1.向量化计算:
向量化计算是一种特殊的并行计算的方式,相比于一般程序在同一时间只能执行一个操作方式,它可以在同一时间执行多次操作,通常是对不同的数据执行同样的一个或一批指令,或者说把指令应用于一个数组/向量。
2.数据导入:
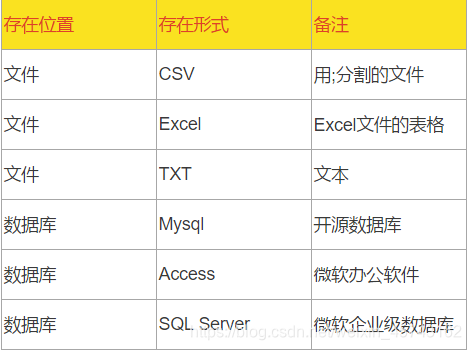
2.1.导入CSV文件:用read_csv导入csv文件。
from pandas import read_csv
df=read_csv(r'C:\Users\13056\Desktop\data.csv',encoding='utf-8')
print(df)
成功导入文件:
日期 购买用户数 广告费用 渠道数
0 2014-01-01 2496 9.14 6
1 2014-01-02 2513 9.47 8
2 2014-01-03 2228 6.31 4
3 2014-01-04 2336 6.41 2
4 2014-01-05 2508 9.05 5
.. ... ... ... ...
153 2014-06-26 2492 8.72 2
154 2014-06-27 2712 10.80 5
155 2014-06-28 2369 7.35 5
156 2014-06-29 2380 7.19 4
157 2014-06-30 2377 7.06 2
2.2导入文本文件:用read_table导入普通文本文件
read_table(路径,列名,分隔符,编码)
from pandas import read_table
df=read_table(r'C:\Users\13056\Desktop\1234.txt',names=['name','age'],sep=' ',encoding='utf-8')
print(df)
得出数据
name age
0 张三 21
1 李四 22
2 王五 23
2.3导入Excel文件:使用read_excel函数导入Excel文件。
read_excel(路径,sheet的名字,列名)
from pandas import read_excel
df=read_excel(r'C:\Users\13056\Desktop\123.xlsx',sheetname='data')
print(df)
3.导出数据
导出文本文件:to_csv函数
to_csv(路径,分隔符,导出行列号,列名)
```python
from pandas import DataFrame
data=DataFrame(data={
'id':[1,2,3],
'name':['join','mike','hero']
}
)
data.to_csv(r'C:\Users\13056\Documents\Tencent Files\1305638814\FileRecv\d1.csv')
4.对重复数据进行处理
```python
from pandas import DataFrame
data=DataFrame(data={
'id':[1,2,3,2],
'name':['join','mike','hero','mike']}
)
data=data.drop_duplicates()
print(data)
5.缺失值处理
去除数据结构中值为空的数据
data=data.dropna()
6.空格值处理
from pandas import DataFrame
data=DataFrame(data={
'id':[1,2,3],
'name':['join','mike',' hero']
}
)
name=data['name'].str.strip()
data['name']=name
print(data)
7.字段抽取:已知数据的开始和结束位置,抽取出新的列
from pandas import DataFrame
data=DataFrame(data={
'id':[1,2,3],
'tel':['123445','12345','1245552']
}
)
data['tel']=data['tel'].astype(str)
badns=data['tel'].str.slice(0,3)
print(badns)
#0 123
#1 123
#2 124
8.字段拆分:拆分已有字符串
split(用于切割的字符串,分为多少列,是否展开为数据框)
from pandas import DataFrame
data=DataFrame(data={
'id':[1,2,3],
'tel':['12 3445','12 345','12 45552']
}
)
data['tel']=data['tel'].astype(str)
badns=data['tel'].str.split(' ',1,True)
print(badns)
# 0 1
#0 12 3445
#1 12 345
#2 12 45552
9.记录抽取
(1)比较运算:df[df.comments>10000]
(2)范围运算:df[df.comments.between(1000,10000)]
(3)空值匹配:df[pandas.isnull(df.title)]
(4)字符匹配:df[df.title.str.contatins('开学‘,na=False)]
(5)逻辑运算:df[(df.comments>=1000)&(df.comments<=10000)]
10.随机抽样:
import numpy
r=numpy.random.randint(0,10,3);
#从0到10取3个
from pandas import read_csv
df=read_csv(r'C:\Users\13056\Desktop\data.csv',encoding='utf-8')
df=df.loc[r,:];
print(df)
# 日期 购买用户数 广告费用 渠道数
#8 2014-01-09 2358 7.39 5
#4 2014-01-05 2508 9.05 5
#9 2014-01-10 2419 8.17 6
11.记录合并
from pandas import DataFrame,concat
a1=DataFrame(data={
'name':['小米8','红米','k30'],
'price':[1222,'一千',{1,2,3}]},
index=['first','second',3]
)
a2=DataFrame(data={
'name':['oppe','红米','k30'],
'price':[1,'一千',{1,2,3}]},
index=['first','second',3]
)
df=concat([a1,a2])
print(df)
# name price
#first 小米8 1222
#second 红米 一千
#3 k30 {1, 2, 3}
#first oppe 1
#second 红米 一千
#3 k30 {1, 2, 3}
12.字段合并:要求数据结构一致,直接用+就可以了。
13.字段匹配,不同结构的数据库按照一定的条件合并。
from pandas import DataFrame,merge
a1=DataFrame(data={
'name':['小米8','红米','k30'],
'price':[1222,'一千',{1,2,3}],
'id':[1,2,3]},
index=['first','second',3]
)
a2=DataFrame(data={
'lalal':['oppe','红米','k30'],
'price':[1222,'一千',{1,2,3}],
'id':[1,2,3]},
index=['first','second',3]
)
df=merge(
a1,
a2,
left_on='id',#左边合并的目标
right_on='id'#右边合并的目标
)
print(df)
# name price_x id lalal price_y
#0 小米8 1222 1 oppe 1222
#1 红米 一千 2 红米 一千
#2 k30 {1, 2, 3} 3 k30 {1, 2, 3}
14.数据标准化
0-1标准化:
x*=(x-min)/(max-min)
15.数据分组
cut(需要分组的数据,分组划分的分组,右边是否闭合,自定义标签)
import pandas;
from pandas import read_csv
df=read_csv(r'C:\Users\13056\Desktop\data.csv',sep="|")
bins=[min(df.cost)-1,20,40,60,80,100,max(df.cost)+1]
labels=['20以下','20到40','40到60','60到80','80到100','100以上']
result=pandas.cut(df.cost,bins=bins,right=False,labels=labels)
print(result)
cast是根据的对应物,当然也可以用groupby.
16.日期转换:
data=to_datatime(dataString,format)
属性 注释
%Y 代表年份
%m 代表月份
%d 代表日期
%H 代表小时
%M 代表分种
%S 代表秒
17.日期格式化:将日期型数据,按照给定的格式转为字符型的数据
apply(lambda x:datetime.strftime(x,format))
18.日期抽取:从日期格式里面抽取出需要的属性。
属性 注释
second 秒
minute 分钟
day 一个月中的天
hour 小时
month 月
year 年
weekday 一周中的第几天
