1.安装xgboost后导入
import xgboost
2. 训练并使用模型进行预测
# First XGBoost model for Pima Indians dataset
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# split data into train and test sets
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# fit model no training data
model = XGBClassifier()
model.fit(X_train, y_train)
# make predictions for test data
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
运行结果:

3.xgboost.fit()函数讲解
fit(X, y, sample_weight=None, eval_set=None, eval_metric=None, early_stopping_rounds=None, verbose=True, xgb_model=None, sample_weight_eval_set=None, callbacks=None)
- X:就是我们的特征矩阵,就是x_train,这里一般是用交叉验证
- y:就是我们的标签,就是y_train,这里一般是用交叉验证
- sample_weight:每个实例的权重,不常用
- eval_set用来作为早期停止的验证集,一般我们放x_test和y_test
- sample_weight_eval_set:验证集上的实例权重列表,不常用
- eval_metric:不是很了解,感觉用的不多
- early_stopping_rounds:我们设置一个常数n,直到模型n次得分基本不变就停止
- verbose:如果为真,并且使用了一个验证集,则写下验证过程
- xgb_model:存储的xgb模型或“boost”实例xgb模型的文件名将在训练前加载
- callbacks:不常用,不知道
4. xgboost训练
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# split data into train and test sets
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# fit model no training data
model = XGBClassifier()
eval_set = [(X_test, y_test)]
### fit model for train data
# fit函数参数:eval_set=[(x_test,y_test)] 评估数据集,list类型
# fit函数参数:eval_metric="mlogloss" 评估标准(多分类问题,使用mlogloss作为损失函数)
# fit函数参数:early_stopping_rounds= 10 如果模型的loss十次内没有减小,则提前结束模型训练
# fit函数参数:verbose = True True显示,False不显示
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True)
# make predictions for test data
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
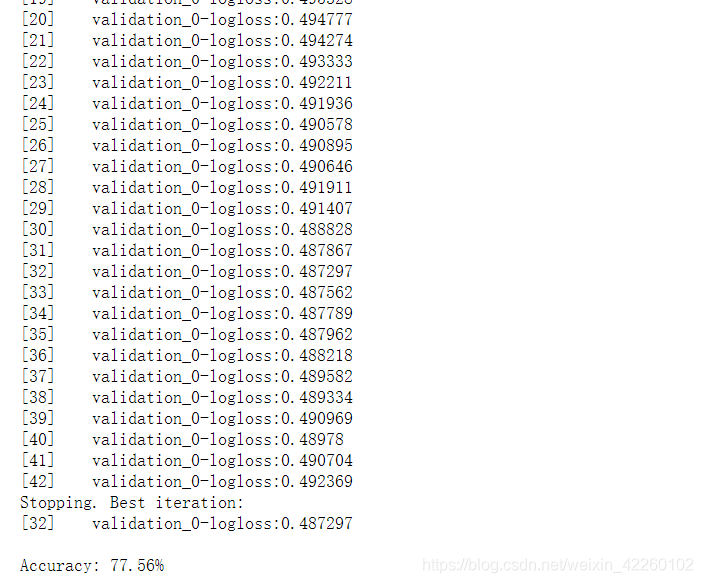
5.每个特征的重要程度
from numpy import loadtxt
from xgboost import XGBClassifier
from xgboost import plot_importance
from matplotlib import pyplot
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
y = dataset[:,8]
# fit model no training data
model = XGBClassifier()
model.fit(X, y)
# plot feature importance
plot_importance(model)
pyplot.show()

6.参数调节
# Tune learning_rate
from numpy import loadtxt
from xgboost import XGBClassifier
# 遍历学习率
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import StratifiedKFold
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# grid search
model = XGBClassifier()
learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]
# GridSearchCV要求的格式
param_grid = dict(learning_rate=learning_rate)
# 交叉验证
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold)
grid_result = grid_search.fit(X, Y)
# summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
params = grid_result.cv_results_['params']
for mean, param in zip(means, params):
print("%f with: %r" % (mean, param))

7.参数学习
常规参数
booster
gbtree 树模型做为基分类器(默认)
gbliner 线性模型做为基分类器
silent
silent=0时,不输出中间过程(默认)
silent=1时,输出中间过程
nthread
nthread=-1时,使用全部CPU进行并行运算(默认)
nthread=1时,使用1个CPU进行运算。
scale_pos_weight
正样本的权重,在二分类任务中,当正负样本比例失衡时,设置正样本的权重,模型效果更好。例如,当正负样本比例为1:10时,scale_pos_weight=10。
模型参数
n_estimatores
含义:总共迭代的次数,即决策树的个数
调参:
early_stopping_rounds
含义:在验证集上,当连续n次迭代,分数没有提高后,提前终止训练。
调参:防止overfitting。
max_depth
含义:树的深度,默认值为6,典型值3-10。
调参:值越大,越容易过拟合;值越小,越容易欠拟合。
min_child_weight
含义:默认值为1,。
调参:值越大,越容易欠拟合;值越小,越容易过拟合(值较大时,避免模型学习到局部的特殊样本)。
subsample
含义:训练每棵树时,使用的数据占全部训练集的比例。默认值为1,典型值为0.5-1。
调参:防止overfitting。
colsample_bytree
含义:训练每棵树时,使用的特征占全部特征的比例。默认值为1,典型值为0.5-1。
调参:防止overfitting。
学习任务参数
learning_rate
含义:学习率,控制每次迭代更新权重时的步长,默认0.3。
调参:值越小,训练越慢。
典型值为0.01-0.2。
objective 目标函数
回归任务
reg:linear (默认)
reg:logistic
二分类
binary:logistic 概率
binary:logitraw 类别
多分类
multi:softmax num_class=n 返回类别
multi:softprob num_class=n 返回概率
rank:pairwise
eval_metric
回归任务(默认rmse)
rmse--均方根误差
mae--平均绝对误差
分类任务(默认error)
auc--roc曲线下面积
error--错误率(二分类)
merror--错误率(多分类)
logloss--负对数似然函数(二分类)
mlogloss--负对数似然函数(多分类)
gamma
惩罚项系数,指定节点分裂所需的最小损失函数下降值。
调参:
alpha
L1正则化系数,默认为1
lambda
L2正则化系数,默认为1
例如
xgb1 = XGBClassifier(
learning_rate =0.1,
n_estimators=1000,
max_depth=5,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',
nthread=4,
scale_pos_weight=1,
seed=27)
