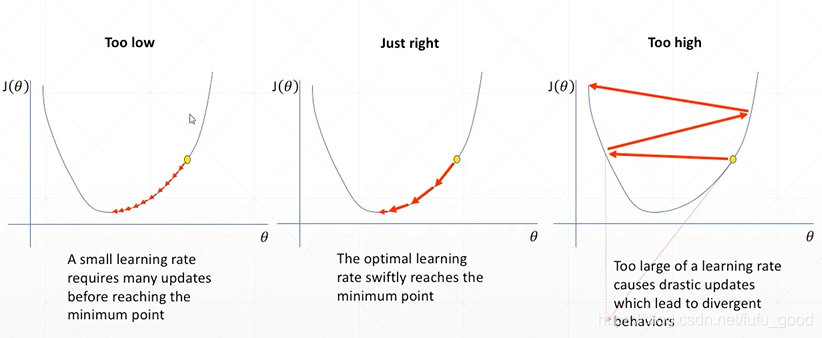
在实验过程中我们可能都对learning rate的选取而苦脑过
- learning rate过小:loss降低过慢
- learning rate过大:loss可能达不到最优,而可能在最优值范围震动
其比较如下图所示
解决办法
1. 使用ReducLROnPlateau
1.1 介绍
该类是torch.optim.lr_scheduler.ReduceLROnPlateau()
使用方法如下:
class torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=0,
verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
参数说明:
- optimer指的是网络的优化器
- mode (str) ,可选择‘min’或者‘max’,min表示当监控量停止下降的时候,学习率将减小,max表示当监控量停止上升的时候,学习率将减小。默认值为‘min’
- factor 学习率每次降低多少,new_lr = old_lr * factor
- patience=10,容忍网路的性能不提升的次数,高于这个次数就降低学习率
- verbose(bool) - 如果为True,则为每次更新向stdout输出一条消息。 默认值:False
- threshold(float) - 测量新最佳值的阈值,仅关注重大变化。 默认值:1e-4
- cooldown: 减少lr后恢复正常操作之前要等待的时期数。 默认值:0。
- min_lr,学习率的下限
- eps ,适用于lr的最小衰减。 如果新旧lr之间的差异小于eps,则忽略更新。 默认值:1e-8。
1.2 使用注意事项
scheduler.step(train_loss) #这里不再用optimizer.step()
import torch
..... # 此处省略部分代码
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
scheduler = ReduceLROnPlateau(optimizer, 'min',factor=0.1, patience=10, verbose=True)
..... # 此处省略部分代码
scheduler.step(train_loss) #这里不再用optimizer.step()
# scheduler.step(val_loss)
2. 使用StepLR
2.1 介绍
该类是torch.optim.lr_scheduler.StepLR()
使用方法如下:
torch.optim.lr_scheduler.StepLR(optimizer,step_size=30,gamma=0.1)
参数说明:
- optimer指的是网络的优化器
- step_size指的是step_size次更新一次learning rate,即new_lr = old_lr * gamma
- gamma指的是学习率每次降低多少,默认为0.1
2.2 使用注意事项
scheduler.step(train_loss) #这里不再用optimizer.step()
import torch
..... # 此处省略部分代码
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=30,gamma=0.1)
..... # 此处省略部分代码
scheduler.step(train_loss) #这里不再用optimizer.step()
# scheduler.step(val_loss)
