前者相应的表示为决策树或判别树,后者则有决策表和产生式规则等。
分类的目的是分析输入数据。通过在训练集中的数据表现出来的特性。为每个类找到一种准确的描写叙述或者模型。
因此,使用交叉验证来评估模型是比較合理的。
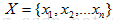 表示。分别描写叙述对n个属性A1,A2,A3,......,An样本的n个度量。
表示。分别描写叙述对n个属性A1,A2,A3,......,An样本的n个度量。

因此问题就转化为对P(X|Ci)的最大化。P(X|Ci)常被称为给定Ci时数据X的似然度,而使P(X|Ci)最大的如果Ci称为最大似然如果。
给定样本的类标号,假定属性值相互条件独立。即在属性间不存在依赖关系。
这样:

树的最顶层结点是根结点。一棵典型的决策树例如以下图所看到的。内部结点用矩形表示,而树叶节点用椭圆表示。为了对未知的样本分类,样本的属性值在决策树上測试。
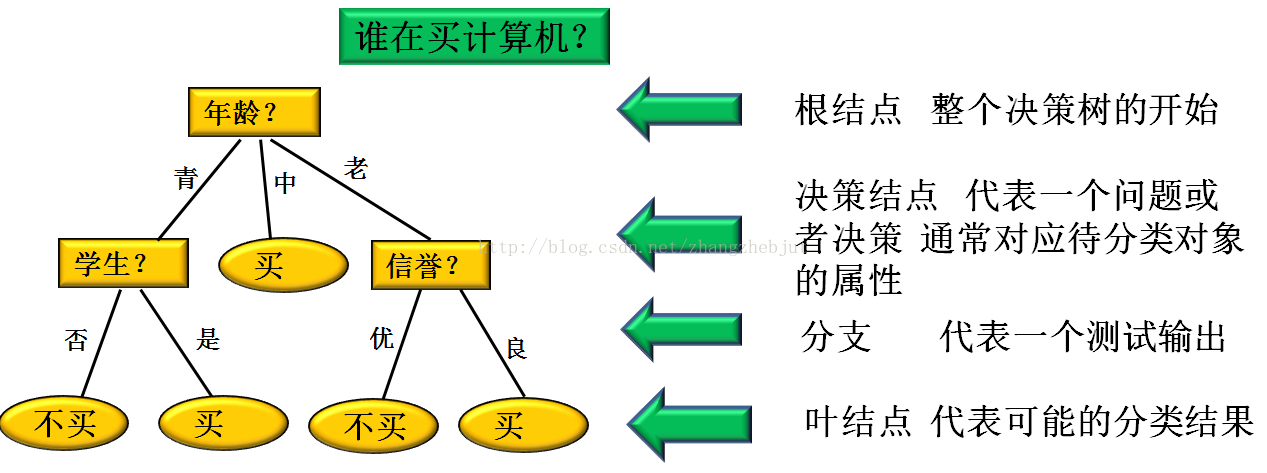
数据的叶子结点都是类别标记。
一个属性的熵越大。它蕴含的不确定信息越大。越有利于数据的分类。这样的信息理论方法使得对一个对象分类所需的期望測试数目达到最小,并尽量确保找到一棵简单的树来刻画相关的信息。



当中pi是随意样本属于Ci的概率,一般可用si/s来预计。
设属性A具有v个不同的值{a1,a2,...,av}。能够用属性A将S划分为v个子集{S1,S2,....Sv},其

 充
当第j个子集的权,而且等于字集(即A值为aj)中样本个数除以S中样本总数。
充
当第j个子集的权,而且等于字集(即A值为aj)中样本个数除以S中样本总数。
熵值越小,子集划分的纯度越高。说明选择属性A作为决策节点的效果 越好。
由期望信息和熵值能够得到相应的信息增益值。
对于在A上分支将获得的信息增益可

ID3依据信息增益,运用自顶向下的贪心策略建立决策树。
信息增益用于度量某个属性对样本集合分类的好坏程度。
因为採用了信息增益,ID3算法建立的决策树规模比較小。查询速度快。
然而整个策略并不是行得通。其实,当数据中有噪声或训练例子的数量太少以至于不能产生目标函数的有代表性採样时,这个策略便会遇到困难,导致过度拟合训练集。
这与那些基于单独的训练例子递增作出决定的方法不同。
使用全部例子的统计属性(比如:信息增益)的一个长处是大大减少了对个别训练例子错误的敏感性。因此,通过改动ID3算法的终止准则以接受不全然拟合训练数据的如果。是能够非常easy的扩展到处理含有噪声的训练数据。
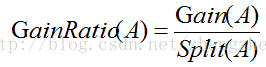
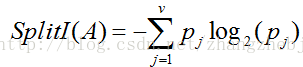
能够用属性A将S划分为v个子集{S1,S2,....Sv},其
2. 合并具有连续值的属性
ID3算法最初假定属性离散值,但在实际环境中,非常多属性值是连续的。C4.5算法可以处理具有连续的属性值。
3. 处理含有未知属性值的训练样本
C4.5处理的样本能够含有未知属性值,其处理方法是用最经常使用的值替代或者将最经常使用的值分在同一类中。
详细採用概率的方法。根据属性已知的值。对属性和每个值赋予一个概率。取得这些概率依赖于该属性已知的值。
4. 产生规则
一旦树被简历。就能够把树转换成if-then规则。
统计学中经常使用的预測方式是回归。数据挖掘中的分类和统计学中的回归方法是一对联系又有差别的概念。一般地,分类的输出是离散的类别值,而回归的输出则是连续数值。分类具有广泛的应用,比如垃圾邮件识别、信用卡系统的信用分级、图像的模式识别等。