版权声明:(欢迎转载,转载请注明出处。欢迎沟通交流:[email protected]) https://blog.csdn.net/Yasin0/article/details/82154768
1 XGBoost原理
留空待补充
2 XGBoost使用举例
(1)以印度糖尿病人预测为例讲解XGBoost的使用
# 以印度糖尿病人预测为例进行练习使用XGBoost
import xgboost
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 使用numpy库导入数据
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# 指定数据集特征和标签
X = dataset[:,0:8]
Y = dataset[:,8]
# 将数据集分为训练集和测试集
seed = 7
test_size = 0.33
# 使用sklearn函数进行划分
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# 训练模型
model = XGBClassifier()
eval_set = [(X_test, y_test)]
# 第3个参数为:如果连续10次损失函数值没有下降就使用最后一个最好的参数
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True)
# 测试模型效果
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# 计算准确率
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))

(2)使用XGBoost进行特征选择
import xgboost
from numpy import loadtxt
from xgboost import XGBClassifier
from xgboost import plot_importance
from matplotlib import pyplot
# 加载数据
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
#指定数据集特征和标签
X = dataset[:,0:8]
y = dataset[:,8]
# 训练模型
model = XGBClassifier()
model.fit(X, y)
# 找出最佳特征
plot_importance(model)
pyplot.show()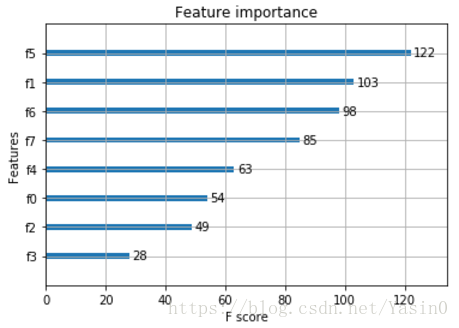
(3)XGBoost参数调节
# 调整学习率
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import StratifiedKFold
# 加载数据集
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# 指定数据集的特征和标签
X = dataset[:,0:8]
Y = dataset[:,8]
# 网格搜索
model = XGBClassifier()
learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]
param_grid = dict(learning_rate=learning_rate)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold)
grid_result = grid_search.fit(X, Y)
# 打印结果
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
params = grid_result.cv_results_['params']
for mean, param in zip(means, params):
print("%f with: %r" % (mean, param))

一般会对以下几个变量进行参数调整(学习率,决策树参数,正则化参数):
1.learning rate
2.tree(我们的分类器以决策树为基分类器进行集成)
max_depth
min_child_weight
subsample, colsample_bytree
gamma
3.正则化参数
lambda
alpha
如:
xgb1 = XGBClassifier(
learning_rate =0.1,
n_estimators=1000,
max_depth=5,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',
nthread=4,
scale_pos_weight=1,
seed=27)