广西人才网实习信息爬取与数据库存储实战 https://www.gxrc.com/
大家好,我是W
项目介绍:本项目为CrawlSpider结合MySQL、MongoDB爬取求职网站信息的项目,目标是将网站指定分类下的招聘信息(包括:职位名称、公司名称、薪资、工作地点、更新时间、招聘人数、学历要求、经验要求、公司性质、职位要求、公司介绍、公司规模、联系人、联系电话、email、联系地址)。本项目将涉及CrawlSpider模板、项目分析、xpath数据提取、爬虫中间件设置UA和IP、MySQL数据库操作、MongoDB数据库操作。
网站分析
- 首先进入广西人才网首页**https://www.gxrc.com/,点击左侧菜单栏中的计算机/互联网/通信/电子 下的计算机软件开发类**分类查看URL。可以看到URL为https://s.gxrc.com/sJob?schType=1&expend=1&PosType=5480。经过删删改改可以推测出实际有用的URL为https://s.gxrc.com/sJob?PosType=5480(代表gxrc网下的计算机软件开发类[type=5480])
- 接下来对搜索条件进行筛选,本次项目需要筛选的条件为{工作性质:毕业生职位,工作经验:1年内},经过选择并观察URL知道URL应为:https://s.gxrc.com/sJob?posType=5480&workProperty=-1&workAge=1&page=1&pageSize=20。并且page为页码,pagesize为每页显示条数。
- 第三步打开F12,查看翻页结果。可以明显看到翻页的规则就是通过改变上面URL的page和pagesize得到的,所以在构建Rule的时候很容易编写。
创建CrawlSpider项目并编写Rule规则
-
创建CrawlSpider项目在https://blog.csdn.net/Alian_W/article/details/104102600
有,我就不多赘述。 -
编写Rule规则,通过F12查看可以知道每个页面的详情页规则是
https://www.gxrc.com/jobDetail/(.+) -
因为招聘信息很多,为了不让爬虫跑出去爬出不符合条件的信息所以修改
allowed_domains = ['https://s.gxrc.com/sJob?PosType=5480']这是如果有细心地同学去试着打印response.text会发现爆出了DEBUG: Filtered offsite request to xxx错误,显然我们的allowed_domains写错了。仔细观察url会发现我们允许的url为https://s.gxrc.com/,但是详情页没有s.,这就很尴尬。所以必须修改URL为allowed_domains = ['gxrc.com'] -
start_urls 改为
start_urls = ['https://s.gxrc.com/sJob?posType=5480&workProperty=-1&workAge=1&page=1&pageSize=20'] -
rules 定义
rules = ( # CrawlSpider扫描到的所有详情页都会进入请求队列 同时设置callback为parse_item,对其进行数据提取 ,follow为False,详情页下有其他职位并不符合我们的搜索规则 Rule(LinkExtractor(allow=r'https://www.gxrc.com/jobDetail/(.+)'), callback='parse_item', follow=True), # 编写翻页规则 posType为搜索大类 workProperty为工作性质 workAge为工作年限 pageSize=(\d){1,2}表示1~2位数字均可 page=(\d){1,3} # follow=True 即遇见导航栏还存在下一页就翻页 没有callback表示不需要对列表页处理,只需要请求回来交由core分析提取上一个规则的详情页即可 Rule(LinkExtractor( allow=r'https://s.gxrc.com/sJob?posType=5480&workProperty=-1&workAge=1&pageSize=(\d){1,2}&page=(\d){1,3}'), follow=True), )
Xpath信息提取
-
试着打印一下请求出来的页面内容
def parse_item(self, response): url = response.url content = response.text print(url, content)
在成功打印出来之后我们就可以对页面进行xpath提取了。
2. 先到Items.py定义字段
class GXRCItem(scrapy.Item):
job_name = scrapy.Field() #
campany_name = scrapy.Field() #
campany_size = scrapy.Field() #
salary = scrapy.Field() #
work_place = scrapy.Field() #
update_time = scrapy.Field() #
hire_num = scrapy.Field() #
edu_background = scrapy.Field() #
experience_requirement = scrapy.Field() #
campany_nature = scrapy.Field() #
job_requirement = scrapy.Field() #
campany_intro = scrapy.Field() #
linkman = scrapy.Field() #
phone = scrapy.Field()
email = scrapy.Field() #
location = scrapy.Field() #
-
xpath提取数据(基本功不详细介绍了,也可以用css选择器,re表达式)
def parse_item(self, response): job_name = response.xpath("//*[@class='header']//div[@class='pos-wrap clearfix']/h1/text()").get() salary = response.xpath( "//*[@class='header']//div[@class='pos-wrap clearfix']/div[@class='salary']/text()").get().strip() detail = response.xpath("//*[@class='base-info fl']/p/text()").extract() # 返回一个list 通过下标选择 edu_background = detail[1] experience_requirement = detail[2] hire_num = detail[3] campany_name = response.xpath("//div[@class='ent-name']/a/text()").get() entDetails = response.xpath("//div[@id='entDetails']/p/span/text()").extract() work_place = entDetails[3] campany_size = entDetails[1] campany_nature = entDetails[0] update_time = response.xpath("//span[@class='w3']/label/text()").get().strip() job_requirement = response.xpath("//pre[@id='examineSensitiveWordsContent']/text()").get() campany_intro = response.xpath("//pre[@id='examineSensitiveWordsContent2']/text()").get() contact_info = response.xpath("//div[@class='contact-info-con con']/p/label") linkman = contact_info[0].xpath("./text()").get() email = contact_info[2].xpath("./text()").get() # 没有回自动返回None location = contact_info[3].xpath("./text()").get() # print(job_name, campany_name, campany_intro, salary, job_requirement) yield GXRCItem(job_name=job_name, campany_name=campany_name, campany_size=campany_size, salary=salary, work_place=work_place, update_time=update_time, hire_num=hire_num, edu_background=edu_background, experience_requirement=experience_requirement, campany_nature=campany_nature, job_requirement=job_requirement, campany_intro=campany_intro, linkman=linkman, phone=None, email=email, location=location)
对spider里yield出来的item在pipeline中进行处理
MySQL存储
-
在settings文件中设置mysql数据库的参数
# mysql MYSQL_HOST = 'localhost' MYSQL_PORT = 3306 MYSQL_DB = 'python_scrapy' MYSQL_TABLE = 'gxrc_tech' MYSQL_USER = 'root' MYSQL_PASSWORD = 'root' MYSQL_CHARSET = 'utf-8' -
在pipeline中编辑MysqlPipeline
class MysqlPipeline(object): def __init__(self): self.connect = pymysql.connect(host=settings.MYSQL_HOST, port=settings.MYSQL_PORT, db=settings.MYSQL_DB, user=settings.MYSQL_USER, password=settings.MYSQL_PASSWORD) self.cursor = self.connect.cursor() def process_item(self, item, spider): print(item['job_name'], item['campany_name'], item['campany_size'], item['salary'], item['work_place'], item['update_time'], item['hire_num'], item['edu_background'], item['experience_requirement'], item['campany_nature'], item['job_requirement'], item['campany_intro'], item['linkman'], item['phone'], item['email'], item['location']) sql = "insert into " + settings.MYSQL_TABLE + \ "(job_name,campany_name,campany_size,salary,work_place,update_time,hire_num,edu_background,experience_requirement,campany_nature,job_requirement,campany_intro,linkman,phone,email,location) " \ "values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)" try: self.cursor.execute(sql, ( item['job_name'], item['campany_name'], item['campany_size'], item['salary'], item['work_place'], item['update_time'], item['hire_num'], item['edu_background'], item['experience_requirement'], item['campany_nature'], item['job_requirement'], item['campany_intro'], item['linkman'], item['phone'], item['email'], item['location'])) self.connect.commit() except Exception as e: print(e) return item其中涉及python对mysql的操作,不了解的同学可以参考https://www.cnblogs.com/hanfanfan/p/10398244.html
MongoDB存储
-
在settings文件中设置mongodb数据库的参数
# mongodb MONGO_URI = 'mongodb://localhost:27017' MONGO_DB = 'python_scrapy' -
在pipeline中编辑MongoDBPipeline
class MongoDBPipeline(object): def __init__(self, uri, db): self.mongo_uri = uri self.mongo_db = db self.mongo_collection = 'gxrc_tech' @classmethod def from_crawler(cls, crawler): return cls(uri=crawler.settings.get('MONGO_URI'), db=crawler.settings.get('MONGO_DB')) def open_spider(self, spider): self.client = pymongo.MongoClient(self.mongo_uri) self.db = self.client[self.mongo_db] def close_spider(self, spider): self.client.close() def process_item(self, item, spider): data = { 'job_name': item['job_name'], 'campany_name': item['campany_name'], 'campany_size': item['campany_size'], 'salary': item['salary'], 'work_place': item['work_place'], 'update_time': item['update_time'], 'hire_num': item['hire_num'], 'edu_background': item['edu_background'], 'experience_requirement': item['experience_requirement'], 'campany_nature': item['campany_nature'], 'job_requirement': item['job_requirement'], 'campany_intro': item['campany_intro'], 'linkman': item['linkman'], 'phone': item['phone'], 'email': item['email'], 'location': item['location'], } table = self.db[self.mongo_collection] table.insert_one(data) return item其中涉及python对mongodb的操作,不了解的同学可以参考https://www.cnblogs.com/cbowen/archive/2019/10/28/11755480.html
最后在settings里配置两个pipeline
ITEM_PIPELINES = {
'scrapy_db_practice.pipelines.MysqlPipeline': 300,
'scrapy_db_practice.pipelines.MongoDBPipeline': 301,
}
注意:mysql不会自动建表,需要在本地数据库建好相应的表
除了id列为int,自增、job_requirement和campany_intro为text,其他都为varchar255 ,因为varchar是可调节类型所以不必担心空间占用问题
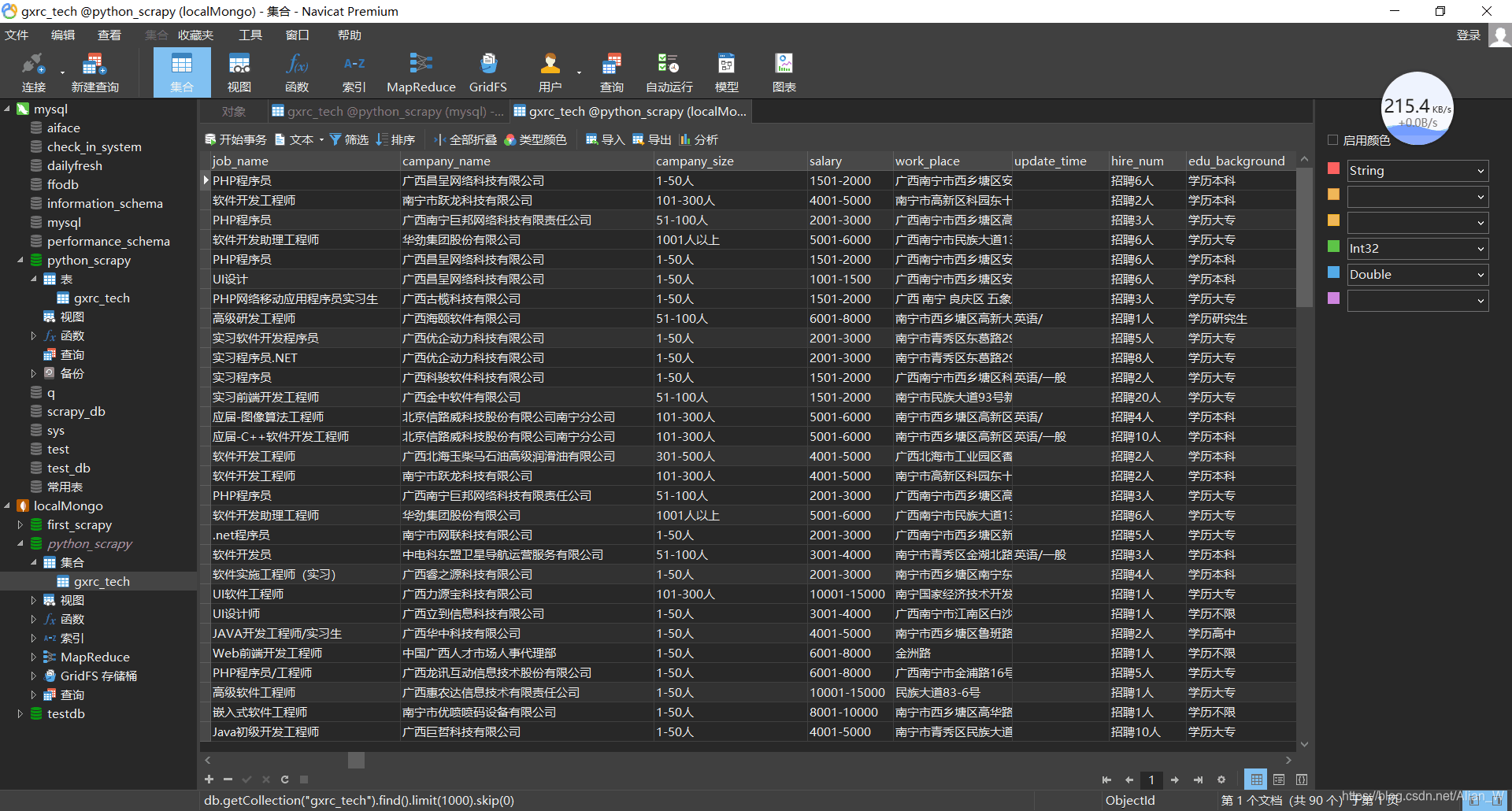
到此整个广西人才网的爬虫已经结束了,大家可以根据自己感兴趣的条件自行修改rules就可以爬取全站信息。
成果