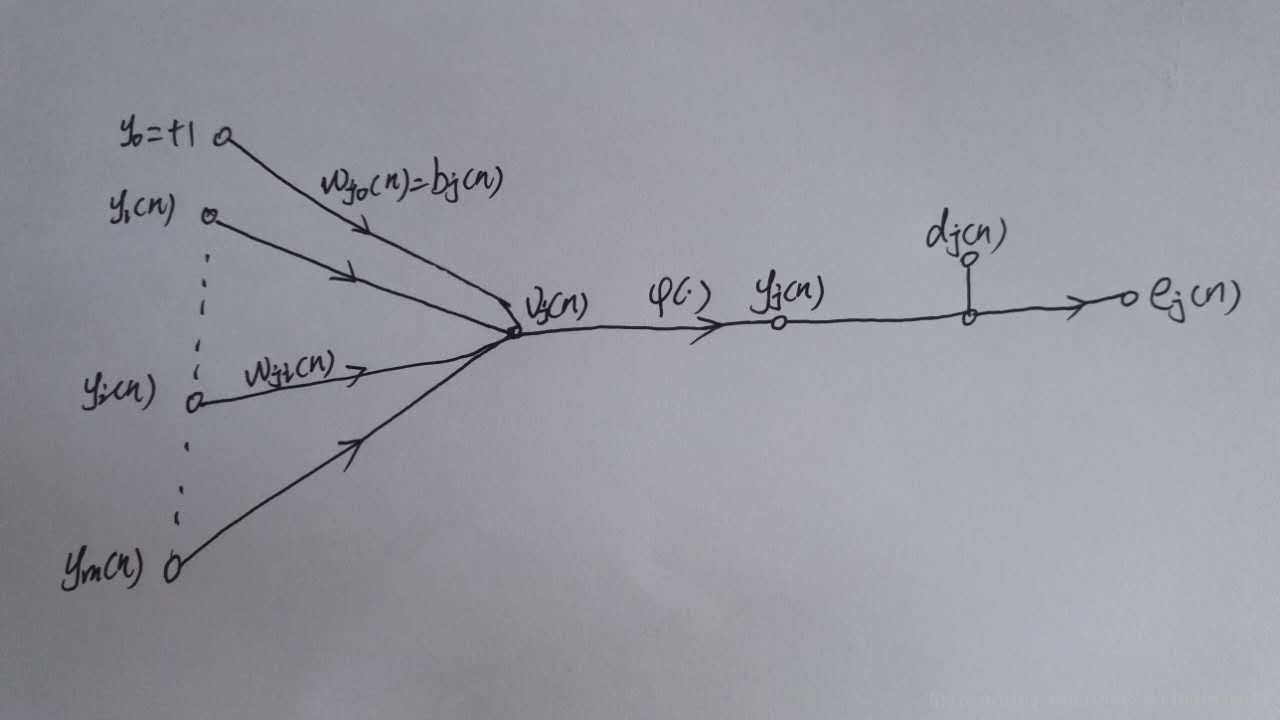
输出层梯度求解过程
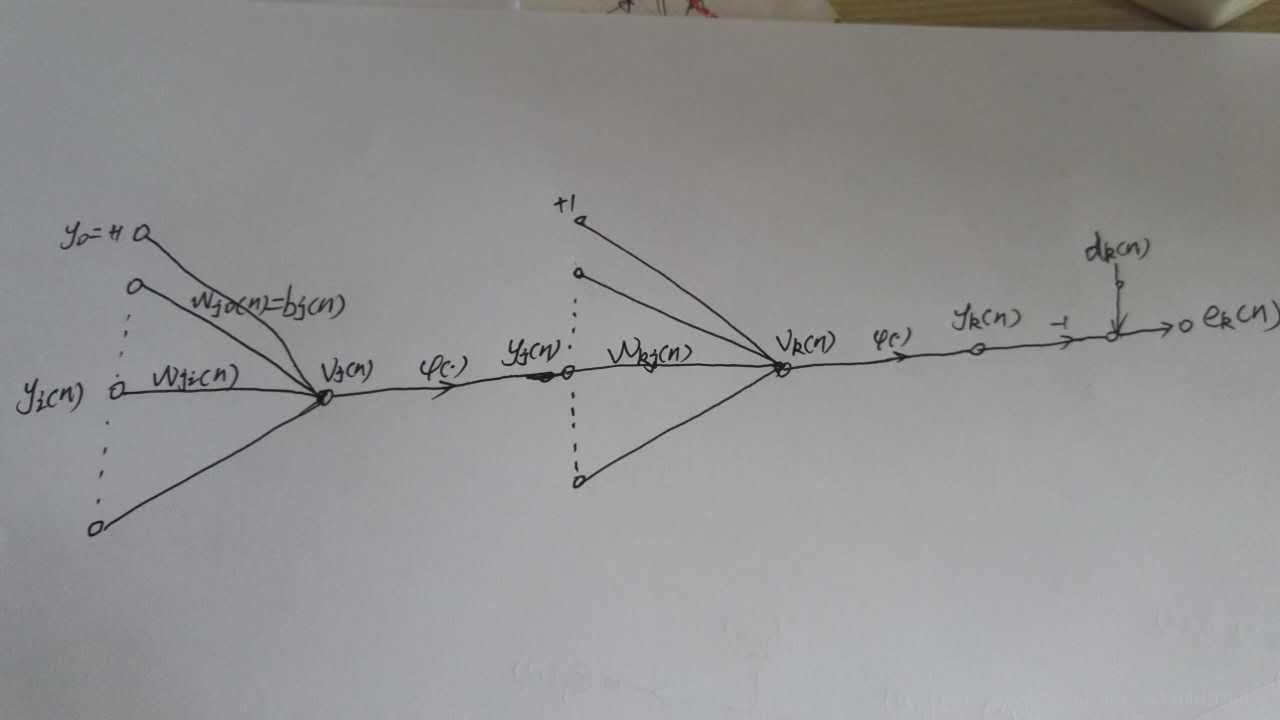
如上图所示,为一个输出层神经元,在计算输出层梯度的时候,我们不用去考虑前一层是如何输入的。所以我们用y来表示,图中的y(n)表示第n个样本在前一层的输出值,这一层的输入值。我们将当前节点定义为j。那么当前节点j的输入值之和为 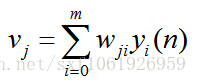
这里的m是节点j前一层的输入节点的个数,其中包括一个偏置项b。这里的公式都很像,看公式注意下标。然后节点j的输出要经过激活函数,如图所示我们定义激活函数为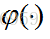
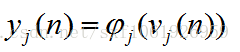
图中还有一个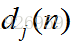
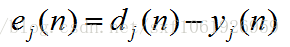
然后为计算梯度,我们需要有一个损失函数,因为反传其实就是在求损失函数对权值的梯度。
我们这里使用平方误差作为损失函数,所以损失函数为 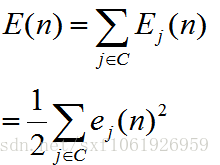
这里的C为全部的输出层神经节点
好了,把前提说清楚了,就可以开始求梯度了 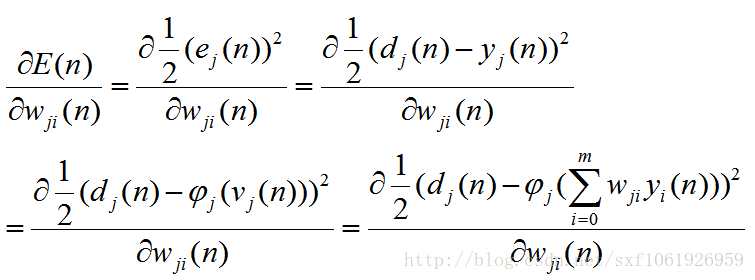
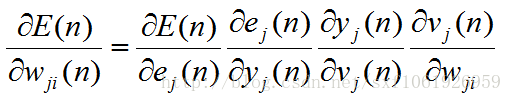
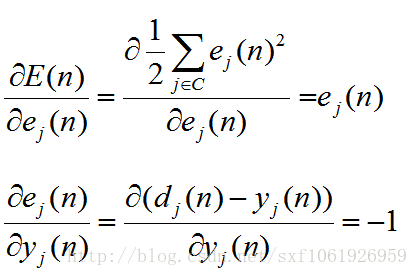
继续
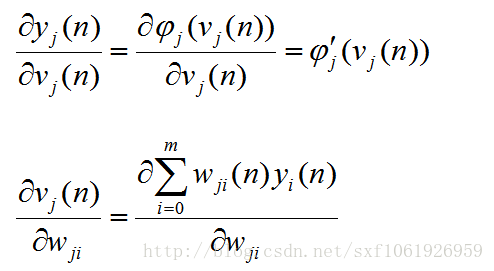
这里注意下,分子上的求和符号展开后,除了含有
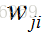 的哪项外,其他所求的导数都为0,,因为对当前权值来说,他们都是常数,常数的导数为0.所以我们能得到 (这里隐含层和输出层是有点不一样的...)
的哪项外,其他所求的导数都为0,,因为对当前权值来说,他们都是常数,常数的导数为0.所以我们能得到 (这里隐含层和输出层是有点不一样的...)
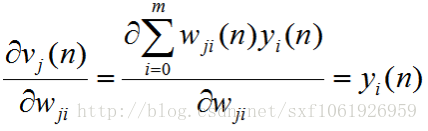
现在把这些都放回原来的公式去
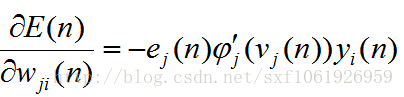
可以看出来,当前求的梯度和前一层的输入直接相关。一旦有了梯度,我们要做的就是用这个梯度去更新权值,当然不能直接减,太大了,所以加入一个步长
 ,得到
,得到
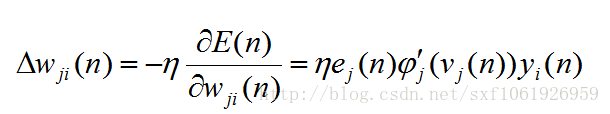
最后更新权值
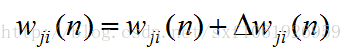
这里要注意,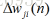
隐藏层梯度计算
前面计算了输出层的梯度更新,这里我们要计算隐藏层。
之所以输出层和隐藏层要分开计算,那是因为隐藏层更加复杂,可以想象一下,隐藏层的节点,会连接下一层的所有节点,那么在梯度反传的时候也要从这些连接的节点去获取梯度。所以隐藏层就不能只求一个节点的梯度了,但是原理还是一样的,也是求损失函数对当前权值的梯度,只是计算过程变得比前面一个复杂了一点点。
这里我重新画了两个节点,左边这个表示隐藏层节点j,右边那个表示输出层节点k,我们刚才计算的就是右边那个,现在我们来计算前面这个。
别看我这里只画了一个输出层节点k,但是真实情况不一定只有一个,如果有多个,那么当前的节点j一定会和其有链接,那么和其连接的节点就会有梯度反传。
所以需要重新计算梯度,和输出层不同的是,输出层只需要去考虑一个输出神经元的损失,而隐藏层需要去考虑全部全部输出层节点的损失,如下 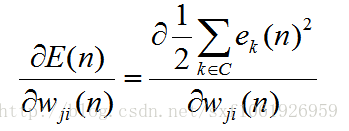
在求输出层的时候,因为权值只和其中的一个e有关,所以上面的累加展开后,只有一项为非零,其他全是0。但是在这里,隐藏层和上面的每个节点都要连接,所以我们这里要对全部的e求导。
得到 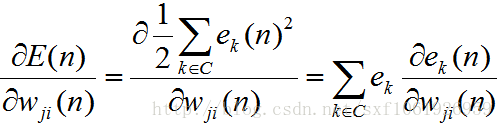
然后后面的就是差不多的了,一直求梯度求下去、 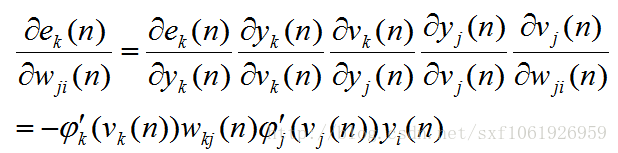
这里我直接写出来了,步骤和前面的差不多,自己试着推导下就知道了
我们直接得到最终的梯度更新 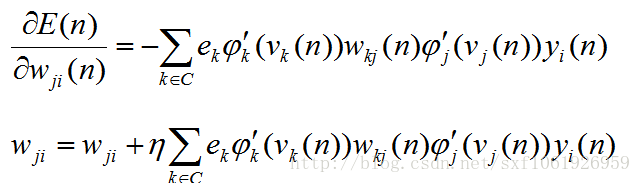
到这里,梯度更新的推导算是结束了,根据以上公式可以推导出任何一个权值的梯度
然后我们可以看看这些梯度之间有那些共同点,我把前面推导好的输出层和隐藏层梯度拿下来,如下 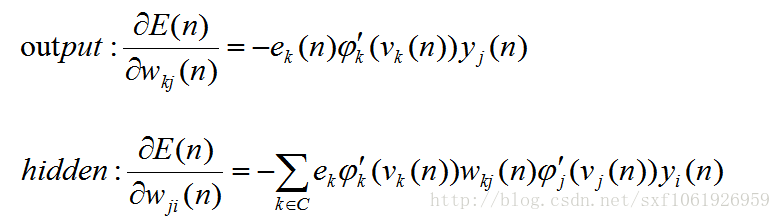
可以发现,每个公式中,最后一项都是所求权值的输入值,导数第二项都是激活函数的导数值,剩下的为传下来的损失。所以在算法实现的时候,往往把前面的损失值和激活函数导数的乘积当作一项整体,这样就可以实现链式计算,方便代码实现。我们把他叫做局部梯度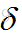
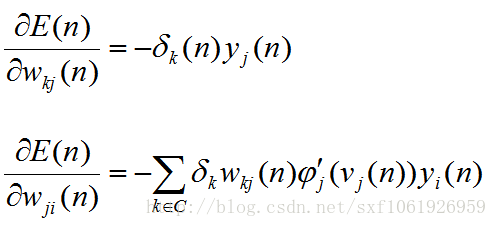
然后隐藏层的前半部分式子可以继续合并 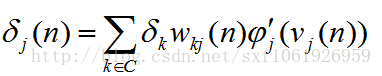
最终得到 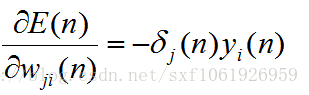
所以不管是求哪个权值的梯度,我们都可以化简为如下形式 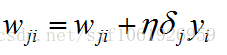
这样算法实现起来就方便多了
python实现
主程序 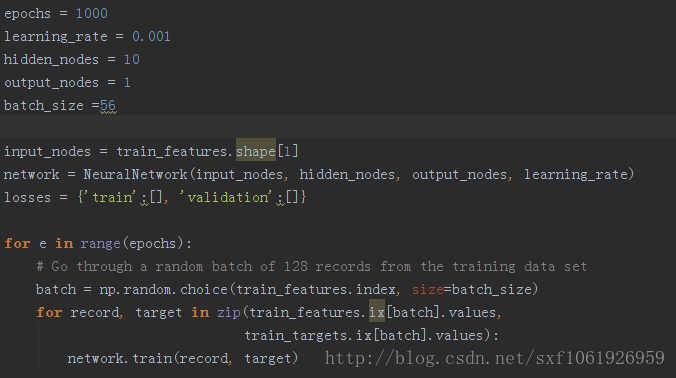
定义好输入节点、输出节点、隐藏节点大小、以及学习率等
前向传播 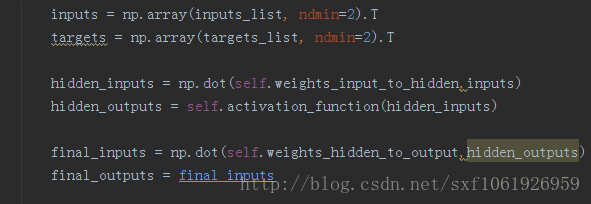
反向更新

代码github:bp.py