xgboost算法原理与实战
之前一直有听说GBM,GBDT(Gradient Boost Decision Tree)渐进梯度决策树GBRT(Gradient Boost RegressionTree)渐进梯度回归树是GBDT的一种,因为GBDT核心是累加所有树的结果作为最终结果,而分类树的结果是没法累加的,所以GBDT中的树都是回归树,不是分类树。
XGBoost(eXtreme Gradient Boosting)是工业界逐渐风靡的基于GradientBoosting算法的一个优化的版本,可以给预测模型带来能力的提升。
回归树的分裂结点对于平方损失函数,拟合的就是残差;对于一般损失函数(梯度下降),拟合的就是残差的近似值,分裂结点划分时枚举所有特征的值,选取划分点。 最后预测的结果是每棵树的预测结果相加。
xgboost算法的步骤和GB基本相同,都是首先初始化为一个常数,gb是根据一阶导数ri,xgboost是根据一阶导数gi和二阶导数hi,迭代生成基学习器,相加更新学习器。
xgboost的优化:
- 在寻找最佳分割点时,考虑传统的枚举每个特征的所有可能分割点的贪心法效率太低,xgboost实现了一种近似的算法。大致的思想是根据百分位法列举几个可能成为分割点的候选者,然后从候选者中根据上面求分割点的公式计算找出最佳的分割点。
- xgboost考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率,paper提到50倍.
- 特征列排序后以块的形式存储在内存中,在迭代中可以重复使用;虽然boosting算法迭代必须串行,但是在处理每个特征列时可以做到并行。
- 按照特征列方式存储能优化寻找最佳的分割点,但是当以行计算梯度数据时会导致内存的不连续访问,严重时会导致cache miss,降低算法效率。paper中提到,可先将数据收集到线程内部的buffer,然后再计算,提高算法的效率。
- xgboost 还考虑了当数据量比较大,内存不够时怎么有效的使用磁盘,主要是结合多线程、数据压缩、分片的方法,尽可能的提高算法的效率。
xgboost的优势:
1、正则化
- 标准GBM的实现没有像XGBoost这样的正则化步骤。正则化对减少过拟合也是有帮助的。
实际上,XGBoost以“正则化提升(regularized boosting)”技术而闻名。
2、并行处理
- XGBoost可以实现并行处理,相比GBM有了速度的飞跃,LightGBM也是微软最新推出的一个速度提升的算法。 XGBoost也支持Hadoop实现。
3、高度的灵活性
- XGBoost 允许用户定义自定义优化目标和评价标准 。
4、缺失值处理
- XGBoost内置处理缺失值的规则。用户需要提供一个和其它样本不同的值,然后把它作为一个参数传进去,以此来作为缺失值的取值。XGBoost在不同节点遇到缺失值时采用不同的处理方法,并且会学习未来遇到缺失值时的处理方法。
5、剪枝
- 当分裂时遇到一个负损失时,GBM会停止分裂。因此GBM实际上是一个贪心算法。XGBoost会一直分裂到指定的最大深度(max_depth),然后回过头来剪枝。如果某个节点之后不再有正值,它会去除这个分裂。
这种做法的优点,当一个负损失(如-2)后面有个正损失(如+10)的时候,就显现出来了。GBM会在-2处停下来,因为它遇到了一个负值。但是XGBoost会继续分裂,然后发现这两个分裂综合起来会得到+8,因此会保留这两个分裂。
6、内置交叉验证
- XGBoost允许在每一轮boosting迭代中使用交叉验证。因此,可以方便地获得最优boosting迭代次数。
而GBM使用网格搜索,只能检测有限个值。
7、在已有的模型基础上继续
- XGBoost可以在上一轮的结果上继续训练。
sklearn中的GBM的实现也有这个功能,两种算法在这一点上是一致的。
xgboost在kaggle上的实战:
Kaggle是一个数据分析的竞赛平台,企业或者研究者可以将数据、问题描述、期望的指标发布到Kaggle上,以竞赛的形式向广大的数据科学家征集解决方案,类似于KDD-CUP(国际知识发现和数据挖掘竞赛)。Kaggle上的参赛者将数据下载下来,分析数据,然后运用机器学习、数据挖掘等知识,建立算法模型,解决问题得出结果,最后将结果提交。
kaggle最近刚被google收购,感觉一大批Google赛题即将到达战场。kaggle上的很多预测模型都是基于xgboost,而且往往预测结果非常理想。下面是用法:
xgb_params = {
‘eta’: 0.05,
‘max_depth’: 5,
‘subsample’: 0.7,
‘colsample_bytree’: 0.7,
‘objective’: ‘reg:linear’,
‘eval_metric’: ‘rmse’,
‘silent’: 1
}

//xgboost加载数据为DMatrix对象
dtrain = xgb.DMatrix(x_train, y_train)
dtest = xgb.DMatrix(x_test)
//xgboost交叉验证并输出rmse
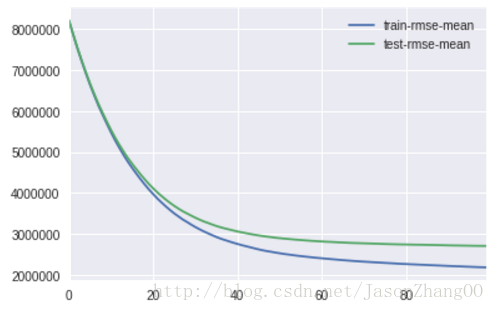
cv_output = xgb.cv(xgb_params, dtrain, num_boost_round=100, early_stopping_rounds=20,
verbose_eval=50, show_stdv=False)
cv_output[[‘train-rmse-mean’, ‘test-rmse-mean’]].plot()
//xgboost训练模型
num_boost_rounds = len(cv_output)
model = xgb.train(dict(xgb_params, silent=0), dtrain, num_boost_round= num_boost_rounds)
//xgboost参数设置
- params 这是一个字典,里面包含着训练中的参数关键字和对应的值,形式是params =
{‘booster’:’gbtree’,’eta’:0.1} - dtrain 训练的数据
- num_boost_round 这是指提升迭代的个数
- evals 这是一个列表形式是evals = [(dtrain,’train’),(dval,’val’)]或者是evals =
[(dtrain,’train’)],对于第一种情况,它使得我们可以在训练过程中观察验证集的效果 - obj,自定义目的函数
- feval,自定义评估函数
- maximize ,是否对评估函数进行最大化
- early_stopping_rounds,早期停止次数假设为100,验证集的误差迭代到一定程度在100次内不能再继续降低,就停止迭代
- verbose_eval ,如果为True,则evals中元素的评估结果会输出在结果中;如果输入数字,假设为5,则每隔5个迭代输出一次。
- learning_rates 每一次提升的学习率
- xgb_model ,在训练之前用于加载的xgb model
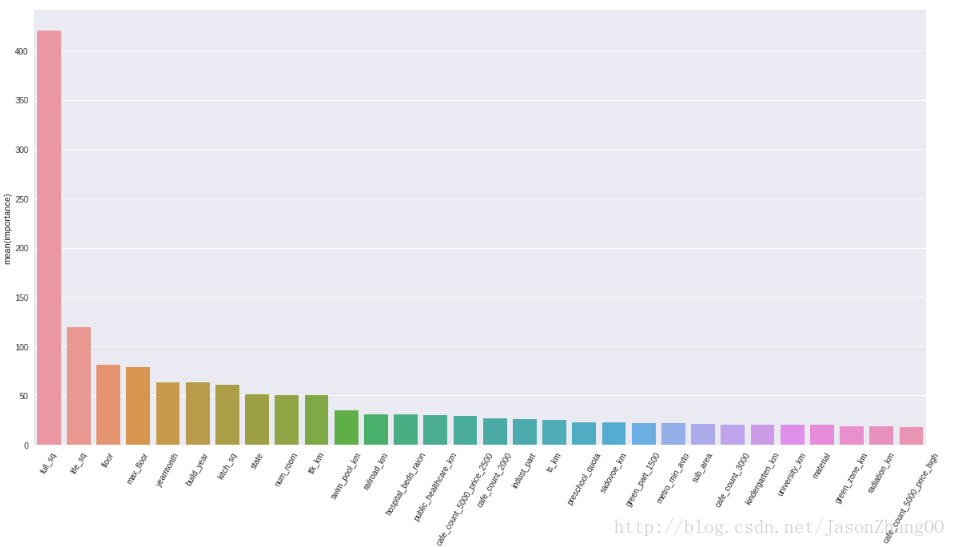
//显示xgboost模型中比较重要的几个feature
featureImportance = model.get_fscore()
features = pd.DataFrame()
features[‘features’] = featureImportance.keys()
features[‘importance’] = featureImportance.values()
features.sort_values(by=[‘importance’],ascending=False,inplace=True)
fig,ax= plt.subplots()
fig.set_size_inches(20,10)
plt.xticks(rotation=60)
sn.barplot(data=features.head(30),x=”features”,y=”importance”,ax=ax,orient=”v”)