首先,了解一下什么是matplotlib?
matplotlib: 最流行的Python底层绘图库,主要做数据可视化图表,名字取材于MATLAB,模仿MATLAB构建

目录
- 折线图:

- 以折线的上升或下降来表示统计数量的增减变化的统计图
- 特点:能够显示数据的变化趋势,反映事物的变化情况。(变化)
- 直方图:
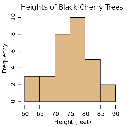
- 由一系列高度不等的纵向条纹或线段表示数据分布的情况。
- 一般用横轴表示数据范围,纵轴表示分布情况。
- 特点:绘制连续性的数据,展示一组或者多组数据的分布状况(统计)
- 条形图:

- 排列在工作表的列或行中的数据可以绘制到条形图中。
- 特点:绘制连离散的数据,能够一眼看出各个数据的大小,比较数据之间的差别。(统计)
- 散点图:

- 用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式。
- 特点:判断变量之间是否存在数量关联趋势,展示离群点(分布规律)
折线图
- 呈现公司产品(不同区域)每天活跃用户数
- 呈现app每天下载数量
- 呈现产品新功能上线后,用户点击次数随时间的变化
- 呈现员工每天上下班时间
例1:气温岁时间变化折线图
如果列表a表示10点到12点的每一分钟的气温,如何绘制折线图观察每分钟气温的变化情况?
a= [random.randint(20,35) for i in range(120)]from matplotlib import pyplot as plt
import random
# matplotlib显示中文配置方法:https://www.cnblogs.com/hhh5460/p/4323985.html
x =range(0,120)
y =[random.randint(20,35) for i in range(120)]
# 设置图形大小,并设置像素
plt.figure(figsize=(100,8), dpi=80)
# 绘制折线图
plt.plot(x,y)
# 调整x轴的刻度
_x = list(x) # 此处强制类型转换,因为只有列表才能取步长。
_xticks_lables = ["10点{}分".format(i) for i in range(60)]
_xticks_lables += ["11点{}分".format(i) for i in range(60)]
# 取步长x轴刻度数量要对应,数据和字符串进行对应,数据长度要一样120/3 == (60+60)/2
# 但是坐标显示比较密集,可以将x轴标签顺时针旋转45度
# 但是matplotlib不支持显示中文字体,使用fontproperties="SimHei"方便灵活,Ctrl+B查看源码进行设置
plt.xticks(_x[::3], _xticks_lables[::3], rotation=45, fontproperties="SimHei")
# 描述坐标轴信息,设置字体信息
plt.xlabel("时间",fontproperties="SimHei")
plt.ylabel("温度",fontproperties="SimHei")
plt.title("10点--12点每分钟气温变换的情况",fontproperties="SimHei")
plt.show()
# 保存图片至本地
plt.savefig("./pict.png")
例2:多个折线图---走势问题
假设大家在30岁的时候,根据自己的实际情况,统计出来了从11岁到30岁每年交的女(男)朋友的数量如列表a,请绘制出该数据的折线图,以便分析自己每年交女(男)朋友的数量走势 a = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1] 要求: y轴表示个数 x轴表示岁数,比如11岁,12岁等
from matplotlib import pyplot as plt
my_font = {
'family': 'SimHei',
'weight':'bold',
'size':'16'
}
x = range(11, 31)
y_1 = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]
y_2 = [1,0,3,1,2,2,3,3,2,1,2,1,1,1,1,1,1,1,1,1]
plt.xlabel("年龄",fontproperties='SimHei')
plt.ylabel("女朋友数量",rotation = 90,fontproperties='SimHei')
plt.title("11-30岁每年交往的女朋友数量",fontproperties='SimHei')
_x = list(x)
_xticks_lables = ['{}岁'.format(i) for i in _x]
plt.xticks(x, _xticks_lables, rotation = 45, fontproperties='SimHei')
# 合理化y轴数据分布,如果没有+/-2会导致有的数据位于边界之上
plt.yticks(range(min(min(y_1),min(y_2))-2, max(max(y_1), max(y_2))+2))
plt.plot(x, y_1,label="小明", color="orange", linestyle="--")
plt.plot(x, y_2,label="小花", color="cyan", linestyle=":")
# 绘制网格,alpha网格透明度
plt.grid(alpha=0.5,linestyle=':')
# 添加图例,前提是plt.plot时,将图例作为label传入了
# 图例内部的prop必须传入一个字典,loc位置的分布可利用Ctrl+B查看源码获取更多信息
plt.legend(prop=my_font, loc="upper left")
plt.show()

直方图
- 用户的年龄分布状态
- 一段时间内用户点击次数的分布状态
- 用户活跃时间的分布状态
数据分组进行统计
组数:将数据分为一些组,100以内的数据,常常分为5-12组。
组距(相邻两个小组之间的距离) = 极差[max(a)-min(a)] / 组距[bin_width]
组距设置:max(a)-min(a)刚好能被组距整除是最佳的选择!!!!
没有经过统计的数据才能绘制为直方图.plt.hist方法需要传入(原始数据+组距)进行统计,所以统计过的数据不能进行绘制直方图
例1:250部电影时长的频率分布直方图
假设你获取了250部电影的时长(列表a中),希望统计出这些电影时长的分布状态(比如时长为100分钟到120分钟电影的数量,出现的频率)等信息,你应该如何呈现这些数据?
a=[131, 98, 125, 131, 124, 139, 131, 117, 128, 108, 135, 138, 131, 102, 107, 114, 119, 128, 121, 142, 127, 130, 124, 101, 110, 116, 117, 110, 128, 128, 115, 99, 136, 126, 134, 95, 138, 117, 111,78, 132, 124, 113, 150, 110, 117, 86, 95, 144, 105, 126, 130,126, 130, 126, 116, 123, 106, 112, 138, 123, 86, 101, 99, 136,123, 117, 119, 105, 137, 123, 128, 125, 104, 109, 134, 125, 127,105, 120, 107, 129, 116, 108, 132, 103, 136, 118, 102, 120, 114,105, 115, 132, 145, 119, 121, 112, 139, 125, 138, 109, 132, 134,156, 106, 117, 127, 144, 139, 139, 119, 140, 83, 110, 102,123,107, 143, 115, 136, 118, 139, 123, 112, 118, 125, 109, 119, 133,112, 114, 122, 109, 106, 123, 116, 131, 127, 115, 118, 112, 135,115, 146, 137, 116, 103, 144, 83, 123, 111, 110, 111, 100, 154,136, 100, 118, 119, 133, 134, 106, 129, 126, 110, 111, 109, 141,120, 117, 106, 149, 122, 122, 110, 118, 127, 121, 114, 125, 126,114, 140, 103, 130, 141, 117, 106, 114, 121, 114, 133, 137, 92,121, 112, 146, 97, 137, 105, 98, 117, 112, 81, 97, 139, 113,134, 106, 144, 110, 137, 137, 111, 104, 117, 100, 111, 101, 110,105, 129, 137, 112, 120, 113, 133, 112, 83, 94, 146, 133, 101,131, 116, 111, 84, 137, 115, 122, 106, 144, 109, 123, 116, 111,111, 133, 150]
from matplotlib import pyplot as plt
a=[131, 98, 125, 131, 124, 139, 131, 117, 128, 108, 135, 138, 131, 102, 107, 114, 119, 128, 121, 142, 127, 130,
124, 101, 110, 116, 117, 110, 128, 128, 115, 99, 136, 126, 134, 95, 138, 117, 111,78, 132, 124, 113, 150,
110, 117, 86, 95, 144, 105, 126, 130,126, 130, 126, 116, 123, 106, 112, 138, 123, 86, 101, 99, 136,
123, 117, 119, 105, 137, 123, 128, 125, 104, 109, 134, 125, 127,105, 120, 107, 129, 116, 108, 132, 103,
136, 118, 102, 120, 114,105, 115, 132, 145, 119, 121, 112, 139, 125, 138, 109, 132, 134,156, 106, 117,
127, 144, 139, 139, 119, 140, 83, 110, 102,123,107, 143, 115, 136, 118, 139, 123, 112, 118, 125, 109,
119, 133,112, 114, 122, 109, 106, 123, 116, 131, 127, 115, 118, 112, 135,115, 146, 137, 116, 103, 144,
83, 123, 111, 110, 111, 100, 154,136, 100, 118, 119, 133, 134, 106, 129, 126, 110, 111, 109, 141,120,
117, 106, 149, 122, 122, 110, 118, 127, 121, 114, 125, 126,114, 140, 103, 130, 141, 117, 106, 114,
121, 114, 133, 137, 92,121, 112, 146, 97, 137, 105, 98, 117, 112, 81, 97, 139, 113,134, 106,
144, 110, 137, 137, 111, 104, 117, 100, 111, 101, 110,105, 129, 137, 112, 120, 113, 133, 112,
83, 94, 146, 133, 101,131, 116, 111, 84, 137, 115, 122, 106, 144, 109, 123, 116, 111,111, 133, 150]
# 数据分组进行统计
# 组数:将数据分为一些组,100以内的数据,常常分为5-12组。
# 组距:相邻两个小组之间的距离。
# 组距 = 极差[max(a)-min(a)] / 组距[bin_width]
print(len(a))# 计算组数
d = 3
# 组距设置:max(a)-min(a)刚好能被组距整除是最佳的选择!!!
num_bins = ((max(a)-min(a)) // d)
print(max(a)-min(a))
# 设置图形的大小
plt.figure(figsize=(20,8),dpi=80)
# 参数normed=True是频率分布直方图
plt.hist(a, num_bins, normed=True)
# 设置x轴的刻度,max(a)+d的原因是:最大值往往图形的边界,不易观察
plt.xticks(range(min(a),max(a)+d,d))
plt.grid()
plt.show()例2:抽样统计后的数据直方图可由条形图体现
在美国2004年人口普查发现有124 million的人在离家相对较远的地方工作。根据他们从家到上班地点所需要的时间,通过抽样统计(最后一列)出了下表的数据,这些数据能够绘制成直方图么?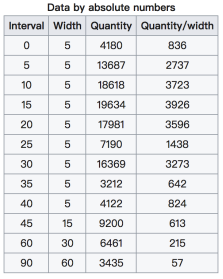
interval = [0,5,10,15,20,25,30,35,40,45,60,90]
width = [5,5,5,5,5,5,5,5,5,15,30,60]
quantity = [836,2737,3723,3926,3596,1438,3273,642,824,613,215,47]
为了绘制出直方图的效果,所以采用条形图来体现。因为:
给出的数据都是统计之后的数据, 所以为了达到直方图的效果,需要绘制条形图 所以:一般来说能够使用plt.hist方法的的是那些没有统计过的数据
from matplotlib import pyplot as plt
interval = [0,5,10,15,20,25,30,35,40,45,60,90]
# 距离
width = [5,5,5,5,5,5,5,5,5,15,30,60]
# 频率统计
quantity = [836,2737,3723,3926,3596,1438,3273,642,824,613,215,47]
# 人数分布
print(len(interval),len(width), len(quantity))
# X轴分布12个数据
plt.figure(figsize=(20,8),dpi=80)
# width的控制可选为默认(0.8),为了体现直方图,彼此条状之间应该连接在一起
plt.bar(range(12), quantity, width=1)
# X轴实际刻度应该通过xticks与序号对应起来。width=1,为了让interval显示在条柱的中间,故每个数据右移0.5
_x = [i-0.5 for i in range(13)]
_xticks_labels = interval + [150] # 因为最后一个条柱的数据需要根据interval和width计算
plt.xticks(_x, _xticks_labels)
plt.xlabel("家里公司距离/km", fontproperties="SimHei")
plt.ylabel("员工数量/人", fontproperties="SimHei")
plt.title("美国2004年人口普查中家到上班地点所需要的时间抽样统计",fontproperties="SimHei")
plt.grid()
plt.show()
条形图
- 数量统计
- 频率统计(市场饱和度)
数据彼此之间无太多的关联,比如:战狼2和功夫瑜伽无太多联系
例1:内地电影票房前20
假设你获取到了2017年内地电影票房前20的电影(列表a)和电影票房数据(列表b),那么如何更加直观的展示该数据?
a = ["战狼2","速度与激情8","功夫瑜伽","西游伏妖篇","变形金刚5:最后的骑士","摔跤吧!爸爸","加勒比海盗5:死无对证",
"金刚:骷髅岛","极限特工:终极回归","生化危机6:终章","乘风破浪","神偷奶爸3","智取威虎山","大闹天竺",
"金刚狼3:殊死一战","蜘蛛侠:英雄归来","悟空传","银河护卫队2","情圣","新木乃伊",]
b=[56.01,26.94,17.53,16.49,15.45,12.96,11.8,11.61,11.28,11.12,10.49,10.3,8.75,7.55,7.32,6.99,6.88,6.86,6.58,6.23]
单位:亿
数据来源: http://58921.com/alltime/2017
from matplotlib import pyplot as plt
my_font = {
'family': 'SimHei',
'weight':'bold',
'size':'16'
}
file_name = ["战狼2","速度与激情8","功夫瑜伽","西游伏妖篇","变形金刚5:最后的骑士","摔跤吧!爸爸","加勒比海盗5:死无对证",
"金刚:骷髅岛","极限特工:终极回归","生化危机6:终章","乘风破浪","神偷奶爸3","智取威虎山","大闹天竺",
"金刚狼3:殊死一战","蜘蛛侠:英雄归来","悟空传","银河护卫队2","情圣","新木乃伊",]
account = [56.01,26.94,17.53,16.49,15.45,12.96,11.8,11.61,11.28,11.12,10.49,
10.3,8.75,7.55,7.32,6.99,6.88,6.86,6.58,6.23]
# plt.figure(figsize=(20,15),dpi=80)
# # 用序号开始绘图,在xticks中用format对应其电影名称
# plt.bar(range(len(file_name)), account, width=0.3)
# # 设置图片大小
# plt.xticks(range(len(file_name)), file_name, rotation=90, fontproperties="SimHei")
# 对于竖放的条形图看着不舒服,可以绘制横向的条形图plt.barh()可查看其源码进行参数设置
plt.figure(figsize=(20,15), dpi=80)
plt.barh(range(len(file_name)), account, height=0.3)
# 横向条形图的height表示条形图的柱子高度
plt.yticks(range(len(file_name)), file_name, fontproperties="SimHei")
plt.xlabel("票房:亿", fontproperties="SimHei")
plt.ylabel("电影名称", fontproperties="SimHei")
plt.title("2017年电影票房Top20", fontproperties="SimHei")
# 绘制网格
plt.grid()
plt.show()
plt.savefig("./file.png")
例2:多次条形图(电影三天内的票房统计)
假设你知道了列表a中电影分别在2017-09-14(b_14), 2017-09-15(b_15), 2017-09-16(b_16)三天的票房,为了展示列表中电影本身的票房以及同其他电影的数据对比情况,应该如何更加直观的呈现该数据?
a = ["猩球崛起3:终极之战","敦刻尔克","蜘蛛侠:英雄归来","战狼2"]
b_16 = [15746,312,4497,319]
b_15 = [12357,156,2045,168]
b_14 = [2358,399,2358,362]
数据来源: http://www.cbooo.cn/movieday
from matplotlib import pyplot as plt
my_font = {
'family': 'SimHei',
'weight':'bold',
'size':'16'
}
a = ["猩球崛起3:终极之战","敦刻尔克","蜘蛛侠:英雄归来","战狼2"]
b_16 = [15746,312,4497,319]
b_15 = [12357,156,2045,168]
b_14 = [2358,399,2358,362]
bar_width = 0.2 # 条形柱的宽度
x_14 = list(range(len(a)))
x_15 = [i+bar_width for i in x_14]
x_16 = [i+bar_width*2 for i in x_14]
plt.figure(figsize=(20,8), dpi=80)
plt.bar(list(range(len(a))), b_14, width=0.2, label ="9月14日票房数据", color="orange") # width需要和上面X轴的排列紧密连接
plt.bar(x_15, b_15, width=0.2, label ="9月15日票房数据", color="cyan")
plt.bar(x_16, b_16, width=0.2, label ="9月16日票房数据", color="blue")
# 设置x轴的标注
plt.xticks(x_16, a, fontproperties="SimHei")
# 设置图例,图例字体格式参数必须使用字典
plt.legend(prop = my_font)
plt.show()
plt.savefig("./files.png")
散点图
- 不同条件(维度)之间的内在关联关系
- 观察数据的离散聚合程度
例1:气温随时间变化的规律
a = [11,17,16,11,12,11,12,6,6,7,8,9,12,15,14,17,18,21,16,17,20,14,15,15,15,19,21,22,22,22,23]
b = [26,26,28,19,21,17,16,19,18,20,20,19,22,23,17,20,21,20,22,15,11,15,5,13,17,10,11,13,12,13,6]
数据来源: http://lishi.tianqi.com/beijing/index.html
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = {
'family': 'SimHei',
'weight':'bold',
'size':'16'
}
y_3 = [11,17,16,11,12,11,12,6,6,7,8,9,12,15,14,17,18,21,16,17,20,14,15,15,15,19,21,22,22,22,23]
y_10 = [26,26,28,19,21,17,16,19,18,20,20,19,22,23,17,20,21,20,22,15,11,15,5,13,17,10,11,13,12,13,6]
# 输出y轴坐标数目,x轴也必须与之相对应
print(len(y_3))
x = range(0,31)
# 散点图,会存在重合的点,故沿着x轴排列,二者中间留些空隙
x_3 = range(1,32)
x_10 = range(51,82)
plt.figure(figsize=(20, 8), dpi=80)
plt.scatter(x_3, y_3, color="orange", label = "三月份")
plt.scatter(x_10, y_10, color="cyan", label = "十月份")
# 调整x轴刻度
_x = list(x_3) + list(x_10)
# 三月份坐标设置
_xtick_labels = ["三月{}日".format(i) for i in x_3]
# 十月份坐标设置
_xtick_labels += ["十月{}日".format(i-50) for i in x_10]
# 设置坐标轴步长,字体旋转,中文字体设置
plt.xticks(_x[::3], _xtick_labels[::3], rotation = 45, fontproperties="SimHei")
# 添加描述信息
plt.xlabel("日期",fontproperties="SimHei")
plt.ylabel("摄氏度",fontproperties="SimHei")
plt.title("三、十月份北京地区气温情况",fontproperties="SimHei")
# 添加图例,前提是绘图时写入了label,而且此处字体格式的写入必须是字典格式
# 内部参数的设置,Ctrl B 查看源码,比如:
# loc的位置:
# 'upper right' : 1,
# 'upper left' : 2,
# 'lower left' : 3,
# 'lower right' : 4,
plt.legend(loc=2,prop=my_font)
plt.show()
