Multiple Features
多元线性回归时含有多个变量的线性回归

包含多个特征变量的假设函数如下

同时,假设函数也可简化成以下向量形式
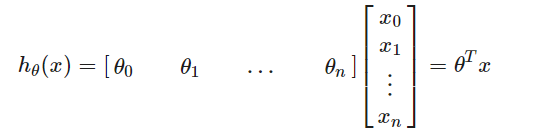
注意:为了方便,我们令x0=1,因此能够使θ与x逐元素匹配(n+1)。
Gradient Descent For Multiple Variables
多个变量的梯度下降
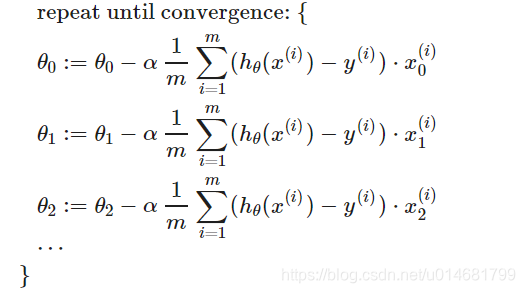
即:
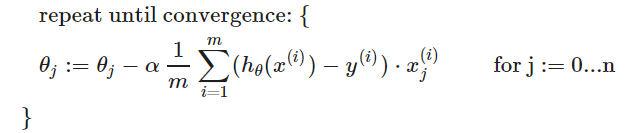
Gradient Descent in Practice I - Feature Scaling
我们可以通过将每个输入值都控制在近似的范围内来加快梯度下降的速度。因为θ在小范围内会迅速下降,而在大范围内会缓慢下降,因此当变量非常不均匀时,会无效率地振荡到最佳状态。
为了防止这种情况,我们通过修改输入变量的范围使它们大致相同,理想情况如下:
或:
我们可以使用两种方法特征缩小和均值归一化。
- 特征缩放涉及将输入值除以输入变量的范围(即最大值减去最小值),从而得到新范围仅为1。
- 均值归一化包括从输入变量的值中减去输入变量的平均值,从而使输入变量的新平均值仅为零。
其中,μi是所有特征值的平均值,si是值的范围(最大值-最小值)或者是标准偏差
例如:
xi代表房价,其范围使100-2000,平均值为1000,则
Gradient Descent in Practice II - Learning Rate
- 调试梯度下降
绘制x轴为迭代次数、y轴为J(θ)的图,如果J(θ)增加,则应该减小学习率α - 自动收敛测试
如果在一次迭代中J(θ)减小小于E(E为小值,如10-3),但是实际上,很难选择此阈值

已经证明,如果学习率α足够小,则J(θ)将在每次迭代中减小。
 如果α太小:收敛缓慢。
如果α太小:收敛缓慢。
如果 α太大:J(θ)可能不会在每次迭代中都减小,因此可能不会收敛。
Features and Polynomial Regression
我们可以通过几种不同的方式改进我们的特征和假设函数
- 可以将多个特征组合成一个,例如可以结合X1和X2成为新的X3,通过采取X1*X2
- 多项式回归:如果我们的假设函数不太适合数据,则不必是线性的(直线)。我们可以通过将其设为二次、三次或平方根函数等其他任何形式来更改假设函数的行为和曲线。
例如:我们的假设函数时hθ(x)=θ0+θ1x1,然后我们可以基于x1,创建二次函数hθ(x)=θ0+θ1x1+θ2x12或三次函数hθ(x)=θ0+θ1x1+θ2x12+θ3x13,在三次函数中,我们创建新的特征x2、x3,其中x2=x12,x3=x13
一个很重要的点:如果以这种方式选择了特征,那么特征缩放将非常重要。
如果x1的范围为1-100,那么x12的范围为1-10000,x13的范围为1-1000000
