评估分类模型

1. TP, FP, TN, FN
1)True Positives,TP:预测为正样本,实际也为正样本的特征数
2)False Positives,FP:预测为正样本,实际为负样本的特征数
3)True Negatives,TN:预测为负样本,实际也为负样本的特征数
4)False Negatives,FN:预测为负样本,实际为正样本的特征数

里面绿色的半圆就是TP(True Positives), 红色的半圆就是FP(False Positives), 左边的灰色长方形(不包括绿色半圆),就是FN(False Negatives)。右边的 浅灰色长方形(不包括红色半圆),就是TN(True Negatives)。这个绿色和红色组成的圆内代表我们分类得到模型结果认为是正值的样本。
1.绝对误差与相对误差
2.平均绝对误差(MAE :Mean Absolute Error )
平均绝对误差是绝对误差的平均值
平均绝对误差能更好地反映预测值误差的实际情况.
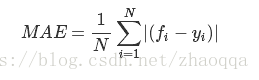
3.均方误差(MSE: Mean Squared Error)
均方误差是指参数估计值与参数真值之差平方的期望值;
MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度

4.均方误差根(RMSE Root Mean Squared Error)
均方误差:均方根误差是均方误差的算术平方根

5.平均绝对百分误差(MAPE Mean Absolute Percentage Error)
一般认为小于10时,预测精度较高
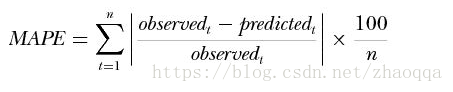
6.Kappa统计
Kappa统计是比较两个或多个观测者对同一事物,或观测者对同一事物的两次或多次观测结果是否一致,以由于机遇造成的一致性和实际观测的一致性之间的差别大小作为评价基础的统计指标。
Kappa取值在[-1,1]之间,其值得大小均有不同的意义。
Kappa = +1 说明两次判断的结果完全一致
Kappa = -1 说明两次判断的结果完全不一致
Kappa = 0 说明两次判断的结果是给机遇造成的
Kappa < 0 说明一致结果比机遇造成的还差,很不一致,无意义
Kappa > 0 说明有意义,越大,说明一致性越好
Kappa >= 0.75 说明已经取得相当满意的一致程度
Kappa < 0.4 说明一致程度不够
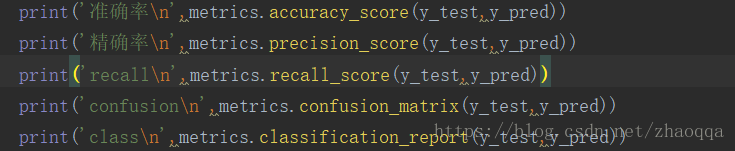
7.识别准确度(Accuracy)
accuracy = (TP+TN)/(TP+FN+FP+FN) 被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好
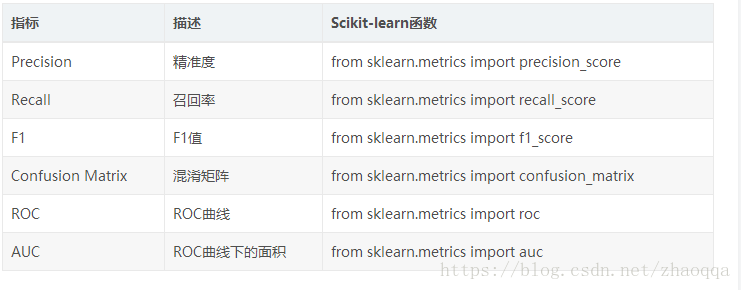
8.识别精确率(Precision)

9.召回率,反馈率(Recall)
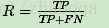
f1-score

可以看到,recall 体现了分类模型对正样本的识别能力,recall 越高,说明模型对正样本的识别能力越强,precision 体现了模型对负样本的区分能力,precision越高,说明模型对负样本的区分能力越强。F1-score 是两者的综合。F1-score 越高,说明分类模型越稳健。
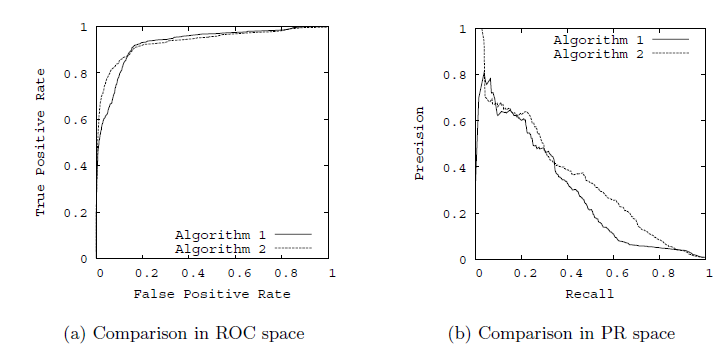
10.ROC曲线(Receiver Operating Characteristic)和PR曲线
以TPR为y轴,以FPR为x轴,我们就直接得到了RoC曲线。从FPR和TPR的定义可以理解,TPR越高,FPR越小,我们的模型和算法就越高效。也就是画出来的RoC曲线越靠近左上越好(也就是说越接近正方形越好)。如下图左图所示。从几何的角度讲,RoC曲线下方的面积越大越大,则模型越优。所以有时候我们用RoC曲线下的面积,即AUC(Area Under Curve)值来作为算法和模型好坏的标准。
以精确率为y轴,以召回率为x轴,我们就得到了PR曲线。仍然从精确率和召回率的定义可以理解,精确率越高,召回率越高,我们的模型和算法就越高效。也就是画出来的PR曲线越靠近右上越好。
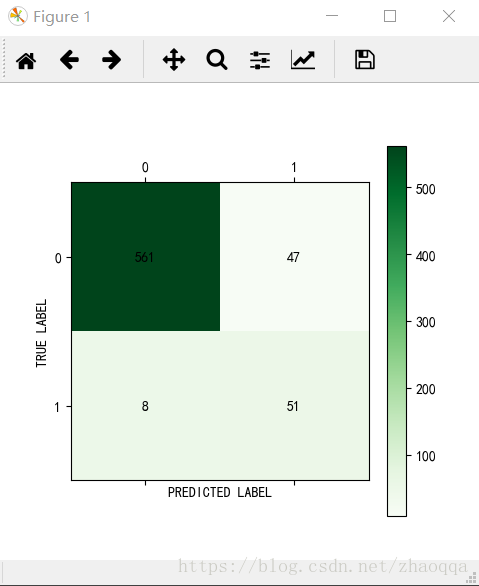
11混淆矩阵(Confusion Matrix)
针对预测值和真实值之间的关系,我们可以将样本分为四个部分,分别是:
真正例(True Positive,TP):预测值和真实值都为1
假正例(False Positive,FP):预测值为1,真实值为0
真负例(True Negative,TN):预测值与真实值都为0
假负例(False Negative,FN):预测值为0,真实值为1
将这四种值用矩阵表示,就是混淆矩阵
混淆矩阵的可视化