行向量化:
z(2)=W(1)x+b(1)
a(2)=f(z(2))
z(3)=W(2)a(2)+b(2)
hW,b(x)=f(z(3))
请注意,上面向量化的过程中,z的维度与对应层中神经元的个数对应。
以上是以一个简单的例子介绍神经网络的前向传播过程,接下来进行一般化处理,并且得到代价函数。假设用l。
仍然以单样本(x,y)为例,定义如下的代价函数:
需要注意的是上面其实表示的是网络的输出与实际数据的欧式距离。它们其实是一个向量,向量的维度与神经网络输出层的神经元个数一致。如果考虑所有的样本数据,则总的代价函数如下:
说明:
1. 神经网络的目的是从大量的数据中寻求特征,以对新的数据进行预测。也就是说,我们在训练神经网络的时候,应该尽量调整网络参数,使得网络在输入数据下的输出值与实际样本值尽可能接近,而为满足这样条件的最直观的手段是使两者的距离最小。也就是上面代价函数的表示形式。
2. 上面代价函数的最右边一项我们称为正则化,它是为了防止网络过拟合。
梯度下降与BP算法
使用梯度下降算法求解上面的问题。根据梯度下降的原理,网络参数的更新如下:
其中:
为简单起见,现在仍然考虑单样本的情况。首先考虑求解∂J(W,b;x,y)∂W(l)ij。
考虑到:z(nl)k=∑Snl−1p=1[W(nl−1)kpa(nl−1)p+bnl−1k],上面的求偏导可以使用链式法则进行。
在这里,设定δ(nl)i=[f(z(nl)i)−yi]⋅f′(z(nl)i)参数与最后一层的残差以及倒数第二层各个神经元的值有关。
进行推广,我们其实可以得到:
∂J(W,b;x,y)∂W(l)ij=δ(l+1)i⋅a(l)j
上面的推导过程把复杂的求偏导的过程转化成两项的乘积,其中a(l)j参数的求解过程,如果能推出倒数第二层的残差与最后一层残差的关系,其他层之间的递推关系也就明确了。
之前推导到这里的时候犯了一个错误,直接写成∂12∑Snlk=1(f(znlk)−yk)2∂z(nl)i⋅∂znli∂z(nl−1)i个神经元的偏导关系。
从中我们可以总结出:
至此,按照正常的思路求解BP算法解过程便基本完成了。其中严格的推导过程并不仅仅是上面所写。上面的过程只是碰到这样的求解问题时,一种普通的思路历程。
由于本篇只是着眼于推导公式部分,所以训练的完整过程就不再叙述,后期会在做实验的篇章中进行详细描述。敬请关注。
参考文献
[1] Andrew Ng. ‘UFLDL’. http://ufldl.stanford.edu/wiki/index.php/UFLDL_Tutorial
<link rel="stylesheet" href="http://csdnimg.cn/release/phoenix/production/markdown_views-0bc64ada25.css">
</div>