最近重新开始做深度学习相关的应用,但是很多概念记不清。因此,整理了一些指标,为了有空可以回顾,也欢迎补充。如有侵权,联系删除
1、准确率、召回率、F值
2、top-1 和 top-5准确率
3、mAp
4、MAC,Flops,SIMD
转载地址1:https://www.cnblogs.com/Zhi-Z/p/8728168.html
转载地址2:https://blog.csdn.net/v1_vivian/article/details/73251187
转载地址3:https://blog.csdn.net/qq_35608277/article/details/79070935
图表参考1:http://blog.sina.com.cn/s/blog_9db078090102whzw.html
转载地址4:https://blog.csdn.net/Lily_9/article/details/81448888
转载地址5:https://www.jianshu.com/p/ea5b99e609c5
一、(转载地址1:https://www.cnblogs.com/Zhi-Z/p/8728168.html)
业内目前常常采用的评价指标有准确率(Precision)、召回率(Recall)、F值(F-Measure)等,下图是不同机器学习算法的评价指标。下文讲对其中某些指标做简要介绍。
该部分主要针对二元分类器!
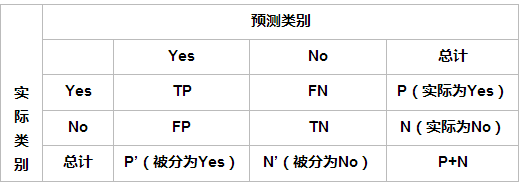
在介绍指标前必须先了解“混淆矩阵”:
混淆矩阵
True Positive(真正,TP):将正类预测为正类数
True Negative(真负,TN):将负类预测为负类数
False Positive(假正,FP):将负类预测为正类数误报 (Type I error)
False Negative(假负,FN):将正类预测为负类数→漏报 (Type II error)

1、准确率(Accuracy)
准确率(accuracy)计算公式为:
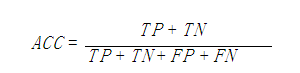
注:准确率是我们最常见的评价指标,而且很容易理解,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。
准确率确实是一个很好很直观的评价指标,但是有时候准确率高并不能代表一个算法就好。比如某个地区某天地震的预测,假设我们有一堆的特征作为地震分类的属性,类别只有两个:0:不发生地震、1:发生地震。一个不加思考的分类器,对每一个测试用例都将类别划分为0,那那么它就可能达到99%的准确率,但真的地震来临时,这个分类器毫无察觉,这个分类带来的损失是巨大的。为什么99%的准确率的分类器却不是我们想要的,因为这里数据分布不均衡,类别1的数据太少,完全错分类别1依然可以达到很高的准确率却忽视了我们关注的东西。再举个例子说明下。在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。比如在互联网广告里面,点击的数量是很少的,一般只有千分之几,如果用acc,即使全部预测成负类(不点击)acc也有 99% 以上,没有意义。因此,单纯靠准确率来评价一个算法模型是远远不够科学全面的。
2、错误率(Error rate)
错误率则与准确率相反,描述被分类器错分的比例,error rate = (FP+FN)/(TP+TN+FP+FN),对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate。
3、灵敏度(sensitive)
sensitive = TP/P,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力。
4、特效度(sensitive)
specificity = TN/N,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力。
5、精确率、精度(Precision)
精确率(precision)定义为:
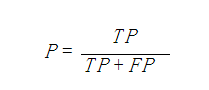
表示被分为正例的示例中实际为正例的比例。
6、召回率(recall)
召回率是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitive,可以看到召回率与灵敏度是一样的。
7、综合评价指标(F-Measure)
P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。
F-Measure是Precision和Recall加权调和平均: 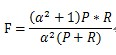
当参数α=1时,就是最常见的F1,也即 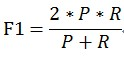
可知F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。
8、其他评价指标
计算速度:分类器训练和预测需要的时间;
鲁棒性:处理缺失值和异常值的能力;
可扩展性:处理大数据集的能力;
可解释性:分类器的预测标准的可理解性,像决策树产生的规则就是很容易理解的,而神经网络的一堆参数就不好理解,我们只好把它看成一个黑盒子。
下面来看一下ROC和PR曲线(以下内容为自己总结):
1、ROC曲线:
ROC(Receiver Operating Characteristic)曲线是以假正率(FP_rate)和假负率(TP_rate)为轴的曲线,ROC曲线下面的面积我们叫做AUC,如下图所示:
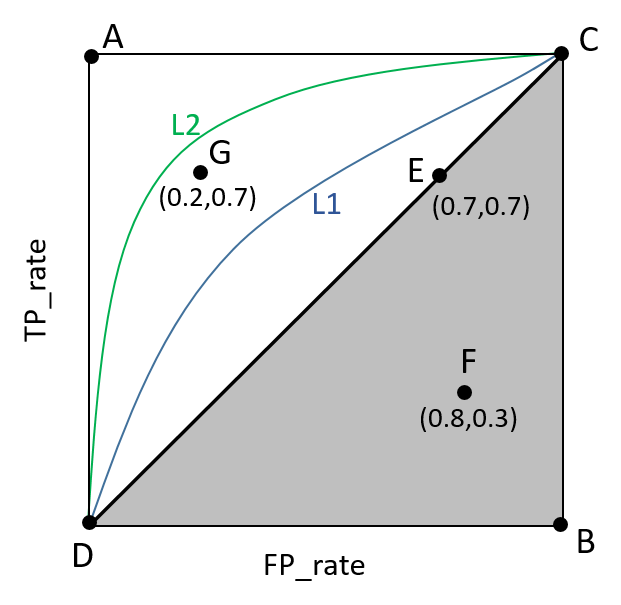
图片根据Paper:Learning from eImbalanced Data画出
其中: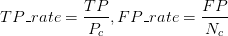
(1)曲线与FP_rate轴围成的面积(记作AUC)越大,说明性能越好,即图上L2曲线对应的性能优于曲线L1对应的性能。即:曲线越靠近A点(左上方)性能越好,曲线越靠近B点(右下方)曲线性能越差。
(2)A点是最完美的performance点,B处是性能最差点。
(3)位于C-D线上的点说明算法性能和random猜测是一样的–如C、D、E点。位于C-D之上(即曲线位于白色的三角形内)说明算法性能优于随机猜测–如G点,位于C-D之下(即曲线位于灰色的三角形内)说明算法性能差于随机猜测–如F点。
(4)虽然ROC曲线相比较于Precision和Recall等衡量指标更加合理,但是其在高不平衡数据条件下的的表现仍然过于理想,不能够很好的展示实际情况。
2、PR曲线:
即,PR(Precision-Recall)曲线。
举个例子(例子来自Paper:Learning from eImbalanced Data):
假设N_c>>P_c(即Negative的数量远远大于Positive的数量),若FP很大,即有很多N的sample被预测为P,因为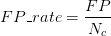
二、(转载地址2:https://blog.csdn.net/v1_vivian/article/details/73251187)
一些神经网络中会提到ImageNet Top-5 或者Top-1,这是一种图片检测准确率的标准,介绍这个之前,先介绍一下ImageNet。
【ImageNet】
ImageNet 项目是一个用于物体对象识别检索大型视觉数据库。截止2016年,ImageNet 已经对超过一千万个图像进行手动注释,标记图像的类别。在至少一百万张图像中还提供了边界框。
自2010年以来,ImageNet 举办一年一度的软件竞赛,叫做(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)。主要内容是通过算法程序实现正确分类和探测识别物体与场景,评价标准就是Top-5 错误率。
Top-5错误率
即对一个图片,如果概率前五中包含正确答案,即认为正确。
Top-1错误率
即对一个图片,如果概率最大的是正确答案,才认为正确。
三、(转载地址3:https://blog.csdn.net/qq_35608277/article/details/79070935)
MAP的计算步骤(eg.10类)
检测为例:
1.先把所有bounding box找出来 并加上confidence
2.然后每一类根据confidence从大到小排列
3.每个confidence算出其recall和precision得到每一类的ap曲线
4.取mean
具体来看
1. precision 和 recall 的计算:
精度precision的计算:是用 检测正确的数据个数/总的检测个数。
召回率recall的计算:是用 检测正确的数据个数/ground truth之中所有正数据个数。
ground true:参考标准\标准答案\真实值,设定的一个正确的基准(标签)
具体参照一
2. AP:average precision
一共20个图像,20行,第一列是图像index(索引), 第二列是检测confidence(置信), 第三列是ground truth(标签)。根据confidence从大到小排列。
圆圈内(true positives + false positives)是我们选出的元素,它对应于分类任务中我们取出的结果,比如对测试样本在训练好的car模型上分类,我们想得到top-5的结果。
在这个例子中,true positives就是指第4和第2张图片,false positives就是指第13,19,6张图片。方框内圆圈外的元素(false negatives和true negatives)是相对于方框内的元素而言,在这个例子中,是指confidence score排在top-5之外的元素,其中,false negatives是指第9,16,7,20张图片,true negatives是指第1,18,5,15,10,17,12,14,8,11,3张图片。
那么,这个例子中Precision=2/5=40%,意思是对于car这一类别,我们选定了5个样本,其中正确的有2个,即准确率为40%;Recall=2/6=30%,意思是在所有测试样本中,共有6个car,但是因为我们只召回了2个,所以召回率为30%。
实际多类别分类任务中,我们通常不满足只通过top-5来衡量一个模型的好坏,而是需要知道从top-1到top-N(N是所有测试样本个数,本文中为20)对应的precision和recall。显然随着我们选定的样本越来也多,recall一定会越来越高,而precision整体上会呈下降趋势。把recall当成横坐标,precision当成纵坐标,即可得到常用的precision-recall曲线。
3.AP的计算
假设这N个样本中有M个正例,那么我们会得到M个recall值(1/M, 2/M, …, M/M),对于每个recall值r,我们可以计算出对应(r’ > r)的最大precision,然后对这M个precision值取平均即得到最后的AP值。计算方法如下:
相应的Precision-Recall曲线(这条曲线是单调递减的)
AP衡量的是学出来的模型在每个类别上的好坏,
mAP的计算
mAP衡量的是学出的模型在所有类别上的好坏,得到AP后
就是取所有AP的平均值。
四、(转载地址4:https://blog.csdn.net/Lily_9/article/details/81448888)
一、FLOPS
FLOPS(Float Operations Per Second):每秒浮点运算量,是衡量吞吐率的一个单位,通过折算到具体的浮点操作数量上。
所谓,吞吐率——就如同水管,每秒可以流出多少立方的水。
二、SIMD
SIMD单指令多数据流(SingleInstruction Multiple Data,SIMD)是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。在微处理器中,单指令流多数据流技术则是一个控制器控制多个平行的处理微元,譬如,NVIDIA的GPU,就采用的这种运算架构,在高频配合下,可以达到G 到T 级的FLOPs计算速度,吞吐率极高。
三、MAC(转载地址5:https://www.jianshu.com/p/ea5b99e609c5)
一般衡量CNN网络的理论运算时间,我们都是用FLOPS(浮点运算次数)来表示。但其实这个有不太符合实际情况的。首先在不同硬件平台上,convolution运算可能是存在优化的。例如一个做3 * 3的convolution操作运算时间不一定是1 *1的convolution操作的9倍。因为在CUDNN下是有CNN并行优化的,所以不能单单用FLOPS来衡量一个CNN的运算时间。此外FLOPS只是考虑到浮点的运算次数,但是还有其他因素影响CNN的实际运算时间,例如memory access cost —— MAC(内存访问损失)