BP算法博客 https://www.cnblogs.com/liuxin0430/p/7998775.html
讲梯度下降法的一篇文章:https://www.jianshu.com/p/c7e642877b0e
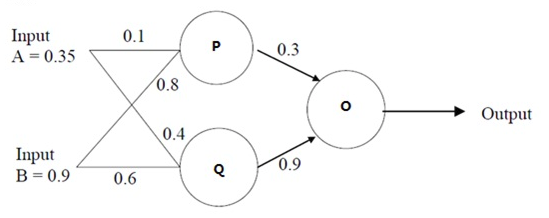
BP算法,看这两篇博文基本上就可以完全掌握,讲解的也比较详细。第一个将BP算法的简单的示例,我们呢可以计算具体的值,先把作者的代码挪过来吧,其实实现也是比较简单,但是十分实用。
# -*- coding: utf-8 -*-
import numpy as np
def sigmoid(x):#激活函数
return 1/(1+np.exp(-x))
input = np.array([[0.35], [0.9]]) #输入数据
w1 = np.array([[0.1, 0.8], [0.4, 0.6]])#第一层权重参数
w2 = np.array([0.3, 0.9])#第二层权重参数
real = np.array([[0.5]])#真实值
for s in range(0,100,1):
pq = sigmoid(np.dot(w1,input))#第一层输出
output = sigmoid(np.dot(w2,pq))#第二层输出,也即是最终输出
e = output-real #误差
if np.square(e)/2<0.01:
break
else:
#否则,按照梯度下降计算权重参数
#其中,应用链式法则计算权重参数的更新量
w2 = w2 - e*output*(1-output)*pq.T
w1 = w1 - e*output*(1-output)*w2*pq.T*(1-pq.T)*input
print w1,'\n',w2 #输出最终结果
print output第二篇讲的是具体的梯度下降的原理,梯度的方向函数增长最快,反方向下降最快,更新的时候,减去布长乘以梯度。

经过多次的下降,达到了低谷,作者给出了一个未知量和两个未知量的实例。
作者也给出了相应的代码,我亲自测试过,没有问题。具体我们一步步的将公式转化成矩阵的形式,每次迭代就行,公式也放在下面了。第一个为Loss函数,第二个公式为梯度方向,只需要代入具体的值就可以计算。

import numpy as np
# Size of the points dataset.
m = 20
# Points x-coordinate and dummy value (x0, x1).
X0 = np.ones((m, 1))
X1 = np.arange(1, m+1).reshape(m, 1)
X = np.hstack((X0, X1))
# Points y-coordinate
y = np.array([
3, 4, 5, 5, 2, 4, 7, 8, 11, 8, 12,
11, 13, 13, 16, 17, 18, 17, 19, 21
]).reshape(m, 1)
# The Learning Rate alpha.
alpha = 0.01
def error_function(theta, X, y):
'''Error function J definition.'''
diff = np.dot(X, theta) - y
return (1./2*m) * np.dot(np.transpose(diff), diff)
def gradient_function(theta, X, y):
'''Gradient of the function J definition.'''
diff = np.dot(X, theta) - y
return (1./m) * np.dot(np.transpose(X), diff)
def gradient_descent(X, y, alpha):
'''Perform gradient descent.'''
theta = np.array([1, 1]).reshape(2, 1)
gradient = gradient_function(theta, X, y)
while not np.all(np.absolute(gradient) <= 1e-5):
theta = theta - alpha * gradient
gradient = gradient_function(theta, X, y)
return theta
optimal = gradient_descent(X, y, alpha)
print('optimal:', optimal)
print('error function:', error_function(optimal, X, y)[0,0])