目录
一、什么是神经网络NN
神经网络(neural networks)是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所做出的交互反应。
神经网络中最基本的成分是神经元,即上述定义中的“简单单元”,在生物神经网络中,每个神经元与其他神经元相连,当它“兴奋”时,就会向相连的神经元发送化学物质,从而改变这些神经元内的电位;如果某神经元的电位超过了一个“阈值”,那么他就会被激活,即“兴奋”起来,想其他神经元发送化学物质。
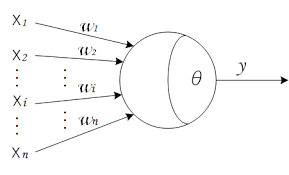
上述情形,在1943年,就被抽象成了“M-P神经元模型”(上图)。在这个模型中,神经元接受来自n个其他神经元,通过带权重的连接传递过来的信号;神经元将接受到的总输入值与神经元的阈值进行比较,然后通过“激活函数”处理并输出神经元的处理结果,较常用的激活函数为:
他的图像为:
将M-P模型进行扩展,由一个神经元,扩展到多层多个神经元,就是神经网络了。下图为深度神经网络(DNN)示意图
那这样扩展之后,要如何给每个神经元输入数据,每个神经元又是如何计算出输出值,又如何使得结果更加准确呢,这就涉及到了数学原理相关的推导
二、数学原理
正向传播
假设我们有一个神经网络如下:

从上图可以很容易看出,第h个隐层的输入,和第j个输出层的输入,是下记两个求和公式:
如果我们都有sigmoid作为激活函数:
此处先额外证明一下此公式的一个特性:
那我们的隐层和输出层的输出与输入的关系,使用激活表达式的表达结果如下:
使用上述的几个式子,就可以获得从输入层的输入,到输出层输出的所有正向过程了
但是其中有几个值,是无法真实获得,需要随机初始化的变量:
输入层和隐层的连接权
隐层的阈值
隐层和输出层的连接权
输出层的阈值
为了使得NN达到更好的效果,我们希望上面的4个值最终调整到比较合理的值
那么如何调整这些值呢,就需要用到误差逆传播BP的推导了
误差逆传播BP
BP的主体思想为:从误差曲线上任意一点开始,如果想要找到这条曲线的最小值,使得误差最小,最快的方向为当前位置导数的逆方向
比如的曲线如下:

蓝色的点为我们开始的点(即随机了连接权以及阈值之后,首次计算获得的误差)红色的线为当前的切线
如果我们想从蓝色的点,沿着函数曲线快速的找到函数的最小值,那一定就是沿着切线,向反方向查找(按照上图,正方向为右上,反方向为左下),是速度是最快的。BP的思路,大体就是这个思路(另外的一个思路参考 牛顿迭代,也是求导,但是方式略微有不同的地方),所以我们每次对每个变量的更新公式如下:
下面我们来推导如何求得这个导数,以及每次对每个变量调整的值应该为多少
从上述式子中,我们可以知道整体的均方差(也就是误差)为:
输出层相关推导
先已输出层为例,和输出层相关变量的调整值为:
ps. 正常情况下,前面还要乘一个学习率
来调整每次的步长;此步长一般为经验值常量,因为懒,所以此处及后面都省略不写了。但是在最终结论中,会在表达式中添加上这个值
先已连接权为例,从当前已列出的式子中,貌似看不出和
的关系,但是没有关系,我们把上述式子一步一步带入,可以获得下面的式子:
本次推导主要用到的公式如下:
将下面3个式子,一步步带入到第一个式子中,可以获得:
从上面这个式子可以看出,
是和
产生关联,
产生关联,而在
的,这样子就能直观看到
分开对每个式子求导过程如下:
根据上面推导的sigmoid求导性质可得:
将这3个式子带入到原式子可得:
等式右边的值均为已知值,可直接使用求得
求
:
为了表述简单,提取两者的公共部分,令
,上述两者可以简化表达式为:
隐层相关推导
接下来求隐层相关的:
使用到的公式有(部分为上面推导出的结果):
求
:
从上面
从
是相关的
和阈值
相关:
相关
继续根据链式法则:
对每一项分开求导:
因为一个隐层的输出,会给到多个输出层,所以在对
继续分开求导得:
带入最初的式子得:
令
可得:
求
:
三、结论
其中:
四、后记
在学习了新知识之后,有事没事的时候,最好都再过一遍笔记,不然本来挺自信的,结果3-4个月没看,被别人问起的时候,突然才发现其实都记不大清了,也是丢人
