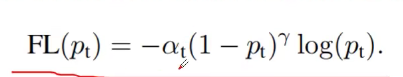提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
本篇博客是记录学习yolov3的笔记,如有错误,还请不吝赐教!
提示:以下是本篇文章正文内容,下面案例可供参考
注:本文参考大神的文章和视频
文章:yolov3理论
视频:yolo系列理论合集
一、Yolov1(one-stage)
You Only Look Once : Unified,Real-Time Object Detection
1.1 论文思想
1)将一幅图像分成 s s s* s s s个网络(grid cell),如果某个object的中心落在这个网格中,则这个网格就负责预测该目标。
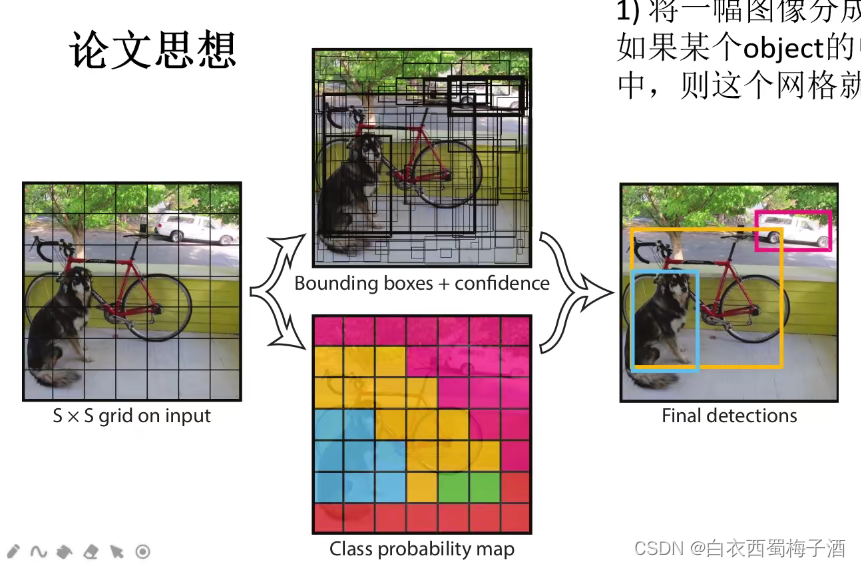
2) 每个网格需要预测B个bounding box,每个bounding box 除了要预测位置之外,还要附带预测一个confidence值。每个网络还要预测C个类别的分数。
其中 x,y,w,h 都是相对于grid cell 而言的相对信息。
confidence 即预测的目标和其真实目标的交并比。
pr(object) * IOU(Ground Truth and Predict)
其中pr(object)=0或1(网格中是否有目标)
在测试时,将conditional class * confidence predictions
Pr(Class i|object) * Pr(Object)*IOU(truth and pred)=Pr(class)*Iou(truth and pred)
即 最后给出的预测概率包含了目标的类别概率和预测的边界框与真实边界框的重合程度。
整体的网络结构:

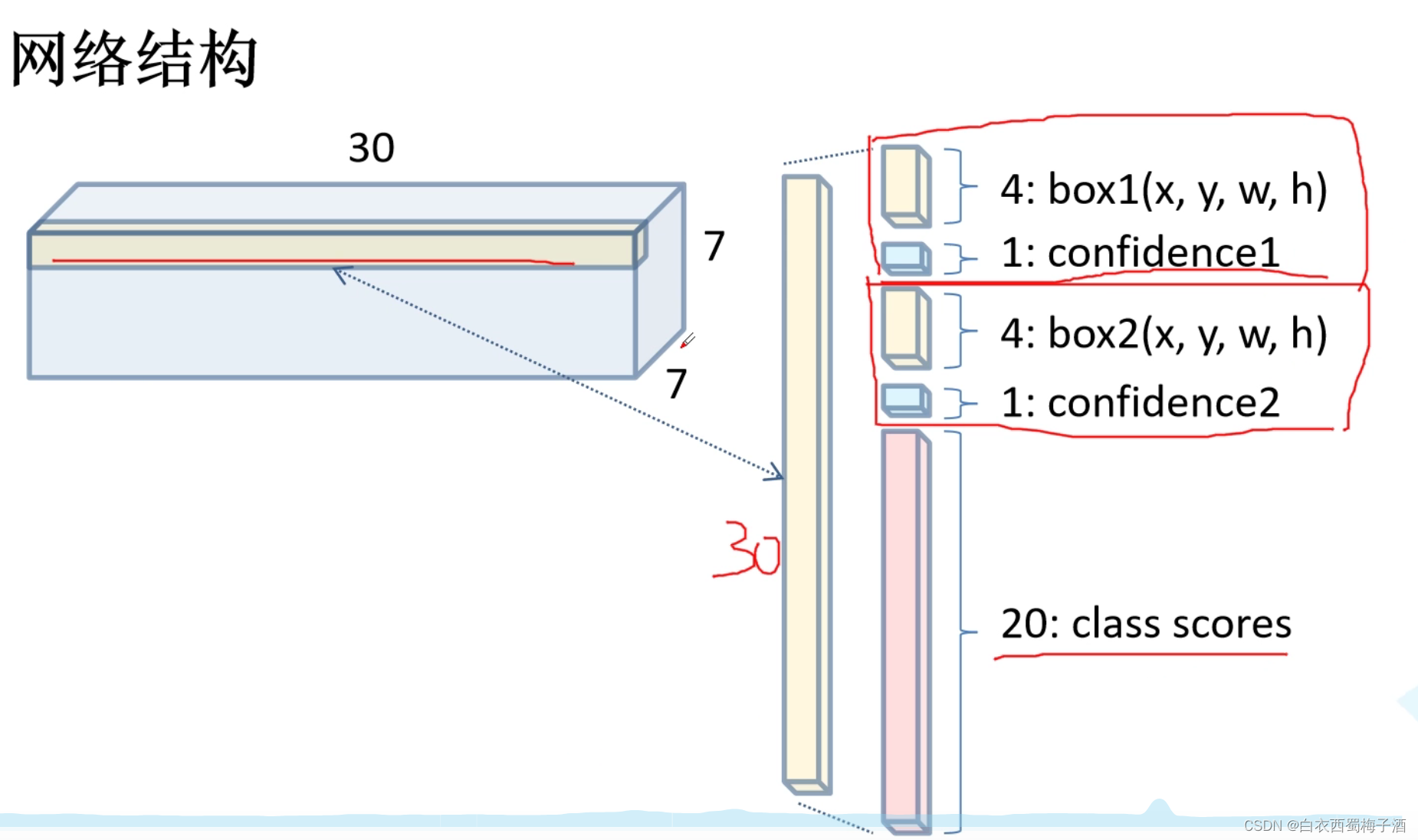
损失函数:

Bounding box损失:对于宽度和高度使用的是根号,应为如果直接使用w和h,那么对于不同大小的边界框他的预测的实际效果是不同的。
比如下图:

confidence 损失:包括正样本和负样本两项损失。
1.2 存在的问题
1)对于群体性的小目标检测效果很差,因为yolov1中在每个cell中预测两个bounding box,且这两个bounding box只预测同一类别。
2)当目标出现新的尺寸或配置时,效果也很差。
3)yolov1模型的主要错误原因在于定位不准确。
二、Yolov2
2017 CVPR
YOLO 9000 :Better,Faster, Stronger
2.1 Yolov2中的各种尝试 (Better 章节)
1)Batch Normalization
减少了正则化的处理,同时提高了训练的收敛,相比于之前,提升了2%mAP,同时可以去除Dropout层。
2)High Resolution Classifier
使用更好分辨率的分类器,提升了4%mAP。
3)Convolutional With Anchor Boxes
使用anchor+坐标偏移的方式能够简化问题,同时让网络易于学习。
通过实验发现,采用Anchor对于mAP会有一个较小的下降,但是召回率Recall会有较大的提升。召回率的增加意味着模型有更大的提升空间。
4)Dimension Clusters
采用k-means聚类的方法来获取 priors。
(基于训练集中所有边界框聚类的方式去获得对应的 priors(anchor))
5)Direct Location prediction
如果直接使用基于anchor的方式去训练会导致不稳定,特别是训练的前期。而其中的大部分不稳定因素都是预测 prior的中心坐标x,y 所导致的。
论文对prior的中心坐标进行了一个限制,使其落在grid cell区域内。
该做法加上(4)提升了5%mPA。
同样对于confidence值也使用sigmoid进行限制。
6)Fine-Grained Features
通过passthrough layer 将相对底层的特征图和高层的特征图进行融合,以提高检测小目标的效果。
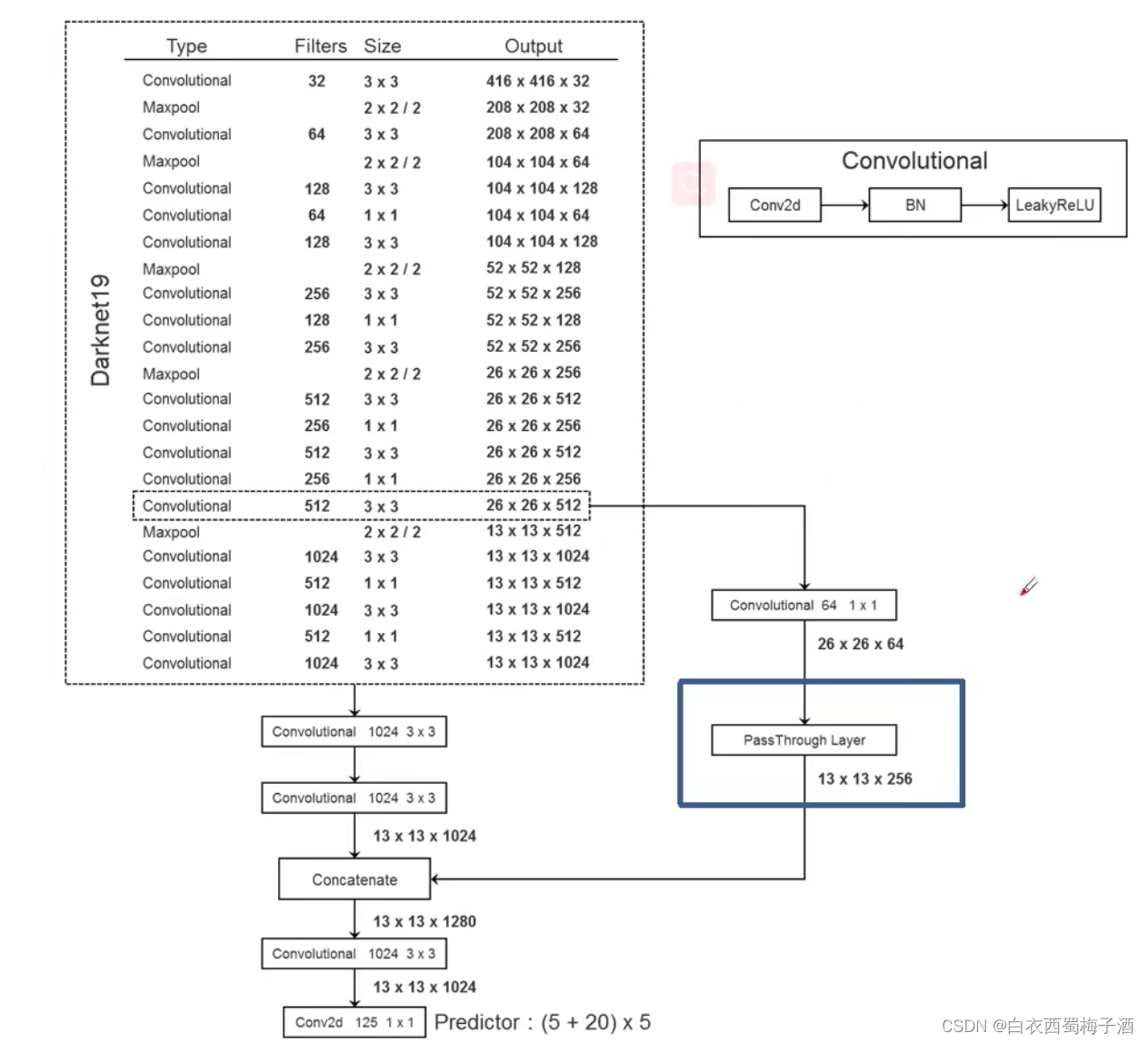
该方式提升了至少1%的表现。
7)Multi-Scale Training(多尺度训练)
每迭代十次,就将输入网络图像的大小进行随机选择。
2.2 BackBone :DarkNet-19
网络结构:
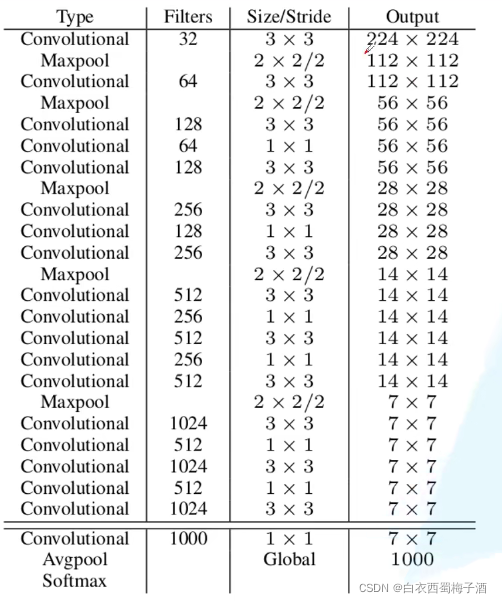
2.3 整体网络结构:
for voc use 5 boxes
三、Yolov3
2018 CVPR
Yolov3:An Incremental Improvement
3.1 BackBone:DarkNet-53
BackBone的具体模型如下图所示:
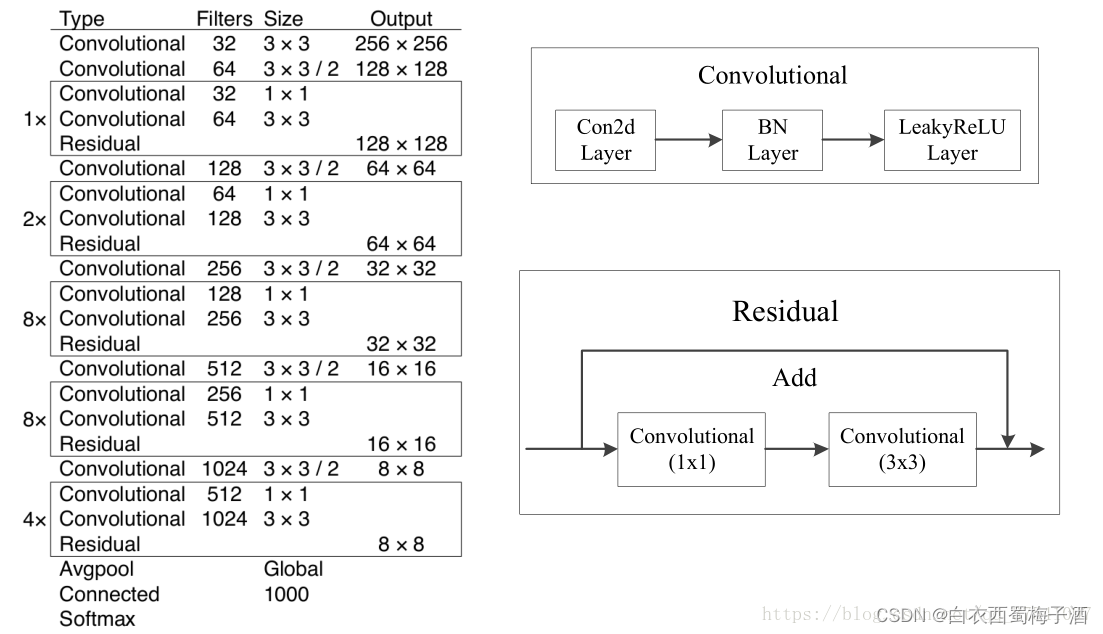
3.2 YOLOv3 模型结构
在论文中,作者提到利用三个特征层来进行边框的预测,其中具体的三层根据大神太阳花的小绿豆所写的博客为具体的以下三层(以输出尺寸为416x416为例 ,对应三个特征层大小分别为52,26,13):
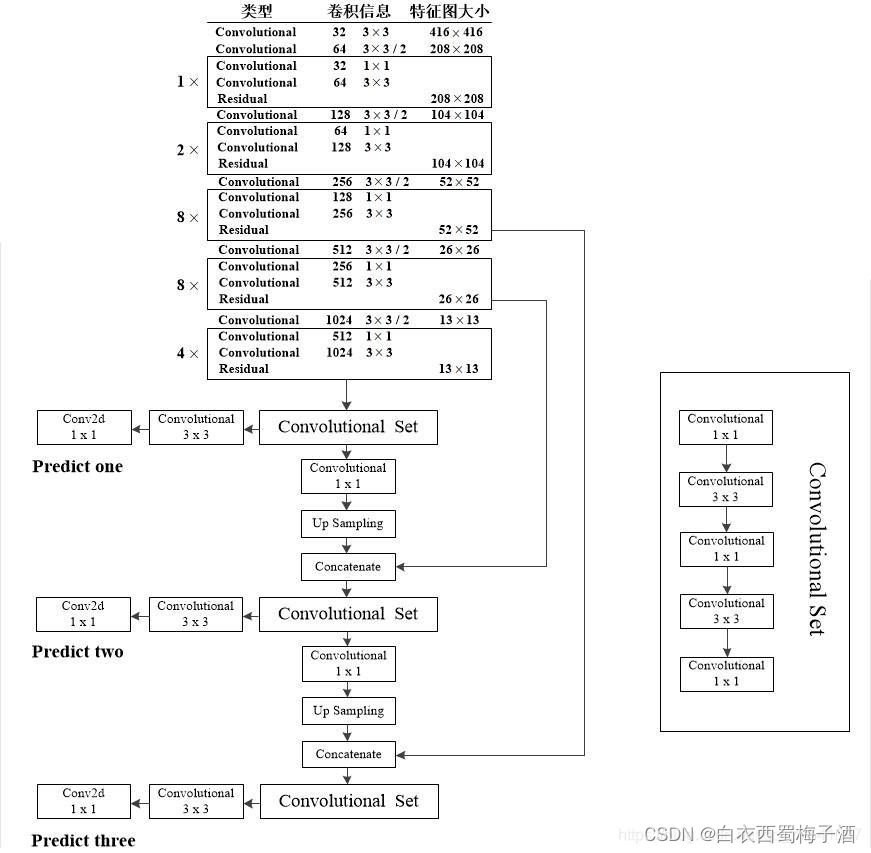
3.3 目标边界框预测
YOLOv3 在三个特征层中分别通过(4+1+c) × \times × k个大小为1$\times$1的卷积核进行卷积预测,k为预设边界框(bounding box prior)的个数(k默认取3),c为预测目标的类别数。
具体的边界框预测过程如下图:
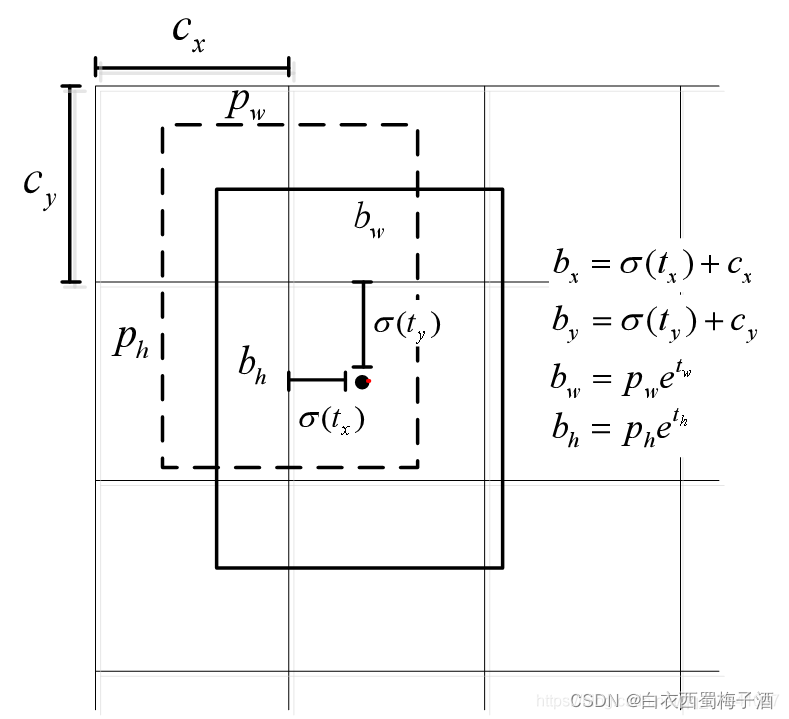
图中虚线矩形框为预设边界框,实线矩形框为通过网络预测的偏移量计算得到的预测边界框。其中(cx,cy)为预设边界框在特征图上的中心坐标,(pw,py)为预设边界框在特征图上的宽和高,(tx,ty,tw,th)分别为网络预测的边界框中心偏移量以及宽高缩放比(tw,ty),(bx,by,bw,bh)为最终预测的目标边界框,从预设边界框到最终预测边界框的转换过程如图右侧公式所示,其中函数是sigmoid函数其目的是将预测偏移量缩放到0到1之间(这样能够将预设边界框的中心坐标固定在一个cell当中,作者说这样能够加快网络收敛)。
而在每个特征图上预设的边界框尺寸都是作者通过coco数据集聚类得到的。

3.4 正负样本的匹配
对于每张图片,只给每个Ground Truth 分配一个priori 作为正样本,而其他和Ground Truth有重合,且iou大于阈值的预测priori则直接丢弃。
如果某个bounding box prior 没有对应的Ground Truth,那么它没有coordinate loss,也没有 class prediction loss,只有
置信损失。
3.5 损失计算

3.5.1 置信度损失

3.5.2 类别损失

3.5.3 定位损失

四、YOLOv3spp(ultralytics)
4.1 Mosaic 图像增强
做法:将多张图片拼接在一起。
优点:
1)增加数据的多样性
2)增加目标个数
3)BN能一次性统计多张图片的参数
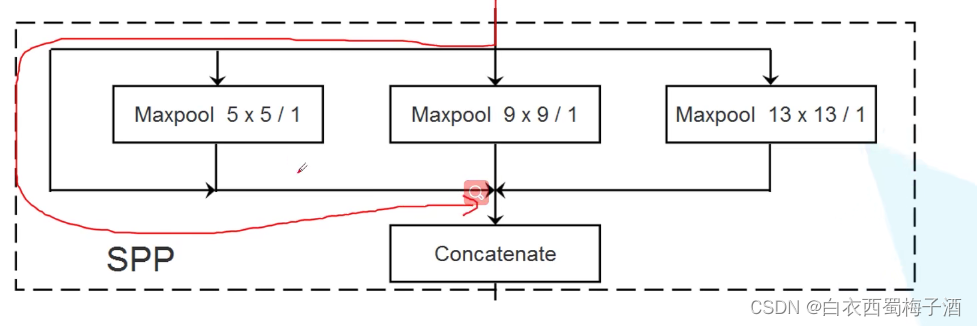
4.2 SPP模块
与SPPNet中的SPP结构不同。
实现了不同尺度的特征融合。(可以在每个特征layer前都使用spp模块,不过并不是必须的。)
4.3 CIoU Loss
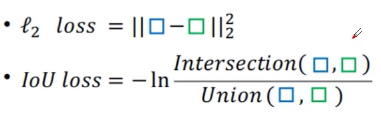
1.IoU Loss
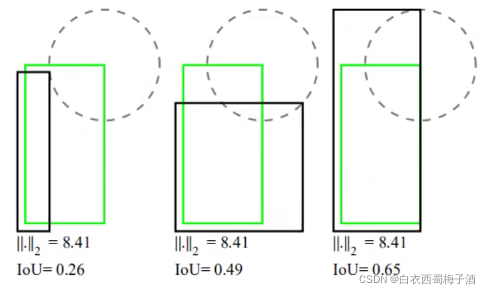
由上图可以发现 l2 损失不能很好的表现预测的效果好坏,而IoU损失可以做到这一点。
优点:
1)能够更好的反应重合程度
2)具有尺度不变性
缺点:
1)当不想交时,loss为0
2.GIoU Loss(Generalized IoU)
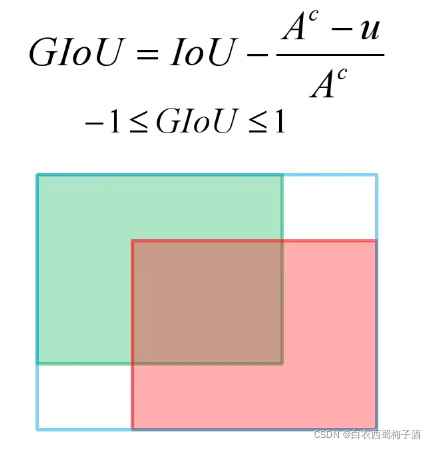
GIoU Loss:
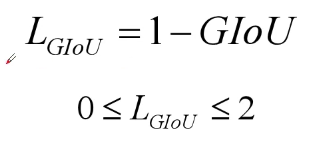
此时,当predict bounding box 与Ground Truth 没有重叠时,也有相应的loss值,可以进行反向传播。
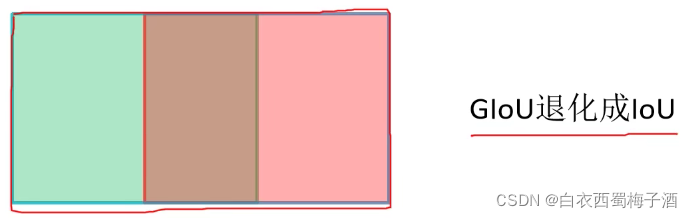
缺点:
当出现一下情况时,会退化为IoU Loss
3 DIoU Loss
IoU Loss 和 GIoU Loss缺点:
1.收敛速度缓慢
2.回归不准确
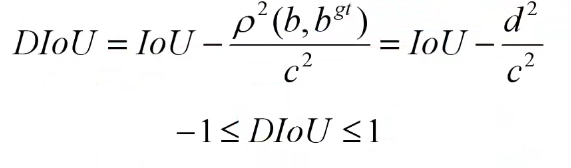
其中p ^2 (b,bgt) 为两个边界框的中心坐标的欧式距离
c^2 为最小外接矩形的对角线长度。

4 CIoU Loss
一个优秀的回归定位损失应该考虑到三种几何参数。
重叠面积,中心点距离,长宽比。

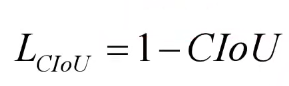
4.4 Focal Loss
主要针对One-stage 目标检测模型
一张图像中能够匹配到目标的候选框个数一般只有十几或者几十个,而没匹配到的候选框大概有10^4 - 10 ^5个。
而在这些未匹配到目标的候选框中大部分都是简单易分的负样本(对训练网络起不到什么作用,但由于数量太多会淹没掉少量但有助于训练的样本)
对于一般而言,我们使用binary log entropy loss
其中一个通用的方法去解决类别平衡的问题是去添加一个weight a (0,1)。
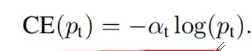
但是上述的a平衡了正负样本的主要性,但是它无法去区分易分样本和难分样本。
于是作者又修改了损失函数,这个函数能够降低易分样本的权重,因此我们能够更多的聚焦于难分的样本。
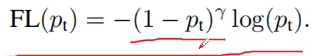
其中1-pt ^y 能够降低易分样本的损失贡献。