性能度量
对学习器的泛化性能进行评估,不仅要有有效可行的实验估计方法,还要有衡量模型泛化能力的评价标准,这就是性能度量。
以下介绍分类任务中常用性能度量
错误率与精度
在上一篇文章中有提到错误率和精度,以下对其定义:
错误率:
E(f; D) = 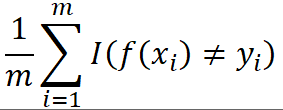
精度:
acc(f; D) = 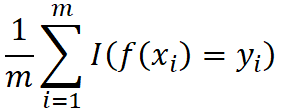 = 1 - E(f; D)
= 1 - E(f; D)
其中 I( . ) 当 . 为真时取 1, 为假时取 0 。
查准率,查全率与 F1
在有些任务中,错误率和精度并不能完全满足需求,例如在信息检索中,我们关心 “检索出的信息有多少比例是用户感兴趣的” 和 “用户感兴趣的信息有多少被检索出来了”。
对于二分问题,将预测结果进行以下划分:
真正例(TP),假正例(FP),真反例(TN),假反例(FN)
显然 TP + FP + TN + FN = 样例总数
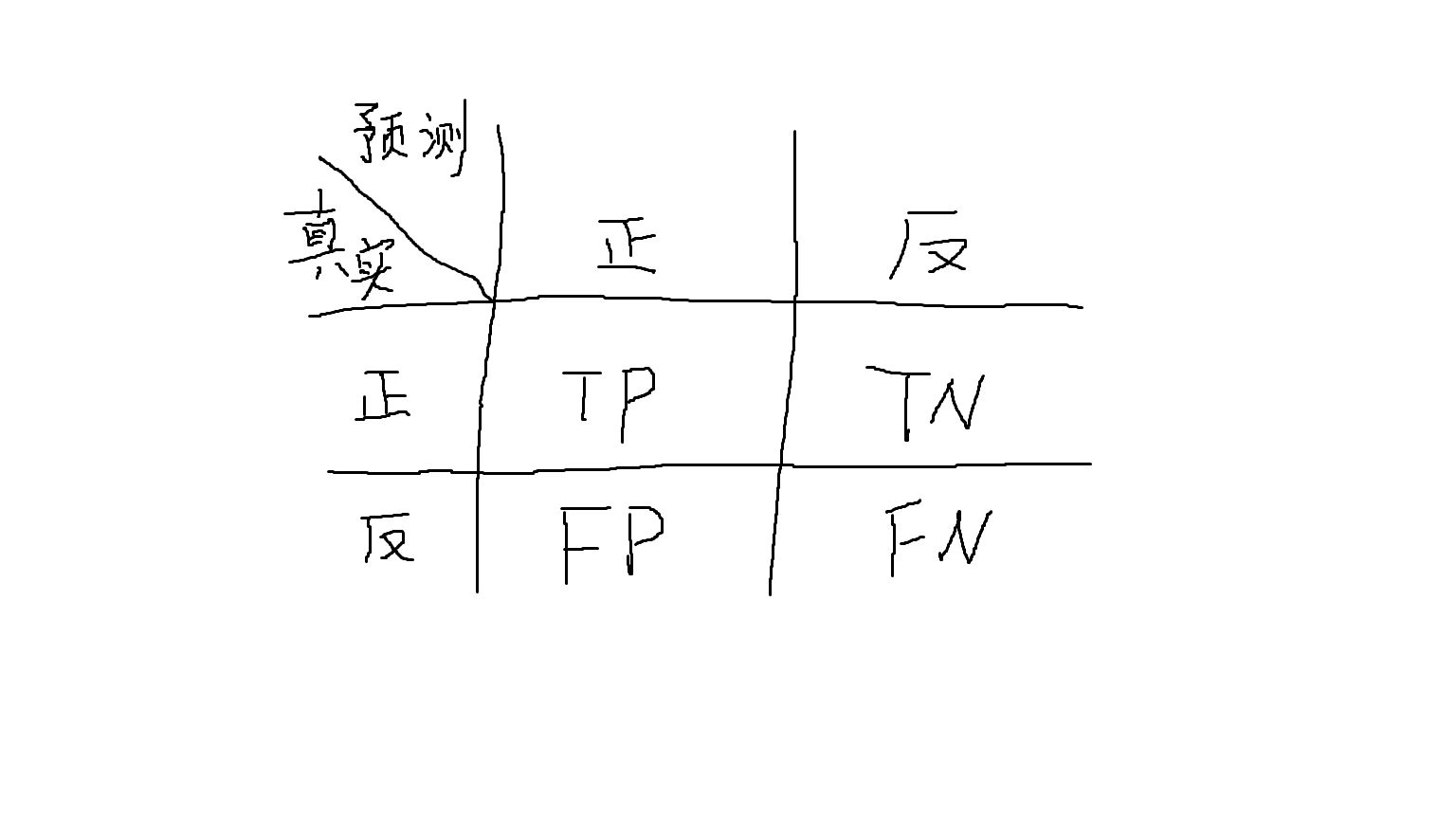
定义:
查准率 P = TP / (TP +FP)
查全率 R = TP / (TP + FN)
P 和 R 互为矛盾度量,即一个高时另一个偏低。
比如挑西瓜,想把所有好瓜挑出来时,就把所有瓜都标记为好瓜,想尽可能准确的挑出好瓜时,则要挑最有把握的瓜。
P-R曲线:
把最可能是正例的样本排前面,把最不可能是正例的样本排后面,按此顺序把样本作为正例逐个预测,则可以计算出当前的查全率和查准率。再以查全率为和坐标,查准率为纵坐标,可以绘制查准率-查全率曲线,简称 P-R曲线。

如上图,A 完全包住了 C,则学习器 A 优于学习器 C, 而对于A , B 则难以判断,通过引入平衡点(BEP)来度量,它是 P = R 时的取值,BEP高的一般认为较优,所以 A 优于 B。
但是BEP还是过于简化了,接下来引入 F1度量。
F1
定义:
F1 = 2 * P * R / (P + R) = 2 * TP / (样例总数 + TP - TN)
有时候我们对 查全率/查准率 有不同的偏好。
例如追查逃犯我们希望尽可能少漏掉逃犯,而推荐商品时我们希望尽可能精准的进行推荐。
于是引出了 F1 的一般形式:Fβ
定义:
Fβ = (1 + β ^ 2) * P * R / (β ^ 2 * P) + R
其中 β > 0
当 β > 1 时,查全率影响更大, β < 1 时,查准率影响更大,当 β = 1 时,则为 F1。
宏F1和微F1
很多时候我们有很多个混淆矩阵,比如进行了多次训练测试,这是我们希望可以综合考察查准率和查全率。
一种做法是计算每个混淆矩阵的 P 和 R,然后取均值,这样就得到了 宏F1,(macro-F1)
定义:
macro-P = 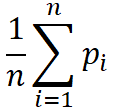
macro-R = 
macro-F1 = 2 * macro-P * macro-R / (macro-P + macro-R)
还可以现将各混淆元素平均再计算,可得出 微F1(micro-F1)
定义下次补上
ROC 与 AUC
待续。