机器学习分类
- 监督学习:分类,回归;
- 无监督学习:维度约简,聚类
- 强化学习
数据集
- 训练集:用来训练模型算法,通过设置分类器参数,训练分类模型。
- 验证集:训练集训练出的多个模型对验证集数据进行预测,并记录模型准确率。选出效果最佳的模型所对应的参数,即用来调整模型参数。(非必需)
- 测试集:用来测试模型的性能和分类能力。
监督学习
从给定的训练数据集中学习出一个函数,当输入新数据时,可以根据这个函数预测结果。
核心是分类和回归
- 分类:输出是离散型变量,是一种定性输出。
- 回归:输出是连续型变量,是一种定量输出。
无监督学习
聚类和维度约简
- 输入数据没有标签,样本数据类别未知,需要根据样本间的相似性对样本集进行划分使类内差距最小化,类间差距最大化。
- 基于概率密度函数估计的直接方法
- 基于样本间相似性度量的聚类方法
强化学习
又称为再励学习、评价学习或增强学习
- 用于描述和解决智能体在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
- 机器学习的范式和方法论之一
强化学习不要求预先给定任何数据,而是通过接收环境对动作的奖励(反馈)获得学习信息并更新模型参数。
机器学习性能度量
误差
模型输出与真值的偏离程度,通常定义一个损失函数来衡量误差的大小。
在训练集上的产生误差称为经验误差或者训练误差——经验误差的大小反应了模型在训练数据上拟合效果的好坏
模型在未知样本上的误差称为泛化误差,通常将测试误差作为泛化误差的近似值——泛化误差用于衡量训练好的模型对未知数据的预测能力
过拟合与欠拟合

过拟合:模型在训练样本中表现得过于优越,导致在验证数据集以及测试数据集中表现不佳。
欠拟合:模型在训练和预测时表现得都不好
常见评估方法:
-
留出法
已有数据集分为互斥的两部分;保证数据分布一致;测试集比例保持在1/3~1/5。 -
交叉验证法

将数据集分成互斥的K份,训练过程中每一次随机抽取一组数据为测试集 -
自助法
数据D中包含m个样本,对数据集D进行m次有放回采样,采样到的数据构成数据集D1,将D1作为训练集,未出现在D1中的数据作为测试集。
样本不出现在D1中的概率为

适用于小数据集;不会减小训练集规模;改变了数据分布,易引起估计偏差。
混淆矩阵(误差矩阵)
主要用于比较分类结果和实例的真实信息
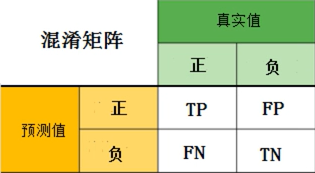
以二分类为例
真正(TP):模型预测为正的正样本
假正(FP):模型预测为正的负样本
假负(FN):模型预测为负的正样本
真负(TN):模型预测为负的负样本
准确率(accuray):正确预测的正反例数/总数,即(TP+TN)/(TP+FN+TN+FP)
精确率(precision):正确预测的正例数/预测正例总数,即TP/(TP+FP)
召回率(recall):正确预测的正例数/实际正例总数即TP/(TP+FN)
F-score:精确率和召回率的调和值
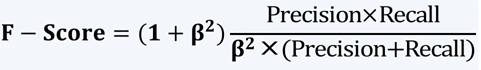
β=1时,该式称为F1-score或F1-measure,精确率和召回率都很重要,权重相同
β<1时,精确率更重要
β>1时,召回率更重要
F1-score:精确率和召回率的调和平均评估指标
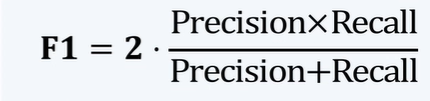
ROC曲线

根据分类结果计算得到ROC空间中相应的点,连接这些点形成ROC曲线
靠近左上角的ROC曲线所代表的分类器准确性最高
真正率(TPR):预测为正的正样本数/正样本实际数,TPR=TP/(TP+FN)
假正率(FPR):预测为正的负样本数/负样本实际数,FPR=FP/(FP+TN)
AUC:ROC曲线下的面积

AUC=1:100%完美识别正负类,不管阈值怎么设定都能得出完美预测。
0.5<AUC<1:优于随机预测。这个分类器妥善设定阈值的话,可能有预测价值。
AUC=0.5:跟随机猜测一样,模型无预测价值。
AUC<0.5:比随机预测还差,不存在AUC<0.5的情况
PR曲线(精确率对召回率的曲线)
在同一测试集,上面的曲线比下面的曲线好(绿线比红线好);
光滑曲线比不光滑曲线好;

PR曲线与ROC曲线
相同点:采用TPR,用AUC 来衡量分类器效果
不同点:ROC曲线使用了FPR,PR曲线使用了精确率
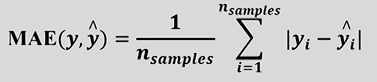
平均绝对误差
L1范数损失
平均平方误差
L2范数损失
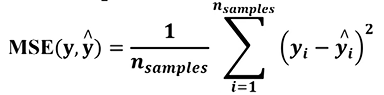
均方根误差
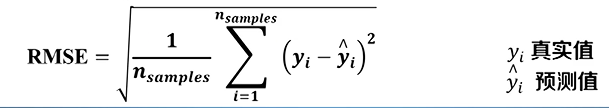
解释变异
给定数据中的变异能被数学模型所解释的部分通常用方差来量化变异
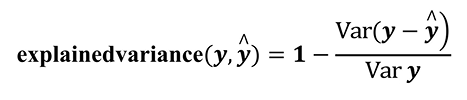
决定系数
回归关系已经解释的y值变异在其总变异中所占的比率
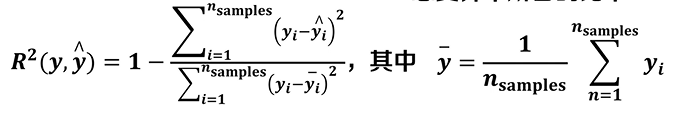
兰德指数
给定实际类别信息C,假设K是聚类结果,a表示C与K中都是同类别的元素对数,b表示在C与K中都是不同类别的元素对数。
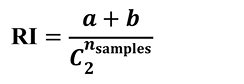
RI取值范围为[0,1]
调整兰德指数
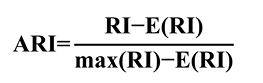
ARI取值范围[-1,1]
互信息
用来衡量两个数据分布的吻合程度。假设U与V是对N个样本标签的分布情况。
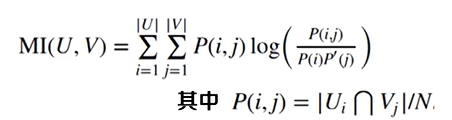
标准化后的互信息
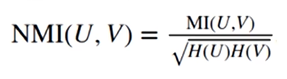
调整互信息
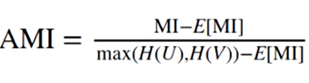
轮廓系数
对于单个样本,设a是与它同类别中其他样本的平均距离,b是与它距离最近不同类别中样本的平均距离

适用于实际类别信息未知的情况
