https://www.zybuluo.com/Dounm/note/1031900
GBDT算法详解
http://mlnote.com/2016/10/05/a-guide-to-xgboost-A-Scalable-Tree-Boosting-System/
XGboost: A Scalable Tree Boosting System论文及源码导读
- 2016/10/29XGboost核心源码阅读
- 2016/10/05XGboost: A Scalable Tree Boosting System论文及源码导读
- 2016/11/18简述FastDBT和LightGBM中GBDT的实现
- 2016/10/29XGboost核心源码阅读
- 2016/10/05XGboost: A Scalable Tree Boosting System论文及源码导读
- 2016/10/02Gradient Boosting Decision Tree[下篇]
- 2016/09/24Gradient Boosting Decision Tree[上篇]
xgboost 解读(2)——近似分割算法
zhihu:
-如何理解 Bregman 散度?
-有哪些指标可以描述两个图(graph)的相似度?
-CNN模型可以输入离散特征吗?
- xgboost 如何使用MAE或MAPE作为目标函数?
-graph convolution network 有什么比较好的应用task?
-清华大学孙茂松组:图神经网络必读论文列表
- 深度学习时代的图模型,清华发文综述图网络
XGBoost 解读(2)——近似分割算法
https://yxzf.github.io/2017/04/xgboost-v2/
exact greedy -> 大数据量时 近似算法寻找分割点
https://yxzf.github.io/2017/03/xgboost-v1/
DNN在CTR预估上的应用
1.CTR预估
CTR预估是计算广告中最核心的算法之一,那么CTR预估是指什么呢?简单来说,CTR预估是对每次广告的点击情况做出预测,预测用户是点击还是不点击。具体定义可以参考 CTR. CTR预估和很多因素相关,比如历史点击率、广告位置、时间、用户等。CTR预估模型就是综合考虑各种因素、特征,在大量历史数据上训练得到的模型。CTR预估的训练样本一般从历史log、离线特征库获得。样本标签相对容易,用户点击标记为1,没有点击标记为0. 特征则会考虑很多,例如用户的人口学特征、广告自身特征、广告展示特征等。这些特征中会用到很多类别特征,例如用户所属职业、广告展示的IP地址等。一般对于类别特征会采样One-Hot编码,例如职业有三种:学生、白领、工人,那么会会用一个长度为3的向量分别表示他们:[1, 0, 0]、[0, 1, 0]、[0, 0, 1]. 可以这样会使得特征维度扩展很大,同时特征会非常稀疏。目前很多公司的广告特征库都是上亿级别的。
2.DNN
深度神经网络(DNN)近年来在图像、语音、自然语言等领域大放异彩,特别是在图像分类、语音识别、机器翻译方面DNN已经超过人,精度已经达到商业应用程度。不过,DNN在CTR预估这种场景的应用却仍在摸索中。图像、语言、自然语言领域的数据一般是连续的,局部之间存在某些结构。比如,图像的局部与其周围存在着紧密的联系;语音和文字的前后存在强相关性。但是CTR预估的数据如前面介绍,是非常离散的,特征前后之间的关系很多是我们排列的结果,并非本身是相互联系的。
3.Embeding
Neural Network是典型的连续值模型,而CTR预估的输入更多时候是离散特征,因此一个自然的想法就是如何将将离散特征转换为连续特征。如果你对词向量模型熟悉的话,可以发现之间的共通点。在自然语言处理(NLP)中,为了将自然语言交给机器学习中的算法来处理,通常需要首先将语言数学化,词向量就是用来将语言中的词进行数学化的一种方式。
一种最简单的词向量方式是one-hot,但这么做不能很好的刻画词之间的关系(例如相似性),另外数据规模会非常大,带来维度灾难。因此Embeding的方法被提出,基本思路是将词都映射成一个固定长度的向量(向量大小远小于one-hot编码向量大些),向量中元素不再是只有一位是1,而是每一位都有值。将所有词向量放在一起就是一个词向量空间,这样就可以表达词之间的关系,同时达到降维的效果。
既然Embeding可以将离散的词表达成连续值的词向量,那么对于CTR中的类别特征也可以使用Embeding得到连续值向量,再和其他连续值特征构成NN的输入。下图就是这种思路的表达。
因此问题的关键就是采用何种Embeding技术将离线特征转换到离线空间。
3.1 FM Embeding
Factorization Machine是近年来在推荐、CTR预估中常用的一种算法,该算法在LR的基础上考虑交叉项,如下面公式所示:
FM在后半部分的交叉项中为每个特征都分配一个特征向量V,这其实可以看作是一种Embeding的方法。Dr.Zhang在文献[1]中提出一种利用FM得到特征的embeding向量并将其组合成dense real层作为DNN的输入的模型,FNN。FNN模型的具体设计如下:
Dr.Zhang在模型中做了一个假设,就是每个category field只有一个值为1,也就是每个field是个one-hot表达向量。field是指特征的种类,例如将特征occupation one-hot之后是三维向量,但这个向量都属于一个field,就是occupation。这样虽然离散化后的特征有几亿,但是category field一般是几十到几百。 模型得到每个特征的Embeding向量后,将特征归纳到其属于field,得到向量z,z的大小就是1+#fields * #embeding 。z是一个固定长度的向量之后再在上面加入多个隐藏层最终得到FNN模型。
Dr.Zhang在FNN模型的基础上又提出了下面的新模型PNN. PNN和FNN的主要不同在于除了得到z向量,还增加了一个p向量,即Product向量。Product向量由每个category field的feature vector做inner product 或则 outer product 得到,作者认为这样做有助于特征交叉。另外PNN中Embeding层不再由FM生成,可以在整个网络中训练得到。
3.2 NN Embeding
 Google团队最近提出Wide and Deep Model。在他们的模型中,Wide Models其实就是LR模型,输入原始的特征和一些交叉组合特征;Deep Models通过Embeding层将稀疏的特征转换为稠密的特征,再使用DNN。最后将两个模型Join得到整个大模型,他们认为模型具有memorization and generalization特性。 Wide and Deep Model中原始特征既可以是category,也可以是continue,这样更符合一般的场景。另外Embeding层是将每个category特征分别映射到embeding size的向量,如他们在TensorFlow代码中所示:
Google团队最近提出Wide and Deep Model。在他们的模型中,Wide Models其实就是LR模型,输入原始的特征和一些交叉组合特征;Deep Models通过Embeding层将稀疏的特征转换为稠密的特征,再使用DNN。最后将两个模型Join得到整个大模型,他们认为模型具有memorization and generalization特性。 Wide and Deep Model中原始特征既可以是category,也可以是continue,这样更符合一般的场景。另外Embeding层是将每个category特征分别映射到embeding size的向量,如他们在TensorFlow代码中所示:
deep_columns = [
tf.contrib.layers.embedding_column(workclass, dimension=8),
tf.contrib.layers.embedding_column(education, dimension=8),
tf.contrib.layers.embedding_column(gender, dimension=8),
tf.contrib.layers.embedding_column(relationship, dimension=8),
tf.contrib.layers.embedding_column(native_country, dimension=8),
tf.contrib.layers.embedding_column(occupation, dimension=8),
age, education_num, capital_gain, capital_loss, hours_per_week]
4.结合图像
目前很多在线广告都是图片形式的,文献[4]提出将图像也做为特征的输入。这样原始特征就分为两类,图像部分使用CNN,非图像部分使用NN处理。 其实这篇文章并没有太多新颖的方法,只能说多了一种特征。对于非图像特征,作者直接使用全连接神经网络,并没有使用Embeding。
5.CNN
CNN用于提取局部特征,在图像、NLP都取得不错的效果,如果在CTR预估中使用却是个难题。我认为最大的困难时如何构建对一个样本构建如图像那样的矩阵,能够具有局部联系和结构。如果不能构造这样的矩阵,使用CNN是没有什么意思的。 文献[5]是发表在CIKM2015的一篇短文,文章提出对使用CNN来进行CTR预估进行了尝试。 一条广告展示(single ad impression)包括:element = (user; query; ad, impression time, site category, device type, etc) 用户是否点击一个广告与用户的历史ad impression有关。这样,一个样本将会是(s, label) ,s由多条l组成(数目不定)
作者提出CCPM模型处理这样的数据。每个样本有n个element,对每个element使用embeding 得到定长为d的向量
,再构造成一个矩阵
,得到s矩阵之后就可以套用CNN,后面的其实没有太多创新点。
6.RNN
考虑搜索场景下的CTR预估,如果考虑历史信息,如可以将一个用户的历史ad impression构成一个时间序列。RNN非常适合时间序列的场景,如语言建模等。这篇 发表在AAAI2014将RNN模型引入CTR预估。作者首先在数据集上验证了用户的点击行为与之前的ad impression历史有关联:
- 如果用户在之前的impression很快离开广告页面,那么将会在接下来一段时间内不会点击类似的广告
- 如果用户最近有过与广告相关的查询,那么接下来点击相关广告的可能性会大幅提升
- 前面的两种行为还可能随着间隔时间的增加而不是那么相关
当前关联不止这些,而且人工难以刻画,需要模型来自动提取。RNN模型对此类问题非常适用,作者的主要工作是将数据集构造成适合RNN的输入(即对用户的历史ad impression根据时间排序),对模型本身并没有改进。
参考文献
- Deep Learning over Multi-field Categorical Data – A Case Study on User Response Prediction
- Product-based Neural Networks for User Response Prediction
- Wide & Deep Learning for Recommender Systems
- Deep CTR Prediction in Display Advertising
- A Convolutional Click Prediction Model
- http://www.52cs.org/?p=1046
- http://techshow.ctrip.com/archives/1149.html
- http://tech.meituan.com/deep-understanding-of-ffm-principles-and-practices.html
- Sequential Click Prediction for Sponsored Search with Recurrent Neural Networks
CNN在NLP的应用--文本分类
刚接触深度学习时知道CNN一般用于计算机视觉,RNN等一般用于自然语言相关。CNN目前在CV领域独领风骚,自然就有想法将CNN迁移到NLP中。但是NLP与CV不太一样,NLP有语言内存的结构,所以最开始CNN在NLP领域的应用在文本分类。相比于具体的句法分析、语义分析的应用,文本分类不需要精准分析。本文主要介绍最近学习到几个算法,并用mxnet进行了实现,如有错误请大家指出。
1 Convolutional Neural Networks for Sentence Classification
1.1 原理
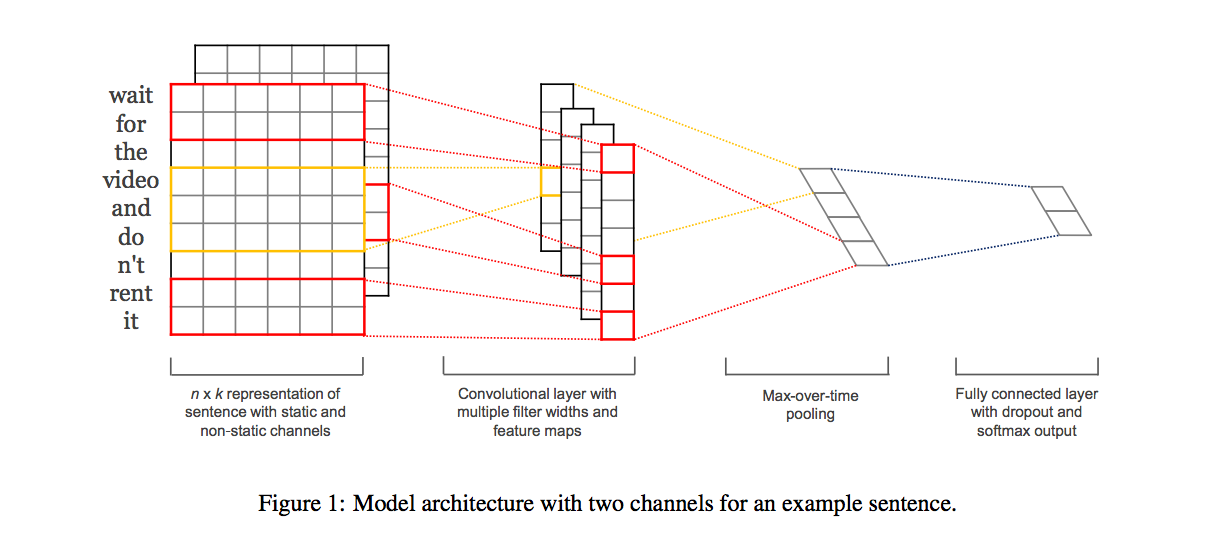 CNN的输入是矩阵形式,因此首先是构造矩阵。句子有词构成,DL中一般使用词向量,再对句子的长度设置一个固定值(可以是最大长度),那么就可以构造一个矩阵,这样就可以应用CNN了。这篇论文就是这样的思想,如上图所示。
CNN的输入是矩阵形式,因此首先是构造矩阵。句子有词构成,DL中一般使用词向量,再对句子的长度设置一个固定值(可以是最大长度),那么就可以构造一个矩阵,这样就可以应用CNN了。这篇论文就是这样的思想,如上图所示。
输入层
句子长度为n,词向量的维度为k,那么矩阵就是n∗k。具体的,词向量可以是静态的或者动态的。静态指词向量提取利用word2vec等得到,动态指词向量是在模型整体训练过程中得到。
卷积层
一个卷积层的kernel大小为$hk,k为输入层词向量的维度,那么h为窗口内词的数目。这样可以看做为N−Gram的变种。如此一个卷积操作可以得到一个(n-h+1)1$的feature map。多个卷积操作就可以得到多个这样的feature map
池化层
这里面的池化层比较简单,就是一个Max-over-time Pooling,从前面的1维的feature map中取最大值。这篇文章中给出了NLP中CNN的常用Pooling方法。最终将会得到1维的size=m的向量(m=卷积的数目)
全连接+输出层
模型的输出层就是全连接+Softmax。可以加上通用的Dropout和正则的方法来优化
1.2 实现
这篇文章用TensorFlow实现了这个模型,代码。我参考这个代码用mxnet实现了,代码
2 Character-level Convolutional Networks for Text Classification
2.1 原理
图像的基本都要是像素单元,那么在语言中基本的单元应该是字符。CNN在图像中有效就是从原始特征不断向上提取高阶特征,那么在NLP中可以从字符构造矩阵,再应用CNN来做。这篇论文就是这个思路。 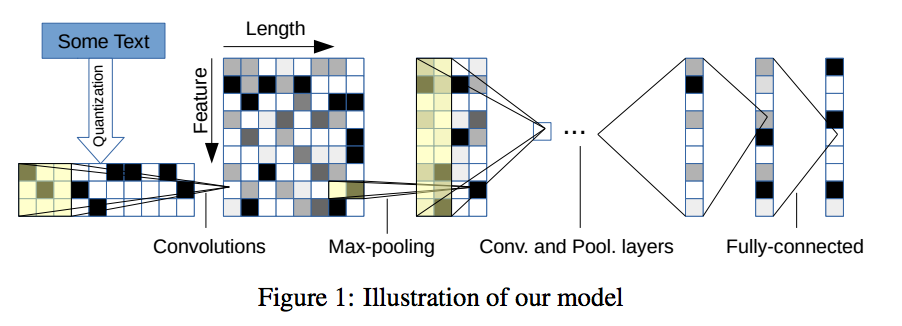
输入层
一个句子构造一个矩阵,句子由字符构成。设定一个句子的字符数目n(论文中n=1014)。每个字符是一个字符向量,这个字符向量可以是one-hot向量,也可以是一个char embeding. 设字符向量为k,那么矩阵为n∗k。
卷积层
这里的卷积层就是套用在图像领域的, 论文中给出具体的设置 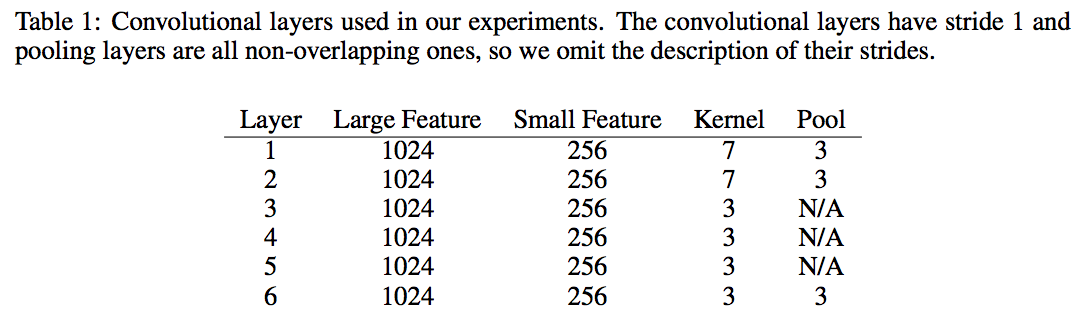
全连接+输出层
全连接层的具体设置如下 ![/images/deeplearning/cnn_nlp/model2_fc.png]
2.2 实现
代码给出了TensorFlow的实现,我用mxnet实现的代码
3 Character-Aware Neural Language Models
3.1 原理
这篇文章提出一种CNN+RNN结合的模型。CNN部分,每个单词由character组成,如果对character构造embeding向量,则可以对单词构造矩阵作为CNN的输入。CNN的输出为词向量,作为RNN的输入,RNN的输出则是以整个词为单位。 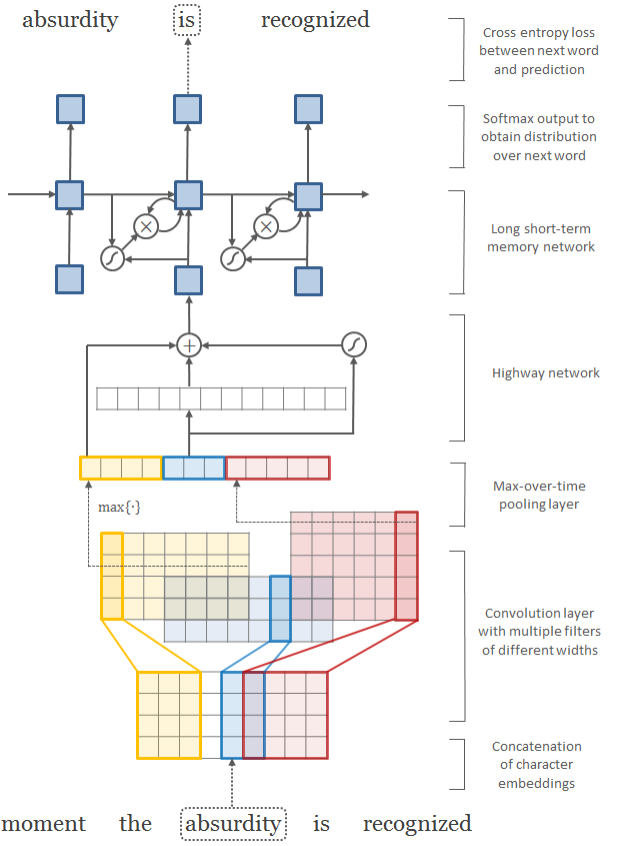
3.1.1 CNN层
输入层: 一个句子(sentence)是一个输入样本,句子由词(word)构成,词由字符(character)组成。每个字符学习一个embeding字符向量,设字符向量长度为k,那么一个word(长度为w)就可以构造成一个矩阵C(k∗w)
卷积层: 对这个矩阵C使用多个卷积层,每个卷积层的kernel大小为($kn)。卷积层可以看作是character的n−gram,那么每个卷积操作后得到的矩阵为(1(w-n+1)$)
池化层: 池化层仍是max-pooling,挑选出(w−n+1)长度向量中的最大值,将所有池化层的结果拼接就可以得到定长的向量p,p的长度为所有卷积层的数目
Highway层: Highway层是最近刚提出的一种结构,借鉴LSTM的gate概念。x为该层的输入,那么首先计算一个非线性转换T(x),T(x)∈[0,1](T一般为sigmod)。除了T(x),还有另外一个非线性转换H(x),最终的输出为y=T(x)∗H(x)+(1−T(x))∗x。从公式来看,T(x)充当了gate,如果T(x)=1,那么输出同传统的非线性层一样,输出是H(x),如果T(x)=0,则直接输出输入x。作者认为Highway层的引入避免了梯度的快速消失,这种特性可以构建更深的网络。
输出层: 每个单词将得到一个词向量,与一般的词向量获取不同,这里的词向量是DNN在character embeding上得到的。
3.1.2 RNN层
输入层: 将一个句子的每个CNN输出作为词向量,整个句子就是RNN的输入层
隐藏层: 一般使用LSTM,也可以是GRU
输出层: 输出层以word为单位,而不是character.
3.2实现
代码给出了TensorFlow的实现,我的MXNet实现见代码
参考资料
- https://github.com/Lasagne/Lasagne/blob/highway_example/examples/Highway%20Networks.ipynb
- http://www.jeyzhang.com/cnn-apply-on-modelling-sentence.html
- http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
- http://www.wtoutiao.com/p/H08qKy.html
- http://karpathy.github.io/2015/05/21/rnn-effectiveness/
- https://papers.nips.cc/paper/5782-character-level-convolutional-networks-for-text-classification.pdf
© 2017 YXZF's Blog powered by Jekyll + Skinny Bones.