Hadoop课程结课设计时老师让做一个评价预测,完成后将核心的要点记录下来,方便后续同学可以参考
hadoop-word-predict
基于hadoop的评价预测系统
实验的题目如下
编写java程序,使其能够实现基于上传至hdfs的“学号_上传文件.txt”数据集训练情感分类器的目的。在训练的过程中,应过滤包含非中文字符或全部由非中文字符构成的词语。保存模型文件至“学号_模型.txt”文件中。格式要求:
类标_词语1\t计数
类标_词语2\t计数
类标_词语3\t计数
……
类标1\t计数
类标2\t计数
基于训练得到的模型参数(即Nc和Ncw,其中,c表示情感标签类别,c∈{好评,差评},w∈V,V是“学号_上传文件.data”数据集包含的中文词典集合),对“test.txt”数据集中的各条记录进行“情感标签”判别。判别结果输出至“学号_预测结果.txt”文件中。“学号_预测结果.txt”文件中的每行是行号及“test.txt”中预测的“情感标签”:格式要求:
1 情感标签
2 情感标签
3 情感标签
……
2000 情感标签
训练和预测用的数据格式如下
好评 几乎 凌晨 才 到 包头 包头 没有 什么 特别 好 酒店 每次 来 就是 住 这家 所以 没有 忒 多 对比 感觉 行 下次 还是 得到 这里 来 住
好评 住 过 几次 东莞 酒店 海悦 地理位置 早餐 最棒 听说 朋友 说 请来 厨师 来头 呵呵 冲 这个 去
好评 酒店设施 比较 不错 就是 携程 价格 酒店 前台 一样 没有 竞争力
好评 房间 不算 大 中规中矩 北方 服务 真的 不敢恭维 CHECK IN 后 没有 服务生 帮 你 拿 行李 到 房间 去 周围 酒店 没 啥 逛 自己 吃 早饭 可以 去 万豪 喜来登 之间 那条 路 永和 豆浆店 很 便宜
好评 通过 朋友 介绍 住 苏州 南林 饭店 一进 酒店 大堂 感觉 很 好 酒店 行李 员 前台 服务员 大堂 经理 很 热情 有种 宾至如归 感觉 房间 很 特色 背景 墙上 金色 字体 诗词 我 住 朝南 景观 房 感觉 真的 很 好 一 出门 就是 娱乐 酒吧 一条街 美食 一条街 出门 很 方便 下次 来 苏州 我 会 选择 南林 我 会 介绍 我 朋友 入住 南林 饭店
好评 西宁 住 过 几个 酒店 此 酒店 虽然 比起 内地 四星级 差 一些 但 西宁 算是 不错 价格 不 高 房间 里 东西 倒 干净 地毯 有点 脏 用 地 暖 感觉 比 空调 舒服 多 没有 噪音 安全 周围环境 尚可
好评 房间 算 整齐 宽敞 我 住 标准间 大床 房 只是 浴室 淋浴 笼头 不太好 出水 不 均匀 洗澡 不 舒服 服务 不错 到 酒店 早上 点 让 我 提前 入住 而且 结账 速度 比较 快 不 耽误时间 酒店 靠近 号 地铁 算 方便
内容说明
环境配置和文件上传这里就不做赘余的描述了,主要讲解下实现的思想
为了实现预测模型使用了两组mapperreducer
第一组:进行词频统计,得到每个词在对应评价下的数目,格式如下
类标_词语1\t计数
类标_词语2\t计数
类标_词语3\t计数
...
好评_几乎 \t 23
mapper实现:
将一行数据先以\t进行分割得到关键字行,再将关键字行以空格分割,分割后以<评价词_关键字,1>写入上下文,并将词性统计也写入上下文
//把value对应的行数据按照指定的间隔符拆分开
String[] words = value.toString().split("\t");
//word[0]是评价(好评或者差评)
//word[1]是评价的内容
//过滤一下有些评价后面没有关键字
if (words.length == 2){
String[] pjs = words[1].split(" ");
for (String pj : pjs) {
//如果含有非中文的就过滤掉
if (isAllChinese(pj)){
context.write(new Text(words[0] + "_" + pj), new IntWritable(1));
}
}
//统计好评差评数目
context.write(new Text("统计_"+words[0]), new IntWritable(1));
}
为了判断分词结果是否为纯中文,编写了一个方法做检验
/**
* 判断字符串是否全为中文
* @param str
* @return
*/
public boolean isAllChinese(String str) {
if (str == null) {
return false;
}
for (char c : str.toCharArray()) {
if (!isChinese(c)) {
return false;
}
}
return true;
}
/**
* 判断单个字符是否为中文
* @param c
* @return
*/
public Boolean isChinese(char c) {
return c >= 0x4E00 && c <= 0x9Fa5;
}
reducer实现
读取上下文,对第二个属性值进行累加,等到每个组合关键字的计数,再以<评价词_关键字,计数>写入上下文
/**
*
* map端 输出到reduce端,按相同的key分发到同一个reduce去执行
* (hello,<1,1,1>)
* (welcome,<1>)
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()){
IntWritable value = iterator.next();
count += value.get();
}
context.write(key,new IntWritable(count));
}
好评差评计数实现
mapper时判断是否为好评,如果为好评,写入一条<统计_好评,1>到上下文;如果为差评,写入一条<统计_差评,1>到上下文
注意:reducer时进行了自动排序,要把统计结果放最后就要加一个不同于前面数据的名
第二组:进行评价预测,得到预测的结果,格式如下
1 情感标签
2 情感标签
3 情感标签
4 好评
mapper实现
mapper主要完成预测数据的分词,预测时只需要后面的具体评价关键字组,所以以\t先分割出关键字行,再以空格分割出关键字组,将关键字以<行号,关键字>写入上下文
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
/**
* 将测试文件进行分解 分解为(行号,关键字)格式
*/
//把value对应的行数据按照指定的间隔符拆分开
String[] words = value.toString().split("\t");
//word[0]是评价(好评或者差评)
//word[1]是评价的内容
IntWritable lineCount = new IntWritable(PredictApp.lineCount++);
//过滤一下有些评价后面没有关键字
if (words.length == 2) {
String[] pjs = words[1].split(" ");
for (String pj : pjs) {
//如果含有非中文的就过滤掉
if (isAllChinese(pj)) {
context.write(lineCount, new Text(pj));
}
}
}
}
reducer实现
先用一个静态代码块加载训练出的模型到一个HashMap内,方便预测时使用
static Map<String, Integer> wordMap = new HashMap<>();
static {
// 1.读取hdfs的文件 ==>HDFS API
Path input = new Path("/output_2017081119/part-r-00000");
try {
//获取hdfs文件系统
FileSystem fs = null;
fs = FileSystem.get(new URI("hdfs://192.168.199.200:8020"), new Configuration(), "hadoop");
RemoteIterator<LocatedFileStatus> iterator = fs.listFiles(input, false);//不递归的获取文件
while (iterator.hasNext()) {
LocatedFileStatus file = iterator.next();
FSDataInputStream in = fs.open(file.getPath());
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
String line = "";
while ((line = reader.readLine()) != null) {//读取到的行不为空
String[] split = line.split("\\s+");
if (split.length == 2) {
wordMap.put(split[0], Integer.parseInt(split[1]));
}
}
reader.close();
in.close();
}
fs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
写一个函数判断一行对应的关键字集合预测是否是好评,
/**
* 预测评价可能的结果
*
* @param values
* @return
*/
public Boolean checkIsGood(Iterable<Text> values) {
Integer goodNum = 0;
Double good_factor = 0.0;
Double bad_factor = 0.0;
//遍历获得每个关键字
Iterator<Text> iterator = values.iterator();
while (iterator.hasNext()) {
Text value = iterator.next();
//todo 一个方法,可以获取关键字对应好评行和差评行的计数
Integer good = wordMap.get("好评_" + value);
Integer bad = wordMap.get("差评_" + value);
//todo 通过计数计算各个词的好评权重
/**
* 倍数计数法
* 如果为null就设为1
* 如果好评>差评,计算好评/差评向上取整
* 如果好评<差评,计算-差评/好评向上取整
* 如果好评=差评,计算值为0
* 结果876:1124
*/
good = good == null ? 1 : good + 1;
bad = bad == null ? 1 : bad + 1;
if (good != bad) {
//差评比较多,影响因素大多也是差评,所以降低了差评的权重,向下取整
Double v = (good > bad) ? Math.ceil(good*1.0 / bad) : -Math.floor(bad*1.0 / good);
goodNum += v.intValue();
}
}
return goodNum >= 0;
}
然后在上下文写入<行号,评价词>,因为测试数据前1000条为好评,后1000条为差评,这里把正确率的判断写死了,然后把正确率和好评差评数目写入上下文
@Override
protected void reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
Boolean isGood = checkIsGood(values);
context.write(key, new Text(isGood ? "好评" : "差评"));
//好评和差评的计数
if (isGood) ++goodCount;
else ++badCount;
//判断正确的计数
if (Integer.parseInt(key.toString()) <= 1000
&& isGood
|| Integer.parseInt(key.toString()) > 1000
&& Integer.parseInt(key.toString()) <= 2000
&& !isGood) {
correctCount++;
}
//最后一条的后面输出一个计数
if (key.toString().equals("2000")) {
context.write(new IntWritable(2017081119), new Text("好评统计:" + goodCount));
context.write(new IntWritable(2017081119), new Text("差评统计:" + badCount));
context.write(new IntWritable(2017081119), new Text("预测正确率:" + correctCount / 2000.0));
}
}
好评判断算法实现
Integer good = wordMap.get("好评_" + value);
Integer bad = wordMap.get("差评_" + value);
good = good == null ? 1 : good + 1;
bad = bad == null ? 1 : bad + 1;
if (good != bad) {
Double v = (good > bad) ? Math.ceil(good /bad) : -Math.ceil(bad / good);
goodNum += v.intValue();
}
遍历关键字集合,对每个关键字进行拼接后从训练模型集合里面获取个数,如果为空设为1,如果不为空设为n+1
goodNum代表一行词语的好评系数,如果 >= 0 就为好评,反之为差评
如果一个词的好评和差评计数一样,好评系数为0
如果一个词好评数目 > 差评数目,用好评数 / 差评数 向上取整作为好评系数
如果一个词好评数目 < 差评数目,用差评数 / 好评数 向上取整再去相反数作为好评系数
将每个词的好评系数进行累加就得到一行词的评价
好评差评统计和正确率计算
在reducer中添加三个计数器,分别计算好评数,差评数,统计正确数
在一行数据评价完成后,判断是好评就好评计数加一,反正差评计数加一
根据预测文件的格式,可以发现前1000条为好评,后1000条为差评,将预测结果与之判断,如果相同,正确计数加一
最后将三个参数在第2000行上下文写出去之后以<学号,描述_个数(比例)>的格式写入上下文
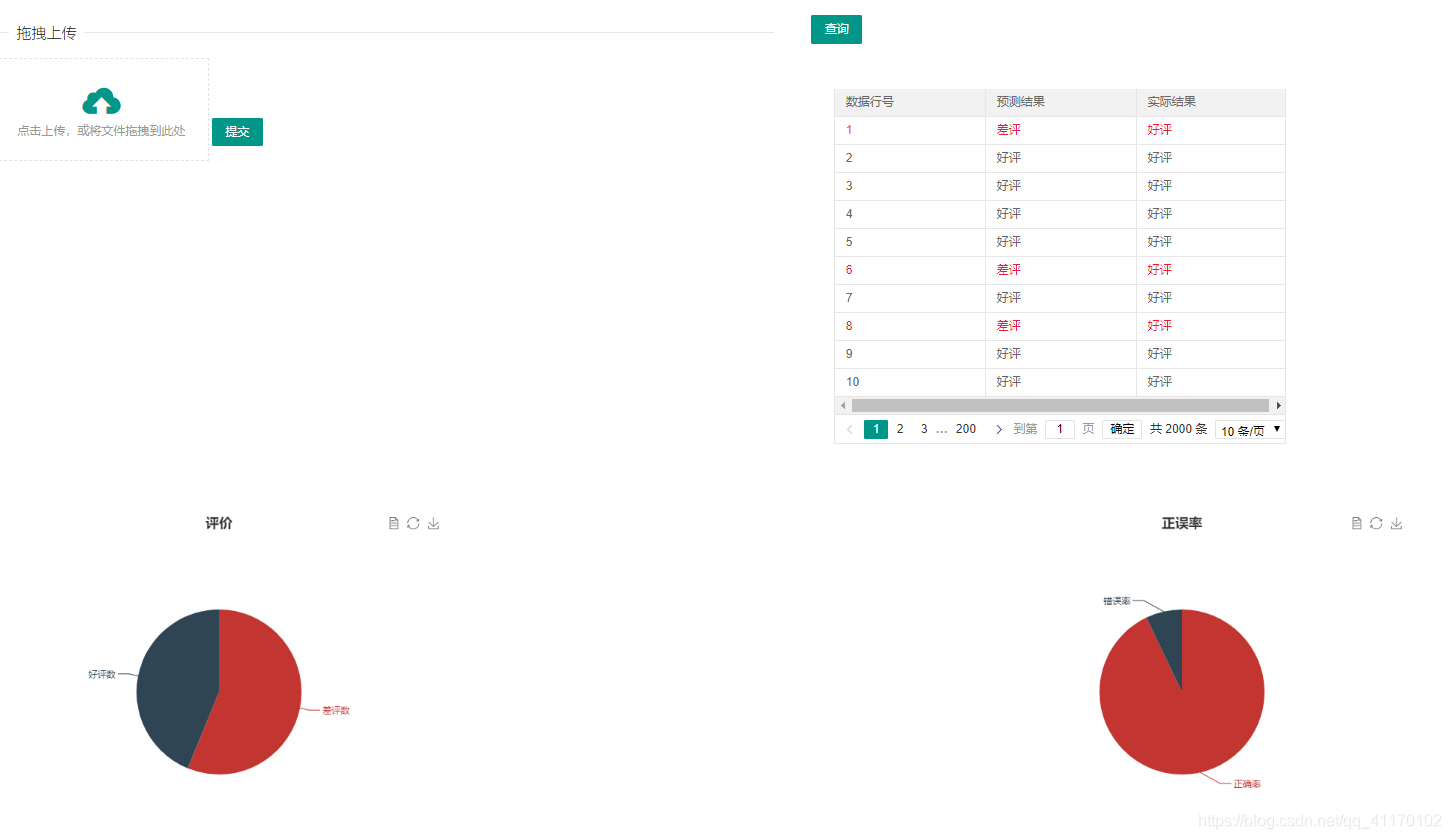
页面实现
按照实验要求需要实现一个预测文件上传界面和预测结果和数据展示界面
这里采用了SpringBoot快速搭建了一个前后端分离的后台,然后实现了两个restful风格的接口进行数据交互,具体实现如下:
文件上传
文件上传采用了分步上传,首先将文件以MultipartFile上传到系统部署平台(或文件服务器)下的一个文件夹,并获取到文件在部署平台下的路径,然后将文件上传到hdfs
@PostMapping(value = "/upLoadFile")
public CommonreturnType upLoadFile(@RequestParam(value = "file") MultipartFile file) throws Exception {
/**
* 将上传到代码平台的代码上传到HDFS
*/
//将文件从浏览器端上传到服务器端
String fileUrl = uploadFile(file);
System.out.println(fileUrl);
//将文件从服务器端传输到hadoop
fileUpLoadToHdfs(fileUrl);
//进行预测生成文件
// new PredictApp();
return CommonreturnType.create(200);
}
/**
* 将文件上传到HDFS
*
* @param filePath
* @throws URISyntaxException
* @throws IOException
* @throws InterruptedException
*/
private void fileUpLoadToHdfs(String filePath) throws URISyntaxException, IOException, InterruptedException {
Configuration configuration = new Configuration();
// 设置副本数为1
configuration.set("dfs.replication", "1");
/**
* 参数1:hdfs的uri
* 参数2:客户端指定的配置参数
* 参数3:客户端的身份,就是操作用户名
*/
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.199.200:8020"), configuration, "hadoop");
Path src = new Path(filePath);
Path dst = new Path("/predict_input_2017081119/test.txt");
fileSystem.copyFromLocalFile(src, dst);
configuration = null;
fileSystem = null;
}
/**
* 文件上传工具类
* 将文件上传到部署平台
*
* @param file
* @throws Exception
*/
private String uploadFile(MultipartFile file) {
String fileName = file.getOriginalFilename();
//文件上传到本项目所在平台的某个路径下
String filePath = "H:/WorkSpace/intellijWorkspace/hadoop-word-predict/upload/";
try {
File targetFile = new File(filePath);
if (!targetFile.exists()) {
targetFile.mkdirs();
}
FileOutputStream out = new FileOutputStream(filePath + fileName);
out.write(file.getBytes());
out.flush();
out.close();
} catch (Exception e) {
e.printStackTrace();
return null;
}
return filePath + fileName;
}
数据展示接口
首先编写了json返回对象
private Double goodCount;//好评数
private Double badCount;//差评数
private Double correct;//正确率
private List<PredictResult> predictResults;//评价词组
PredictResult:
private String lineNum;//行号
private String pResult;//预测结果
private String tResult;//实际结果
数据展示中,预测结果以分页表格进行显示,评价统计和正确率调用echart.js以饼图进行实现
大概的思路就分享到这里,完整的代码见我的github
