实现了monodb和csv的文件写入

mongodb如下:
这里学历要求获取错了,取错列表下标了...,代码已经改正

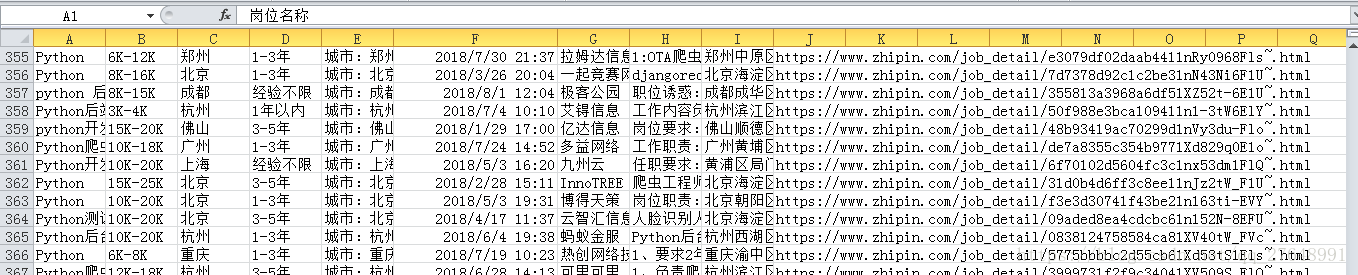
Excel如下:
这里学历要求获取错了,取错列表下标了...,代码已经改正
待解决问题:

由于过多的请求页面有时弹出验证码,代码现在只能通过手动输入解决,我这里设置了等待时间人工输入了验证码可继续写入。 最简单的方法就是可以通过更换ip去实现跳过验证码,但是这代码没有实现这功能--待完善
小白:希望大家多提点意见
import csv
import re
from time import sleep
from random import uniform
import pymongo
from lxml import etree
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
class BossSpider(object):
def __init__(self):
self.driver = webdriver.Chrome()
self.base_domain = 'https://www.zhipin.com'
self.client = pymongo.MongoClient('localhost', 27017) # 连接数据库连接
self.db = self.client.spider_demo # 创建/连接数据库
self.collection = self.db.spider_boss # 创建/连接集合
def parse_boss(self, url):
self.driver.get(url)
try:
WebDriverWait(self.driver, timeout=10).until(
EC.presence_of_element_located((By.XPATH, '//div[@class="page"]/a[last()]'))
)
except TimeoutError:
print('工作列表页提取失败,重新获取')
self.start(url)
next_page = self.driver.find_element(By.XPATH, '//div[@class="page"]/a[last()]') # 提取下一页
next_url = next_page.get_attribute('href')
text = self.driver.page_source # 页面提取
self.parse_job_list(text) # 解析页面工作url链接
if not next_url.startswith('http'): # 域名拼接
next_url = self.base_domain + next_url
if 'javascript' in next_url: # 是否最后一页
self.driver.quit() # 退出
else:
# sleep(uniform(2, 8))
self.parse_boss(next_url) # 继续递归执行
def parse_job_list(self, text):
html = etree.HTML(text)
job_urls = html.xpath('//div[@class="info-primary"]/h3[@class="name"]/a/@href')
for job_url in job_urls:
url = job_url
if not job_url.startswith('http'): # 域名拼接
url = self.base_domain + job_url
self.parse_job(url)
def parse_job(self, url):
self.driver.execute_script(r'window.open("{}")'.format(url))
self.driver.switch_to.window(self.driver.window_handles[1])
try:
WebDriverWait(self.driver, timeout=10,).until(
EC.presence_of_element_located((By.XPATH, '//div[@class="name"]/h1'))
)
text = self.driver.page_source
self.fetch_data(text) # 解析页面
sleep(uniform(3, 8)) # 模拟浏览时间
self.driver.close() # 关闭新窗口
self.driver.switch_to.window(self.driver.window_handles[0]) # 切换第一个页面
except:
sleep(uniform(30, 60)) # 等待输入验证码时间
print('详情页提取失败... 重新提取')
self.driver.close() # 关闭新窗口
self.driver.switch_to.window(self.driver.window_handles[0]) # 切换第一个页面
self.parse_job_list(url)
def fetch_data(self, text):
html = etree.HTML(text)
job_name = html.xpath('//div[@class="name"]/h1/text()')[0] # 岗位名称
salary = html.xpath('//div[@class="name"]/span/text()')[0] # 薪资
basic_data = html.xpath('//div[@class="info-primary"]/p[1]/text()')[:3] # 基础数据
city = basic_data[0].replace('城市:', '').strip()
job_years = basic_data[1].replace('经验:', '').strip()
edu = basic_data[2].replace('学历:', '').strip()
release_time = html.xpath('//div[@class="job-author"]/span/text()')[0] # 发布时间
release_time = release_time.replace('发布于', '').strip()
company_name = html.xpath('//div[@class="info-company"]/h3//text()')[0] # 公司名称
describe = html.xpath('//div[@class="job-sec"]/div[@class="text"]/text()') # 职业描述
des = ''.join(describe).strip() # 转换字符串
des = re.sub('[\s ]', '', des) # 格式转换
address = html.xpath('//div[@class="location-address"]/text()')[0] # 地址
print(job_name)
print(salary)
print(city, job_years, edu)
print(release_time)
print(company_name)
print(des)
print(address)
print('='*50)
data = {'job_name': job_name, 'salary': salary, 'city': city,
'job_years': job_years, 'edu': edu,
'release_time': release_time, 'company_name': company_name,
'des': des, 'address': address, 'url': self.driver.current_url}
self.save_data_csv(data)
self.save_mongodb(data)
def save_title_csv(self):
data_title = ['岗位名称', '薪资', '城市', '工作年限',
'教育', '发布时间', '公司名称', '岗位信息',
'地址', '网页地址']
with open('boss.csv', 'a', encoding='utf-8-sig', newline='') as f:
writer = csv.DictWriter(f, data_title)
writer.writeheader()
def save_data_csv(self, data):
with open('boss.csv', 'a', encoding='utf-8-sig', newline='') as f:
writer = csv.writer(f)
writer.writerow([i for i in data.values()])
print('='*20+'csv写入成功'+'='*20)
def save_mongodb(self, data):
self.collection.insert(data)
print('='*20+'mongodb写入成功'+'='*20+'\n')
def start(self, url):
self.save_title_csv()
self.parse_boss(url)
print()
if __name__ == '__main__':
spider = BossSpider()
url = 'https://www.zhipin.com/job_detail/?query=python&scity=100010000&industry=&position='
spider.start(url)
扫描二维码关注公众号,回复:
2667590 查看本文章
