
学习率设置
在训练过程中,一般根据训练轮数设置动态变化的学习率。
- 刚开始训练时:学习率以 0.01 ~ 0.001 为宜。
- 一定轮数过后:逐渐减缓。
- 接近训练结束:学习速率的衰减应该在100倍以上。
Note:
如果是 迁移学习 ,由于模型已在原始数据上收敛,此时应设置较小学习率 (≤10−4≤10−4) 在新数据上进行 微调 。

把脉 目标函数损失值 曲线
理想情况下 曲线 应该是 滑梯式下降 [绿线]:
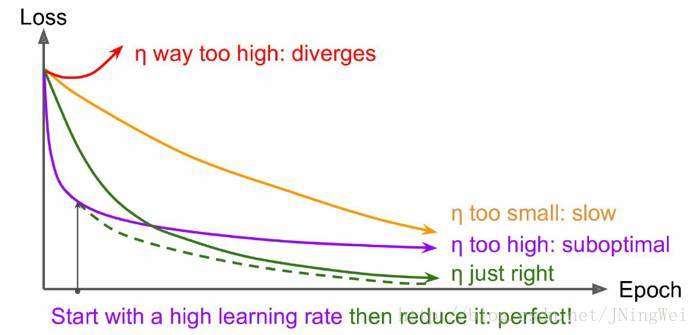
- 曲线 初始时 上扬 [红线]:
Solution:初始 学习率过大 导致 振荡,应减小学习率,并 从头 开始训练 。
- 曲线 初始时 强势下降 没多久 归于水平 [紫线]:
Solution:后期 学习率过大 导致 无法拟合,应减小学习率,并 重新训练 后几轮 。
- 曲线 全程缓慢 [黄线]:
Solution:初始 学习率过小 导致 收敛慢,应增大学习率,并 从头 开始训练 。
[1] 解析卷积神经网络—深度学习实践手册
[2] 调整学习速率以优化神经网络训练
[3] 如何找到最优学习率
深度学习中参数更新的方法想必大家都十分清楚了——sgd,adam等等,孰优孰劣相关的讨论也十分广泛。可是,learning rate的衰减策略大家有特别关注过吗?
说实话,以前我也只使用过指数型和阶梯型的下降法,并不认为它对深度学习调参有多大帮助。但是,最近的学习和工作中逐渐接触到了各种奇形怪状的lr策略,可以说大大刷新了三观,在此也和大家分享一下学习经验。
learning rate衰减策略文件在tensorflow/tensorflow/python/training/learning_rate_decay.py中,函数中调用方法类似tf.train.exponential_decay就可以了。
以下,我将在ipython中逐个介绍各种lr衰减策略。
exponential_decay
exponential_decay(learning_rate, global_step, decay_steps, decay_rate,
staircase=False, name=None)
指数型lr衰减法是最常用的衰减方法,在大量模型中都广泛使用。
learning_rate传入初始lr值,global_step用于逐步计算衰减指数,decay_steps用于决定衰减周期,decay_rate是每次衰减的倍率,staircase若为False则是标准的指数型衰减,True时则是阶梯式的衰减方法,目的是为了在一段时间内(往往是相同的epoch内)保持相同的learning rate。
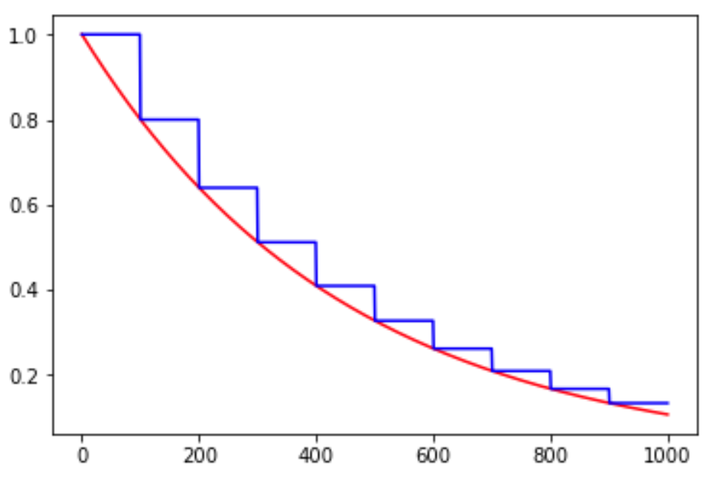
图1. exponential_decay示例,其中红色线条是staircase=False,即指数型下降曲线,蓝色线条是staircase=True,即阶梯式下降曲线
该衰减方法的优点是收敛速度较快,简单直接。
piecewise_constant
piecewise_constant(x, boundaries, values, name=None)
分段常数下降法类似于exponential_decay中的阶梯式下降法,不过各阶段的值是自己设定的。
其中,x即为global step,boundaries=[step_1, step_2, ..., step_n]定义了在第几步进行lr衰减,values=[val_0, val_1, val_2, ..., val_n]定义了lr的初始值和后续衰减时的具体取值。需要注意的是,values应该比boundaries长一个维度。
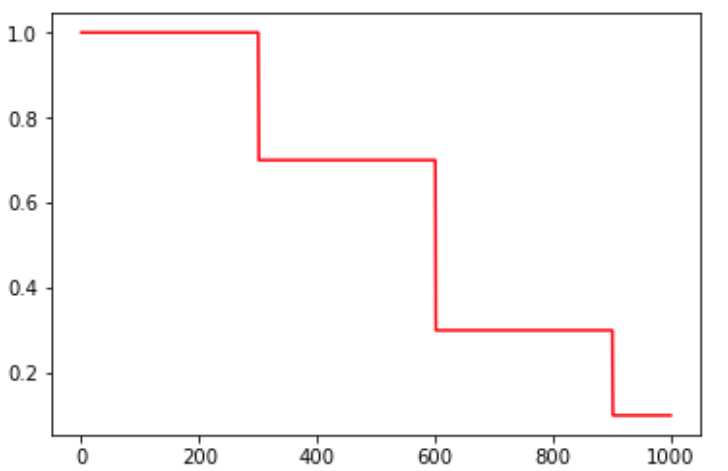
图2. piecewise_constant示例
这种方法有助于使用者针对不同任务进行精细地调参,在任意步长后下降任意数值的learning rate。
polynomial_decay
polynomial_decay(learning_rate, global_step, decay_steps,
end_learning_rate=0.0001, power=1.0,
cycle=False, name=None)
polynomial_decay是以多项式的方式衰减学习率的。
It is commonly observed that a monotonically decreasing learning rate, whose degree of change is carefully chosen, results in a better performing model.
This function applies a polynomial decay function to a provided initial `learning_rate` to reach an `end_learning_rate` in the given `decay_steps`.
其下降公式也在函数注释中阐释了:
global_step = min(global_step, decay_steps)
decayed_learning_rate = (learning_rate - end_learning_rate) *
(1 - global_step / decay_steps) ^ (power) + end_learning_rate

图3. polynomial_decay示例,cycle=False,其中红色线为power=1,即线性下降;蓝色线为power=0.5,即开方下降;绿色线为power=2,即二次下降
cycle参数是决定lr是否在下降后重新上升的过程。cycle参数的初衷是为了防止网络后期lr十分小导致一直在某个局部最小值中振荡,突然调大lr可以跳出注定不会继续增长的区域探索其他区域。
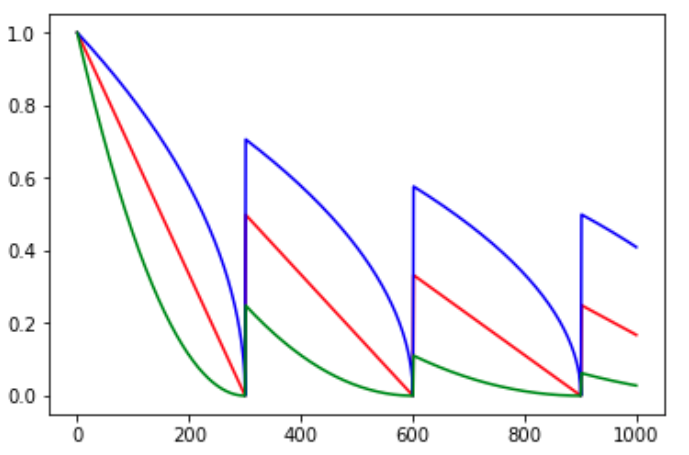
图4. polynomial_decay示例,cycle=True,颜色同上
natural_exp_decay
natural_exp_decay(learning_rate, global_step, decay_steps, decay_rate,
staircase=False, name=None)
natural_exp_decay和exponential_decay形式差不多,只不过自然指数下降的底数是 型。
exponential_decay:
decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps)
natural_exp_decay:
decayed_learning_rate = learning_rate * exp(-decay_rate * global_step / decay_steps)
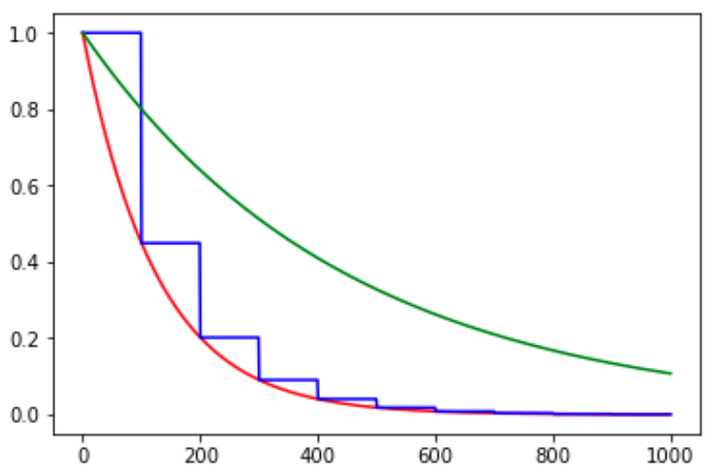
图5. natural_exp_decay与exponential_decay对比图,其中红色线为natural_exp_decay,蓝色线为natural_exp_decay的阶梯形曲线,绿线为exponential_decay
由图可知,自然数指数下降比exponential_decay要快许多,适用于较快收敛,容易训练的网络。
inverse_time_decay
inverse_time_decay(learning_rate, global_step, decay_steps, decay_rate,
staircase=False, name=None)
inverse_time_decay为倒数衰减,衰减公式如下所示:
decayed_learning_rate = learning_rate / (1 + decay_rate * global_step / decay_step)
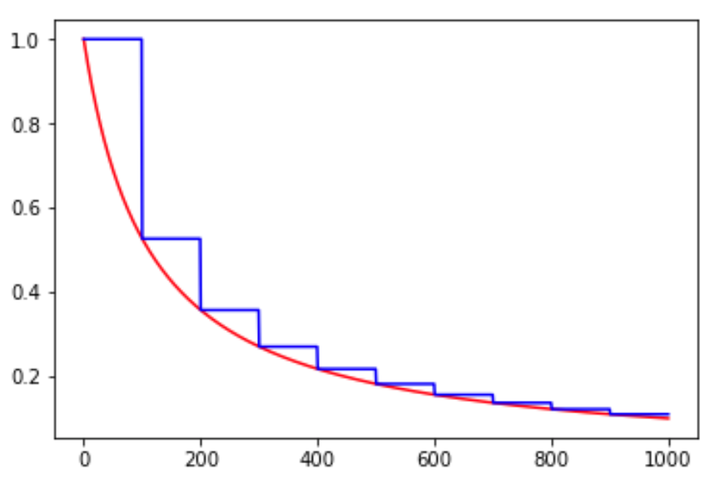
图6. inverse_time_decay示例
以上几种衰减方式相差不大,主要都是基于指数型的衰减。个人理解其问题在于一开始lr就快速下降,在复杂问题中可能会导致快速收敛于局部最小值而没有较好地探索一定范围内的参数空间。
cosine_decay
cosine_decay(learning_rate, global_step, decay_steps, alpha=0.0,
name=None)
cosine_decay是近一年才提出的一种lr衰减策略,基本形状是余弦函数。其方法是基于论文实现的:SGDR: Stochastic Gradient Descent with Warm Restarts
计算步骤如下:
global_step = min(global_step, decay_steps)
cosine_decay = 0.5 * (1 + cos(pi * global_step / decay_steps))
decayed = (1 - alpha) * cosine_decay + alpha
decayed_learning_rate = learning_rate * decayed
alpha的作用可以看作是baseline,保证lr不会低于某个值。不同alpha的影响如下:
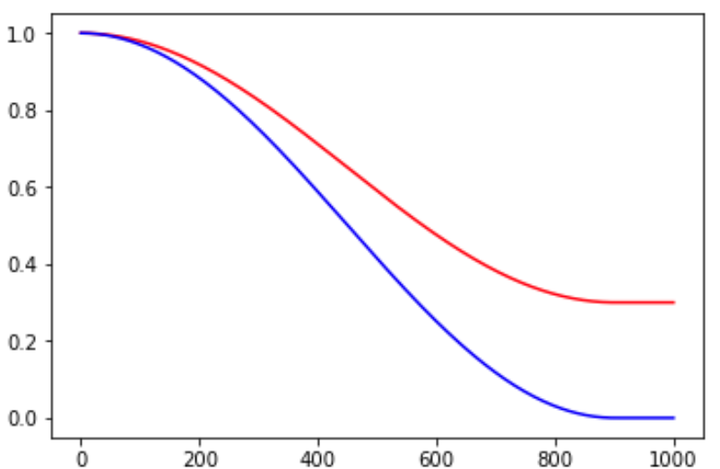
图7. cosine_decay示例,其中红色线的alpha=0.3,蓝色线的alpha=0.0
cosine_decay_restarts
cosine_decay_restarts(learning_rate, global_step, first_decay_steps,
t_mul=2.0, m_mul=1.0, alpha=0.0, name=None)
cosine_decay_restarts是cosine_decay的cycle版本。first_decay_steps是指第一次完全下降的step数,t_mul是指每一次循环的步数都将乘以t_mul倍,m_mul指每一次循环重新开始时的初始lr是上一次循环初始值的m_mul倍。
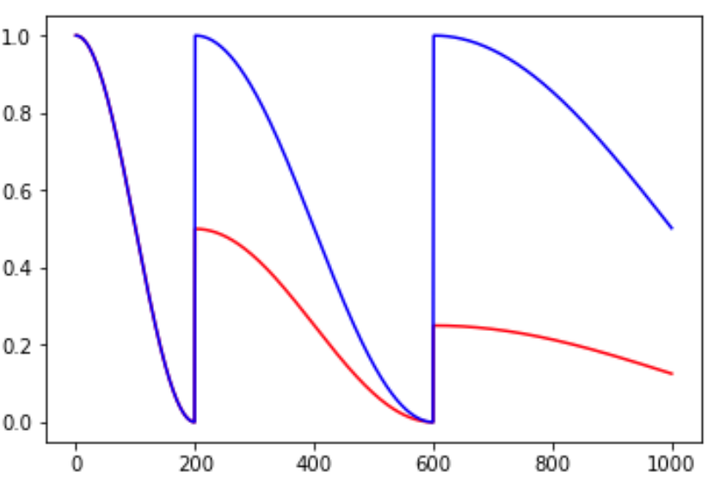
图8. cosine_decay_restarts示例,红色线条t_mul=2.0,m_mul=0.5,蓝色线条t_mul=2.0,m_mul=1.0
余弦函数式的下降模拟了大lr找潜力区域然后小lr快速收敛的过程,加之restart带来的cycle效果,有涨1-2个点的可能。
linear_cosine_decay
linear_cosine_decay(learning_rate, global_step, decay_steps,
num_periods=0.5, alpha=0.0, beta=0.001,
name=None)
linear_cosine_decay的参考文献是Neural Optimizer Search with RL,主要应用领域是增强学习领域,本人未尝试过。可以看出,该方法也是基于余弦函数的衰减策略。
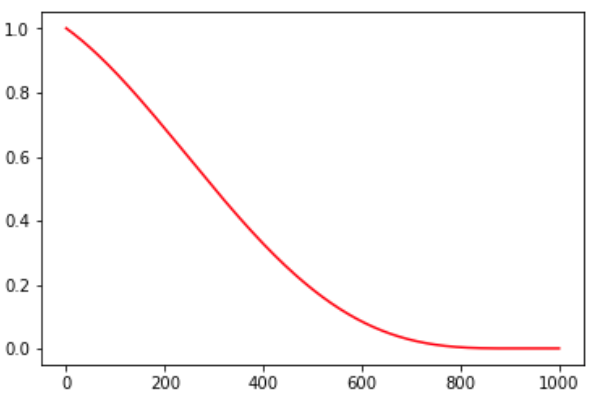
图9. linear_cosine_decay示例
noisy_linear_cosine_decay
noisy_linear_cosine_decay(learning_rate, global_step, decay_steps,
initial_variance=1.0, variance_decay=0.55,
num_periods=0.5, alpha=0.0, beta=0.001,
name=None)
参考文献同上。该方法在衰减过程中加入了噪声,某种程度上增加了lr寻找最优值的随机性和可能性。

图10.noisy_linear_cosine_decay示例
auto_learning_rate_decay
当然大家还可以自定义学习率衰减策略,如设置检测器监控valid的loss或accuracy值,若一定时间内loss持续有效下降/acc持续有效上升则保持lr,否则下降;loss上升/acc下降地越厉害,lr下降的速度就越快等等自适性方案。
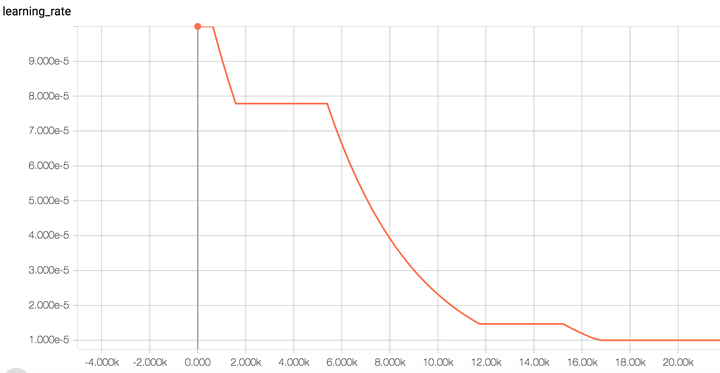
图11. auto_learning_rate_decay效果示例
最后,祝大家炼丹愉快!