YOLOv3相比YOLOv2,主要有以下几个方面的改变:使用Darknet-53作为基础网络(提取图像特征);对象分类用逻辑回归取代softmax;借鉴FPN,利用多尺度特征图进行目标检测。
1.网络结构
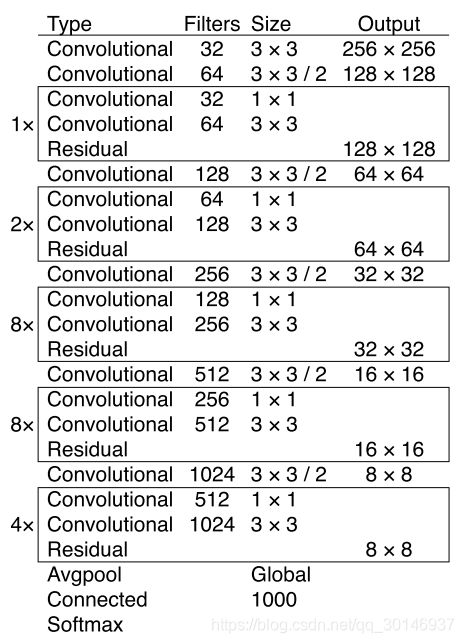
YOLOv3采用了Darknet-53作为基础网络,有53个卷积层。它借鉴了ResNet中的残差块的设计,在某些层之间添加“跳层连接”(shortcut connection)。更详细的网络结构剖析可以看这篇大牛!
2.用逻辑回归取代softmax
YOLOv3在分类时没有用softmax分类器,而是用独立的logistic分类器。softmax只能处理相互独立的类别,也就是bounding box如果属于一种类别,那么它就不可能属于第二种类别。但是对于Open Image这种数据集,有许多重叠的类别标记,比如“女人”和“人”。因此用softmax处理就不太合适了。用logistic分类器来预测每个类别得分,并设置一个阈值,选取大于阈值的类别作为bounding box的真实类别。
3.用多尺度特征图进行检测
这部分参考大牛
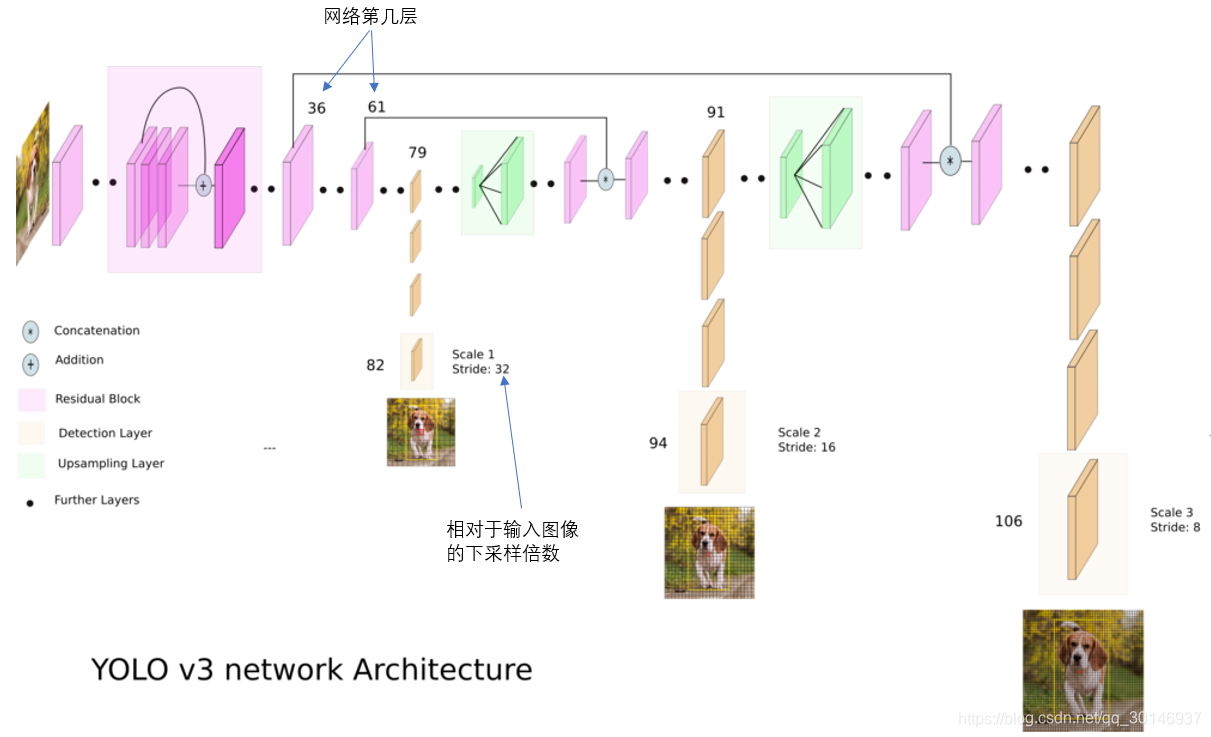
YOLO2曾采用passthrough结构来检测细粒度特征,在YOLO3更进一步采用了3个不同尺度的特征图来进行目标检测。
结合上图看,卷积网络在79层后,经过下方几个黄色的卷积层得到一种尺度的检测结果。相比输入图像,这里用于检测的特征图有32倍的下采样。比如输入是416 × 416的话,这里的特征图就是13 × 13了。由于下采样倍数高,这里特征图的感受野比较大,因此适合检测图像中尺寸比较大的目标。
为了实现细粒度的检测,第79层的特征图又开始作上采样(从79层往右开始上采样卷积),然后与第61层特征图融合(Concatenation),这样得到第91层较细粒度的特征图,同样经过几个卷积层后得到相对输入图像16倍下采样的特征图。它具有中等尺度的感受野,适合检测中等尺度的目标。
最后,第91层特征图再次上采样,并与第36层特征图融合(Concatenation),最后得到相对输入图像8倍下采样的特征图。它的感受野最小,适合检测小尺寸的目标。
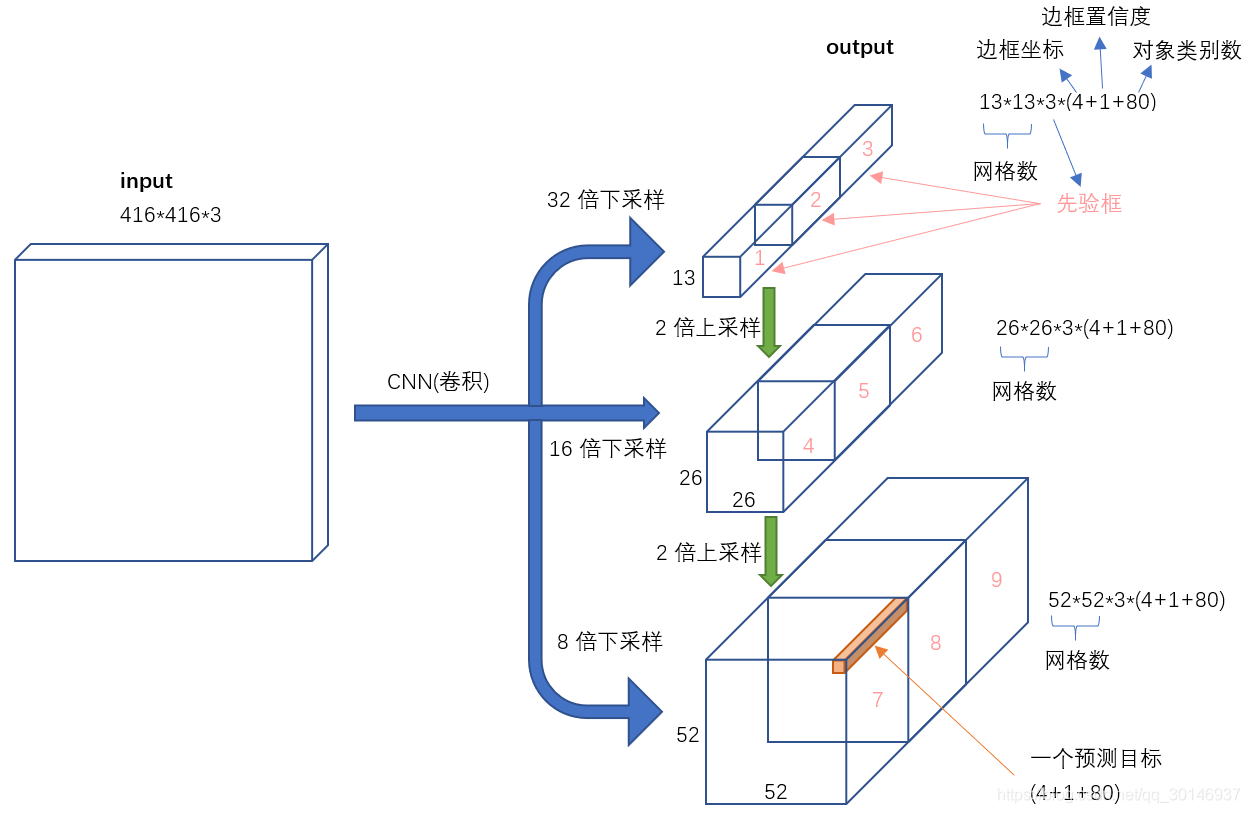
上图是YOLOv3输入到输出的映射。不考虑神经网络结构细节的话,总的来说,对于一个输入图像,YOLO3将其映射到3个尺度的输出张量,代表图像各个位置存在各种目标的概率。
我们看一下YOLO3共进行了多少个预测。对于一个416 × 416的输入图像,在每个尺度的特征图的每个网格设置3个先验框,总共有 13 × 13 × 3 + 26 × 26 × 3 + 52 × 52 × 3 = 10647 个预测。每一个预测是一个(4+1+80)=85维向量,这个85维向量包含边框坐标(4个数值),边框置信度(1个数值),目标类别的概率(对于COCO数据集,有80种对象)。
4.anchor大小的设置
YOLOv3和YOLOv2一样,用dimension cluster的方法为每种下采样尺度设定三种anchor,总共有9中尺度的anchor。在COCO数据集上,给最小的特征图(13 × 13)应用较大的anchor:(116 × 90),(156 × 198),(373 × 326),适合检测较大的目标。给中等的特征图(26 × 26)应用中等的anchor:(30×61),(62×45),(59× 119),检测中等的目标。给最大的特征图(52 × 52)应用较小的anchor:(10×13),(16×30),(33×23),检测较小的目标。
