一:numpy相关的操作
1数组的创建:numpy.array( [ ["元素1","元素2"],["元素1","元素2"],["元素1","元素2"] ] )

生成数组 arange、zeros、ones

bool类型:

(1)矢量化运算:相同大小的数组键间的运算应用在元素上
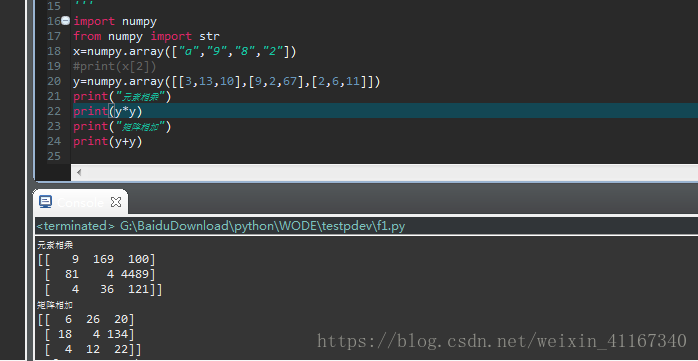
(2)矢量与标量运算:将标量“广播”到各个元素

2数组的排序:sort方法
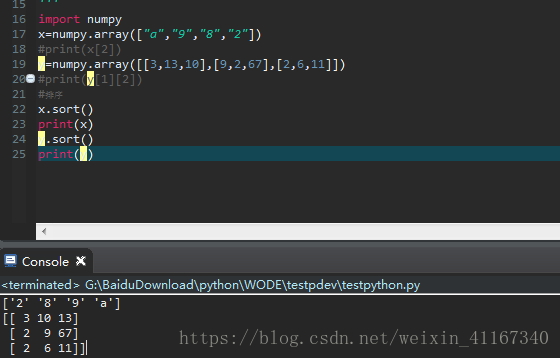
3取最大值与最小值:y1=y.max() y2=y.min()

4一维数组的切片与索引:按照下标切开,取某个片段之间的元素 数组[ 起始下标 : 最终下标+1]
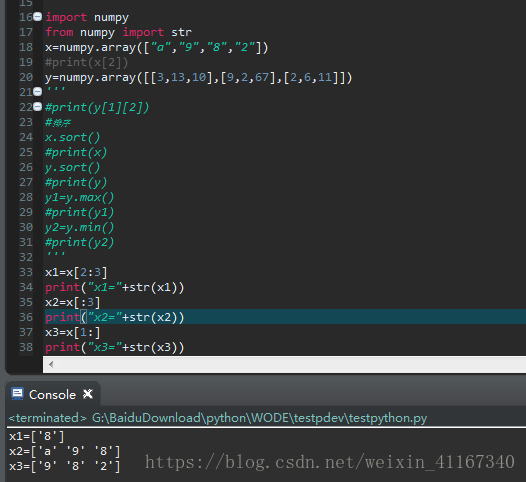

5.多维数组的索引与切片:
arr[ r1 : r2, c1 : c2] : r1,r2代表行的切片。c1,c2代表列的切片。
arr[1,1]等价于arr[1][1]


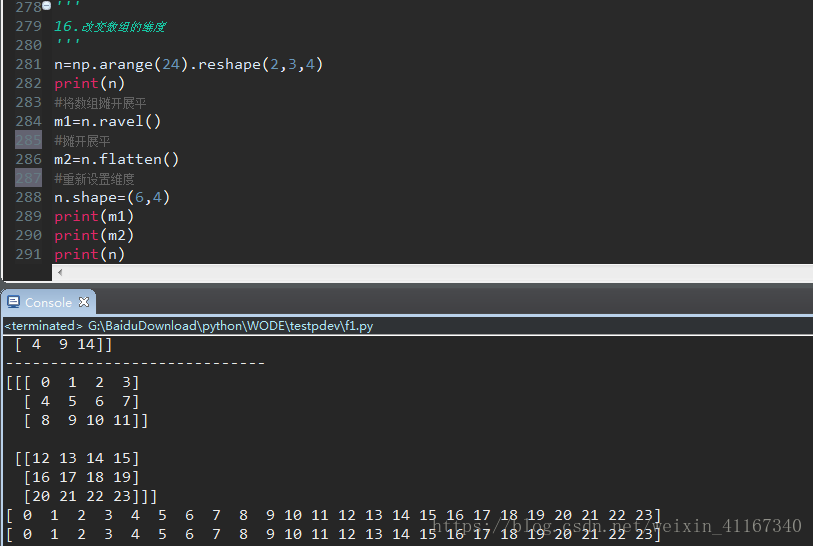
改变数组的维度:先摊开展平,再设置维度。

6.条件索引:布尔值多维数组,arr[condition],condition可以是多个条件组合,注意多个条件组合要用& | 而不是and or
(1)单个条件: 首先 随机生成3行3列的[0,1)之间的浮点数。

(2)多个条件:
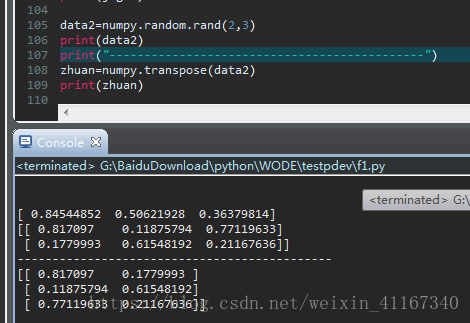
7:转置:transpose 高维数组转置要指定维度编号(0,1,2.....)
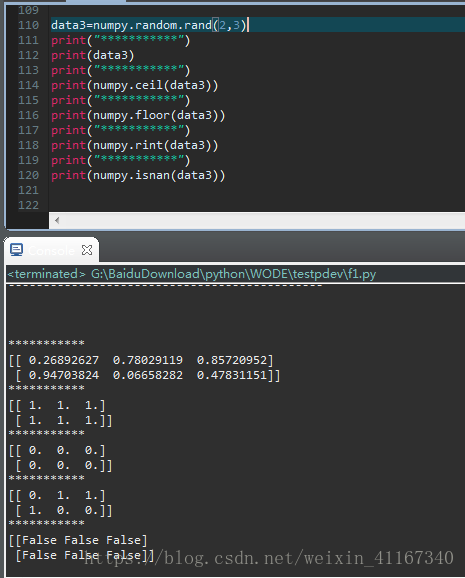
8:通用函数:元素级运算。
ceil 向上最接近的整数
floor 向下最接近的整数
rint 四舍五入
isnan 判断元素是否为NaN(not a number)
mutiply 元素相乘
divide 元素相除
9:矢量版本的三元表达式:
numpy.where(condition,x,y) : x if condition else y
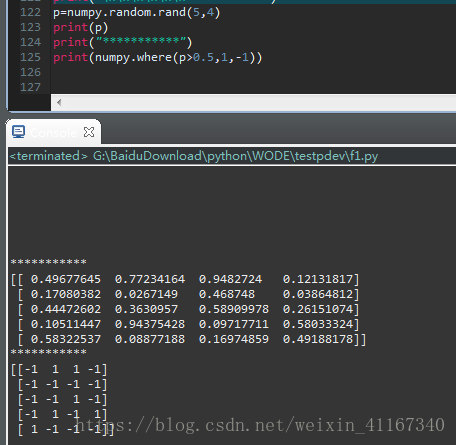
10:常用的统计方法:注意多维的话要指定统计的维度,否则默认全部维度上做统计。(axis=0 按列,axis=1,按行)
mean:
sum:
max:
min:
std:
var:
argmax:
argmin:
cumsum:
cumprod:
all:全部满足条件
any:至少满足条件
unique:找到唯一的值并返回排序结果
二:pandas相关操作
1 Series:指的是某一串数字,有顺序的。一行或者一列 。默认index索引(0开始)

2 DataFrame :数据类似于表格
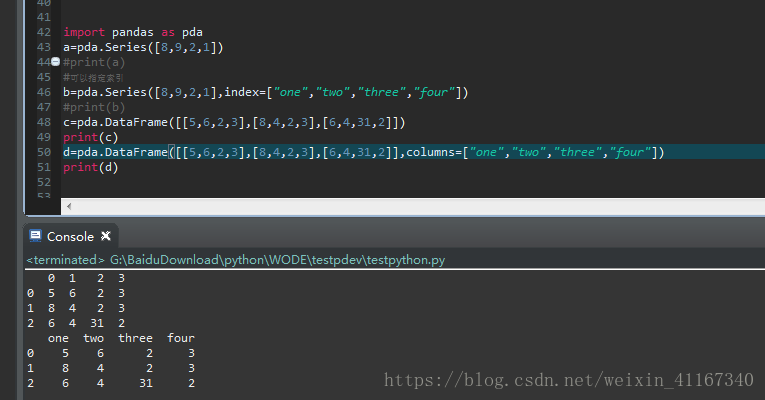
3字典的方式创建数据
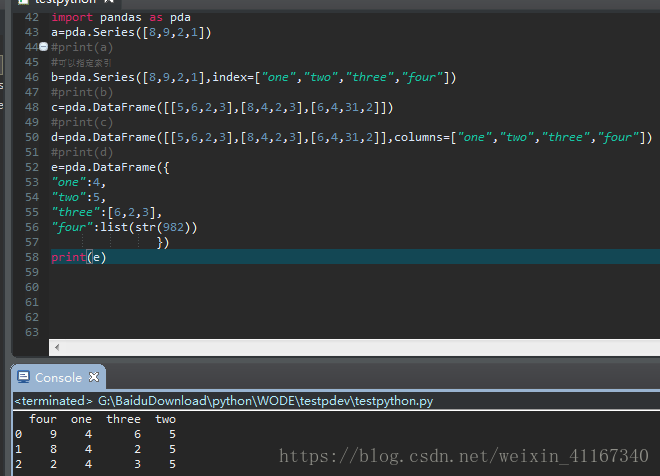
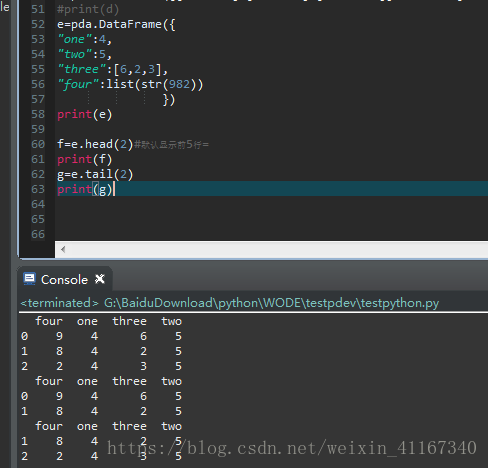
4头部数据 e.head(),默认取前5行
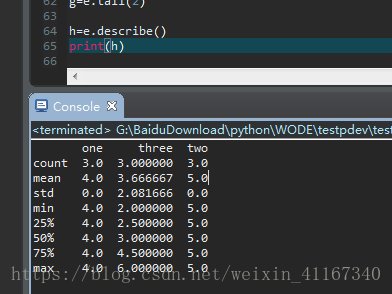
5尾部数据 e.tail(),默认取后5行
6 e.describe()按列统计。
count这列的个数,mean平均数,std标准差,min这一列中的最小值,max这一列的最大值。
%对应的数字代表每一列的分位数。
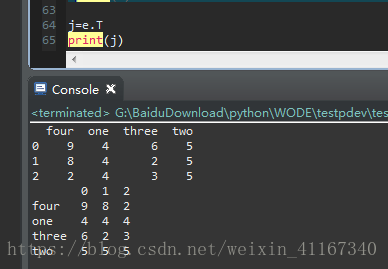
7 数据的转置(行变列,列变行)e.T