
目录
numpy读取数据
import numpy as np
us_file_path = "./US_video_data_numbers.csv"
uk_file_path = "./GB_video_data_numbers.csv"
# 点击,喜欢,不喜欢,评论数量
t1 = np.loadtxt(us_file_path, delimiter=',', dtype="int", unpack=False)
# unpack=True,则将转置读入,unpack默认为False;文件内数据之间是逗号分隔的,所以delimiter=','
t2 = np.loadtxt(uk_file_path, delimiter=',', dtype="int")
print(t1)
print(t2)
# 取行 print(t2[2])
# 取连续多行 print(t2[2:]
# 取不连续的多行 print(t2[2,5,8])
# 取列 print(t2[1,:]) ==第2行(所有列)
# 逗号前面取行,逗号后面取列。冒号表示所有
# 取连续的多行多列 print(t2[2:,:]) # 第3行及之后的所有行列
# 取第一列 print(t2[:,1])
# 取连续的多列 print(t2[:,2:]) # 第3列之后的所有多行多列
# 取不连续的多列 print(t2[:,[0,2]) # 第1列和第3列
# 取第三行、第四列 print(t2[2,3])
# 取多行、多列 取d第3行-第5行,第2列到第4列,交叉点的位置
b = t2[2:5,1:4] # 区间总是左闭右开的
print(b)
# 取多个不相邻的点,(0,0)(2,1)(4,3)
c = t2[[0,2,4],[0,1,3]]
print(c)
# numpy中的布尔类型
a < 10
# 将数组内部<10者替换为0,>10者替换为10,引入三元运算符
np.where(a<10, 0, 10)
# 将数组内部<10者替换为0,>20者替换为20,引入clip(裁剪)
np.clip(10, 20)
# 10-20中间部分者不做替换,数组内部nan不做替换,因为nan是浮点类型,对数组操作之前先进行astype转换为float类型
数组拼接合成并标记
import numpy as np
us_file_path = "./US_video_data_numbers.csv"
uk_file_path = "./GB_video_data_numbers.csv"
# 加载国家信息
# 点击,喜欢,不喜欢,评论数量
us_data = np.loadtxt(us_file_path, delimiter=',', dtype="int", unpack=False)
# unpack=True,则将转置读入,unpack默认为False;文件内数据之间是逗号分隔的,所以delimiter=','
uk_data = np.loadtxt(uk_file_path, delimiter=',', dtype="int")
# 添加国家信息
zero_data = np.zeros((us_data.shape[0],1)).astype(int)
# shape[0]表示行、shape[1]表示列。zeros((m,n))m行n列的零元素集合
one_data = np.ones((uk_data.shape[0],1)).astype(int)
# 拼接两组信息,注意!!!两组数据类型的匹配
us_data = np.hstack((us_data, zero_data))# 美国标记为0
uk_data = np.hstack((uk_data, one_data)) # 英国标记为1
# 竖直拼接两组数据
final_data = np.vstack((us_data, uk_data))
print(final_data)
numpy+散点图
# 希望了解英国的youtube中视频的评论数和喜欢数的关系,应该如何绘制改图
# 要查看二者之间的关系,使用散点图为最佳
import numpy as np
from matplotlib import pyplot as plt
us_file_path = "./US_video_data_numbers.csv"
uk_file_path = "./GB_video_data_numbers.csv"
# 点击,喜欢,不喜欢,评论数量
t1 = np.loadtxt(us_file_path, delimiter=',', dtype="int", unpack=False)
# unpack=True,则将转置读入,unpack默认为False;文件内数据之间是逗号分隔的,所以delimiter=','
t2 = np.loadtxt(uk_file_path, delimiter=',', dtype="int")
# 选择喜欢数比50W小的部分
# 发现评论数量集中分布在5000以内,那么可以将区域外部数据进行剪枝
t2 = t2[t2[:, 1] <= 500000]
# 这个操作不能在t_uk_comments中进行,因为评论和喜欢要一一对应,只能对原始数据进行操作
# print(t1)
t_uk_comments = t2[:,-1] # 评论
t_uk_likes = t2[:,1] # 喜欢
# print(t_us_comments)
# 先设置大小、再画图、再显示
plt.figure(figsize=(20,8), dpi=80)
plt.scatter(t_uk_comments, t_uk_likes)
plt.xlabel("评论数量", fontproperties = "SimHei")
plt.ylabel("喜爱数量", fontproperties = "SimHei")
plt.savefig("./likes_comments_scatter.png")
plt.show()
替换numpy中nan元素且不改变整体数组的中值
import numpy as np
def fill_ndarray(t1):
for i in range(t1.shape[1]): # t1按列shape[1]遍历
temp_col = t1[:,i] # 当前该列所有元素
nan_num = np.count_nonzero(temp_col != temp_col) # nan!=nan隐含性质
if nan_num!=0: # 数组中存在nan元素
temp_not_nan_col = temp_col[temp_col==temp_col] # 当前列中,不为nan的元素位置array
temp_col[np.isnan(temp_col)] = temp_not_nan_col.mean()
# 计算不含nan的元素集合的中值,赋值给该列中nan元素所在位置
# t1[:,i] = temp_col
# 上面改行其实不用,因为数组之间的 = 操作后,二者是相互影响的
return t1
if __name__ =="__main__":
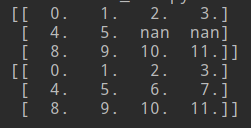
t1 = np.arange(12).reshape((3, 4)).astype("float")
# nan为float类型,故先要进行类型转换
t1[1, 2:] = np.nan # 第2行中,第3列往后全置为nan
print(t1)
print(fill_ndarray(t1))
numpy+直方图
# 英国和美国各自youtube1000的数据结合之前的matplotlib绘制出各自的评论数量的直方图
import numpy as np
from matplotlib import pyplot as plt
us_file_path = "./US_video_data_numbers.csv"
uk_file_path = "./GB_video_data_numbers.csv"
# 点击,喜欢,不喜欢,评论数量
t1 = np.loadtxt(us_file_path, delimiter=',', dtype="int", unpack=False)
# unpack=True,则将转置读入,unpack默认为False;文件内数据之间是逗号分隔的,所以delimiter=','
t2 = np.loadtxt(uk_file_path, delimiter=',', dtype="int")
print(t1)
t_us_comments = t1[:,-1]
print(t_us_comments)
# 发现评论数量集中分布在5000以内,那么可以将区域外部数据进行剪枝
t_us_comments[t_us_comments>5000] = 0
print(t_us_comments.max(),t_us_comments.min()) # 最大值-最小值 刚好被组距整除最好
d = 50 # 组距
bin_nums =(t_us_comments.max()-t_us_comments.min())//d
# 先设置大小、再画图、再显示
plt.figure(figsize=(20,8), dpi=80)
plt.hist(t_us_comments, bin_nums, normed=True)
plt.xlabel("评论数量")
plt.ylabel("频率分布情况")
plt.savefig("./comments.png")
plt.show()
# print(t2)
