MICCAI2019 多模分割相关论文笔记
Pairwise Semantic Segmentation via Conjugate Fully Convolutional Network
由于医学成像中手工标记的样本数量有限,FCN通常无法获得令人满意的结果。 在本文中作者提出了一种共轭全卷积网络(CFCN),通过将成对样本输入共同分割,以捕获丰富的上下文表示。设计融合模块提供额外的监督,避免少数训练样本的外观和形状变化引起过拟合。
介绍
考虑到语义分割是结构化的预测任务,位于不同2D/3D图像中的目标对象应具有一致的标签。这意味着一张3D图的不同切片、2D图像中不同的图像块通常在上下文、形状和位置之间具有内在联系。为了对这些固有关系进行建模,作者提出了共轭全卷积网络(CFCN)来成对分割医学目标。
方法
CFCN模型由三部分组成:编码器模块,解码器模块和融合模块。编码器模块以成对的样本作为输入并联合提取特征。 解码器模块由两个共轭子网络组成,这些共轭子网络以编码器模块中的低级和高级特征为输入,并在各自的GT的监督下学习两张图象不同的特征以,并对每个输入进行分割。 融合模块使用编码器模块中的低级特征的像素和,以及解码器模块中的高级特征的像素和,作为输入来获取辅助监督约束的位置特征。网络结构示意图如下所示:

- 编码器模块:有两个共享权重的并行全卷积子网,每个子网采用 ResNet-18,逐渐提取更多抽象特征。之后,两个子网中的每一个都跟随一个空洞空间金字塔池(ASPP)模块,以捕获多尺度语义信息。
- 解码器模块:由两个共轭卷积子网组成,用于分割成对输入的每个样本。 其中编码器的ASPP模块的高层特征由卷积层过滤,并向上采样到与 ResNet-18 输出的低层特征相同的大小与之进行拼接。 将生成的特征图馈入具有3×3卷积的卷积层中,并进行双线性上采样,使其大小与掩膜相同。
- 融合模块:其设计考虑了以下动机:第一个是类内不一致,不同图像/体积中的目标对象共享相同的语义标签但外观不同。第二个动机是以端到端的方式进行形状学习。作者设计了一个融合模块,通过训练过程中的辅助监督来学习位置感知功能。标签y用0、1、2分别表示两个输入像素均属于背景,某一个属于目标对象,每一个都属于目标对象。损失函数的表达式如下:

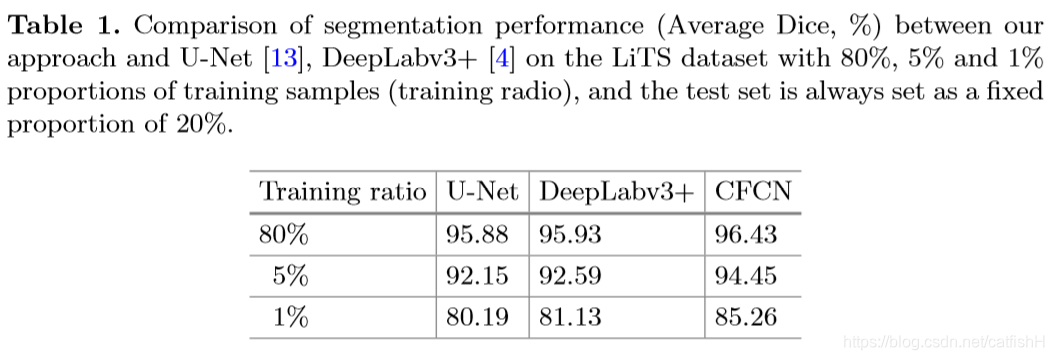
实验结果

总结
这篇文章通过增加一个单独的融合模块,在此处设置一个辅助损失,此处标签区分了两个GT中共有、独有部分,来达到信息共享的目的。主干网络结构是ASPP,特征被分为浅层和深层两个简单部分进行处理和融合,在融合模块部分用通道注意力从浅层特征中自适应学习上下文信息。
