1.基本统计分析:一般统计最小值,第一四分位值,中值,第三四分位置。最大值
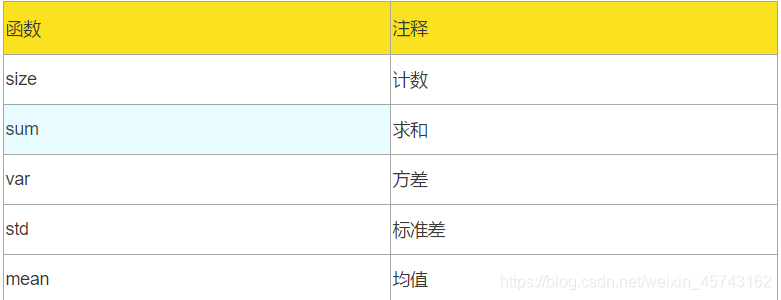
常用统计指标:计数,求和,平均值,方差,标准差
描述性统计分析函数:describe()
常用的统计函数
import pandas
data=pandas.read_csv('D:\BaiduNetdiskDownload\8\8.1\data.csv')
print(data)
print(data.score.describe())
#count 13.000000
#mean 121.076923
#std 12.446295
#min 96.000000
#25% 115.000000
#50% 120.000000
#75% 131.000000
#max 140.000000
#如果要分统计也行
print(data.score.size)
#13
2.分组统计
分组统计函数:groupby(by=[分组1,分组2.。。】)
【统计列1,统计列2】
.agg({统计列别名1:统计函数1.。。。})
解释
by:用于分组的列
中括号:用于统计的列
agg:统计别名显示统计值的名称
import pandas,numpy
data=pandas.read_csv('D:\BaiduNetdiskDownload\8\8.1\data.csv')
data['score2']=data['score']*data['score']
data.groupby(by=['class'])['score'].agg({
'总分':numpy.sum,
'人数':numpy.size,
'平均值':numpy.mean,
'方差':numpy.var,
'标准差':numpy.std,
}
)
# 总分 人数 平均值 方差 标准差
#class
#一班 635 5 127.00 71.000000 8.426150
#三班 484 4 121.00 104.666667 10.230673
#二班 455 4 113.75 290.250000 17.036725
a=data.groupby(by=['class','name'])['score','score2'].agg({
numpy.sum,
numpy.size
}
)
这样拿班级和姓名分组得到这个:
score score2
sum size sum size
class name
一班 朱 122 1 14884 1
朱志 120 1 14400 1
许 122 1 14884 1
郑丽 140 1 19600 1
郭杰 131 1 17161 1
三班 庄艺 119 1 14161 1
方伟 136 1 18496 1
方小 114 1 12996 1
陈 115 1 13225 1
二班 林良 135 1 18225 1
林 96 1 9216 1
郑 119 1 14161 1
黄志 105 1 11025 1
res=data.groupby(by=['class'])['score'].agg({
'总分':numpy.sum,
'人数':numpy.size,
'平均值':numpy.mean,
'方差':numpy.var,
'标准差':numpy.std,
}
)
print(res.index)
#Index(['一班', '三班', '二班'], dtype='object', name='class')
print(res.columns)
#Index(['总分', '人数', '平均值', '方差', '标准差'], dtype='object')
print(res['平均值'])
class
一班 127.00
三班 121.00
二班 113.75
各种引用还是看具体需求
3.分布分析:根据分析目的,将数据等距或者不等距的分组,进行研究各分组顾虑的一种分析方法。
import pandas,numpy
data=pandas.read_csv('D:\BaiduNetdiskDownload\8\8.3\data.csv')
bins=[min(data.年龄)-1,20,30,40,max(data.年龄)+1]
labels=['20岁以下','20到30岁','30到40岁','40岁以上']
age=pandas.cut(data.年龄,bins,labels=labels)
data['年龄分层']=age
print(data.groupby(by=['年龄分层'])['年龄'].agg({'人数':numpy.size}))
人数
年龄分层
20岁以下 2061
20到30岁 46858
30到40岁 8729
40岁以上 1453
4.交叉分析:通常用于分析两个或两个以上分组变量之间的关系,以交叉表形式进行变量间关系的对比分析;
pivot_table(values,index,colums,aggfunc,fill_value)
value:数据透视表中的值
index:数据透视表中的行
columns:数据透视表中的列
aggfunc:统计函数
fill_value:NA值的统一替换
返回的是数据透视import pandas,numpy
data=pandas.read_csv('D:\BaiduNetdiskDownload\8\8.4\data.csv')
bins=[min(data.年龄)-1,20,30,40,max(data.年龄)+1]
labels=['20岁以下','20到30岁','30到40岁','40岁以上']
age=pandas.cut(data.年龄,bins,labels=labels)
data['年龄分层']=age
r1=data.pivot_table(
values=['年龄'],
index=['年龄分层'],
columns=['性别'],
aggfunc=[numpy.size,numpy.mean]
)
下面得到数据透视表
size mean
年龄 年龄
性别 女 男 女 男
年龄分层
20岁以下 111 1950 18.972973 19.321026
20到30岁 2903 43955 25.954874 25.746149
30到40岁 735 7994 33.213605 33.084939
40岁以上 567 886 51.691358 49.943567
表的结果如果有两个数据透视表a,b可以用a.join(b)合并,必须ivalues,ndex和columns一样
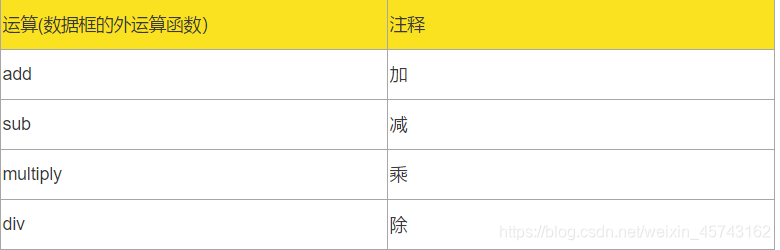
5.结构分析:在分组的基础上,计算各组成部分所占的比重,进而分析总体的内部特征的一种分析方法。
axis参数说明:0是按列计算,1是按行计算。
运算(数据框的外运算函数) 注释
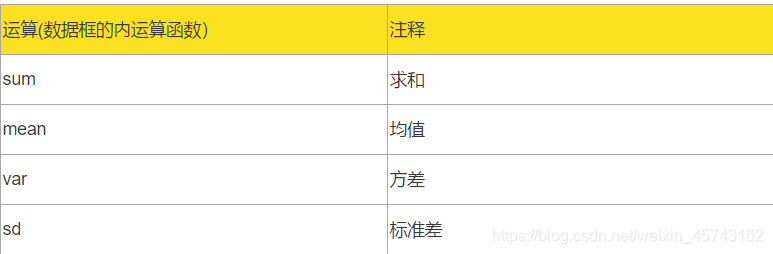
运算(数据框的内运算函数) 注释
import pandas,numpy
data=pandas.read_csv('D:\BaiduNetdiskDownload\8\8.5\data.csv')
data2=data.pivot_table(
values=['月流量(M)'],
index=['省份'],
columns=['通信品牌'],
aggfunc=[numpy.sum]
)
print(data2,data2.sum())
sum
月流量(M)
通信品牌 全球通 动感地带 神州行
省份
上海 19468.8 356637.9 584389.2
......
青海 29473.6 395802.3 508992.0
通信品牌
sum 月流量(M) 全球通 1216533.6
动感地带 11825462.3
神州行 18385315.7
dtype: float64
print(data2.sum(axis=1),data2.sum(axis=0))
按行运算和按列运算。默认为0.
省份
上海 960495.9
云南 946952.9
.......
宁夏 923295.9
黑龙江 910761.4
dtype: float64 通信品牌
sum 月流量(M) 全球通 1216533.6
动感地带 11825462.3
神州行 18385315.7
dtype: float64
print(data2.div(data2.sum(axis=1),axis=0))
sum
月流量(M)
通信品牌 全球通 动感地带 神州行
省份
上海 0.020270 0.371306 0.608424
云南 0.044443 0.407948 0.547609
内蒙古 0.033975 0.367371 0.598654
北京 0.035174 0.388562 0.576265
按行求和为1
import pandas,numpy
data=pandas.read_csv('D:\BaiduNetdiskDownload\8\8.5\data.csv')
data2=data.pivot_table(
values=['月流量(M)'],
index=['省份'],
columns=['通信品牌'],
aggfunc=[numpy.sum]
)
print(data2.div(data2.sum(axis=0),axis=1))
sum
月流量(M)
通信品牌 全球通 动感地带 神州行
省份
上海 0.016004 0.030158 0.031786
云南 0.034595 0.032667 0.028205
内蒙古 0.025725 0.028616 0.029993
北京 0.027877 0.031680 0.030220
.。。。。
台湾 0.030006 0.030187 0.029591
吉林 0.020698 0.030346 0.030499
按列求和为1
6.相关分析:是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向及相关程度,是研究随机变量之间的相关关系的一种统计方法。
相关系数:可以描述定量变量之间的关系:
0<=|r|<0.3 低度相关
0.3<=|r|<0.8 中度相关
0.8<=|r|<1 高度相关
相关分析函数:
DataFrame.corr()
Series.corr(other)
如果数据框调用corr方法,那么将会计算每个列两两之间的相似度
如果是序列调用,那么只是计算该序列与传入序列之间的相关度
import pandas,numpy
data=pandas.read_csv('D:\BaiduNetdiskDownload\8\8.6\data.csv')
print(data)
print(data['人口'].corr(data['文盲率']))
#0.10762237339473261拟合程度不高啊
print(data.loc[:,['网上购物率','文盲率','人口']].corr())
网上购物率 文盲率 人口
网上购物率 1.000000 -0.702975 -0.343643
文盲率 -0.702975 1.000000 0.107622
人口 -0.343643 0.107622 1.000000
