本专栏是以杨秀璋老师爬虫著作《Python网络数据爬取及分析「从入门到精通」》为主线、个人学习理解为主要内容,以学习笔记形式编写的。
本专栏不光是自己的一个学习分享,也希望能给您普及一些关于爬虫的相关知识以及提供一些微不足道的爬虫思路。
专栏地址:Python网络数据爬取及分析「从入门到精通」
更多爬虫实例详见专栏:Python爬虫牛刀小试

前文回顾:
「Python爬虫系列讲解」一、网络数据爬取概述
「Python爬虫系列讲解」二、Python知识初学
「Python爬虫系列讲解」三、正则表达式爬虫之牛刀小试
「Python爬虫系列讲解」四、BeautifulSoup 技术
「Python爬虫系列讲解」五、用 BeautifulSoup 爬取电影信息
「Python爬虫系列讲解」六、Python 数据库知识
目录
紧接前面所讲,本文主要讲述一个基于数据库存储的 BeautifulSoup 爬虫,用于爬取网页某网站的招聘信息,对数据进行增删改查等各种操作,同时为数据分析提供强大的技术保障,从而可以更加灵活地为用户提供所需数据。
1 知识图谱和招聘网站
随着“大数据”和“互联网+”时代的到来,各种数量庞大、种类繁多的信息呈爆炸式增长,而且此类信息实时性强、结构化程度差,同时具有复杂的关联性。因此,如何从海量数据中快速精确地寻找用户所需的信息,就变得尤为困难。在此背景下,通过自动化和智能化的搜索技术来帮助人们从互联网中获取所需的信息,就变得尤为重要,知识图谱(Knowledge Graph,KG)应运而生,它是一种通过理解用户的查询意图,返回令用户满意的搜索结果而提出的新型网络搜索引擎。
目前广泛使用的搜索引擎包括谷歌,百度和搜狗等,此类引擎的核心搜索流程如下:
- 首先,用户向搜索引擎中输入查询词;
- 其次搜索引擎在后台计算系统中检索与查询词相关的网页,通过内容相似性比较和链接分析,对检索的网页进行排序;
- 最后,依次返回排序后的相关结果。
但是,由于信息检索过程中没有对查询词和返回网页进行理解,也没有对网页内容进行深层次的分析和相关网页的关系挖掘,所以搜索准确性存在明显的缺陷。
现在为了提升搜索引擎的准确性和理解用户查询的真实意图,企业界提出了新一代搜索引擎或知识计算引擎,即知识图谱。知识图谱旨在从多个来源不同的网站、在线百科和知识库中获取描述真实世界的各种实体、概念、属性和属性值,并构建实体之间的关系以及融合属性和属性值,采用图的形式存储这些实体和关系信息。当用户查询相关信息时,知识图谱可以提供更加准确的搜索结果,并真正理解用户的查询需求,对智能搜索邮政重要的意义。
知识图谱构建过程中,需要从互联网中爬取海量的数据,包括百科数据、万维网广义搜索数据、面向主题的网站定向搜索数据等。比如,当我们需要构建一个招聘就业相关的知识图谱时,我们就需要爬取相常见的招聘网站,例如智联招聘、大街网、前程无忧等等。

接下来将介绍如何爬取赶集网网站发布的招聘信息并存处置本地 MySQL 数据库中。
2 用 BeautifulSoup 爬取招聘信息
Python 调用 BeautifulSoup 扩展库爬取赶集网网站的核心步骤如下:
- 分析网页超链接的搜索规则,并探索分页查找的跳转方法;
- 分析网页 DOM 树结构,定位并分析所需信息的 HTML 源码;
- 利用 Navicat for MySQL 工具创建智联招聘网站对应的数据库和表;
- Python 调用 BeautifulSoup 爬取数据并操作 MySQL 数据库将数据存储至本地。
2.1 分析网页超链接及跳转处理
招聘网站中的 “职位搜索” 页面中包含一系列可供选择的选项,如 “类别”、“区域”、“福利”、“月薪” 等等。

依次选择第 1 页数据:“http://bj.ganji.com/zpbiaoqian/p6o1/”、
第 2 页数据:“http://bj.ganji.com/zpbiaoqian/p6o2/”、
...
我们可以推出第 n 页数据:“http://bj.ganji.com/zpbiaoqian/p6on/”。
由此我们发现,发生变化的仅为最后“/” 前一个数字变化。
在分析 URL 链接时,常常会遇到一些特殊符号,下面给出 URL 中常见的特殊符号含义:
| 特殊符号 | URL 中的含义 | URL 编码 | ASCII 码 |
| 空格(space) | URL 中空格连接参数,也可用“+”连接 | %20 | 32 |
| # | 表示书签 | %23 | 35 |
| % | 指定特殊字符 | %25 | 37 |
| & | URL 中参数间的分隔符 | %26 | 38 |
| ' | URL 中的单引号 | %27 | 39 |
| + | URL 中 “+” 标识空格 | %2B | 43 |
| - | URL 中的减号 | %2D | 45 |
| / | 用于分隔目录和子目录 | %2F | 47 |
| ; | URL 中多个参数传递的分隔符 | %3B | 91 |
| = | URL 中指定参数的值 | %3D | 93 |
| ? | 分隔实际的超链接和参数 | %3F | 95 |
对于查询多页结果的跳转,是网站和系统开发中非常经典和常用的一种技术,跳转页面通常位于网页的底部。

那么网络爬虫是如何实现多页跳转的数据分析呢?这里提供 3 中方法供借鉴:
- 通过分析网页的超链接找到翻页跳转对应 URL 参数的规律,再使用 Python 拼接动态变化的 URL,对于不同的页面分别进行访问及数据爬取。文本采用的就是此方法,前文提到过,对于翻页跳转仅改变 URL 中的 “p” 值即可实现。
- 部分网页可以采用 Selenium 等自动定位技术,通过分析网页的 DOM 树结构,动态定位网页跳转的连接或按钮。比如调用 find_element_by_xpath() 函数定位网页跳转按钮,然后操作鼠标控件自动点击,从而跳转到对应页面。
- 如果网页采用 POST 方法进行访问,没有在 URL 中指明跳转的参数,则需要分析网页跳转链接对应的源码。对跳转页面进行审查元素反馈的结果如下图所示,然后通过爬取跳转链接后再通过爬虫访问对应的 URL 及爬取数据。

例如,利用 BeautifulSoup 技术爬取智联招聘信息就是采用分析网页超链接 URL 的方法实现的,核心代码如下:
i = 1
while i <= n:
url = 'http://bj.ganji.com/zpbiaoqian/p6o' + str(i) + '/'
crawl(url)首先通过字符串拼接访问不同页码的 URL,然后调用 crawl(url) 函数循环爬取。其中,crawl() 函数用于爬取 url 中的指定内容。
2.2 DOM 树节点分析及网页爬取
接下来需要对智联招聘网站进行具体的 DOM 树节点分析,并详细讲述利用 BeautifulSoup 技术定位节点及爬取的方法。

此时需要定位多个 <div> 标签。调用 find_all() 函数获取 class 属性为 “newlist” 的节点,然后通过 for 循环以此获取 table 表格,核心代码如下:
for tag in soup.find_all(attrs={"class": "con-list-zcon new-dl"})定位到每块招聘内容后,再爬取具体的内容,如张志伟名称、公司名称、职位月薪、工作地点、发布日期等,并将这些信息赋给变量,存储至本地 MySQL 数据库中。
其中,获取职位名称和薪资信息的代码如下:
zhiwei = tag.find(attrs={"class": "list-ga gj_tongji js-float"}).get_text()
xinxi = tag.find(attrs={"class": "s-butt s-bb1"}).get_text()在定义网络爬虫时,通常需要将一些详情页面的超链接存储至本地,比如下图红框中的超链接。
 在 BeautifulSoup 技术中,可以通过 get('href') 函数获取超链接对应的 URL。
在 BeautifulSoup 技术中,可以通过 get('href') 函数获取超链接对应的 URL。
url_info = tag.find_all(attrs={"class": "list-ga gj_tongji js-float"})
for u in url_info:
chaolianjie = u.get('href')
print(chaolianjie)至此,如何调用 BeautifulSoup 技术分析智联招聘网站的信息、定位节点及爬取所需知识已经讲解完毕。
3 Navicat for MySQL 工具操作数据库
Navicat for MySQL 是一套管理和开发 MySQL 的理想解决方案,它支持单一程序,可直接连接到 MySQL 数据库。Navicat for MySQL 为数据库管理、开发和维护提供了直观而强大的图形界面,给 MySQL 新手以及专业人士提供了全面管理数据库的强大工具,以方便其操作数据库。
3.1 连接数据库
点击“连接”按钮,弹出“连接”对话框,在该对话框中输入相关信息,如主机名、端口等。如果是本地数据库,则在“主机”文本框中输入“localhost”,在“端口”文本框中输入“3306”,“用户名”和“密码”分别为本地 MySQL 数据库对应值,“用户名”默认为 root,“密码”默认为“123456”,连接名这里我连接的是上一篇文章创建的数据库“bookmanage”。
填写好后,单机“连接测试”,当本地连接创建成功之后,点击确定,就可以看到本地已经创建的数据库了。

具体而言,我们可以看到上一篇文章创建的两个表“books”和“students”。很显然,比上一篇文章介绍的 MySQL 更加方便。

3.2 创建数据库
利用 Navicat for MySQL 创建数据库有两种方法:
第一种是通过 SQL 语句创建数据库,执行具体代码如下:
create database test00第二种是右击鼠标,在弹出的快捷菜单中选择“新建数据库”:
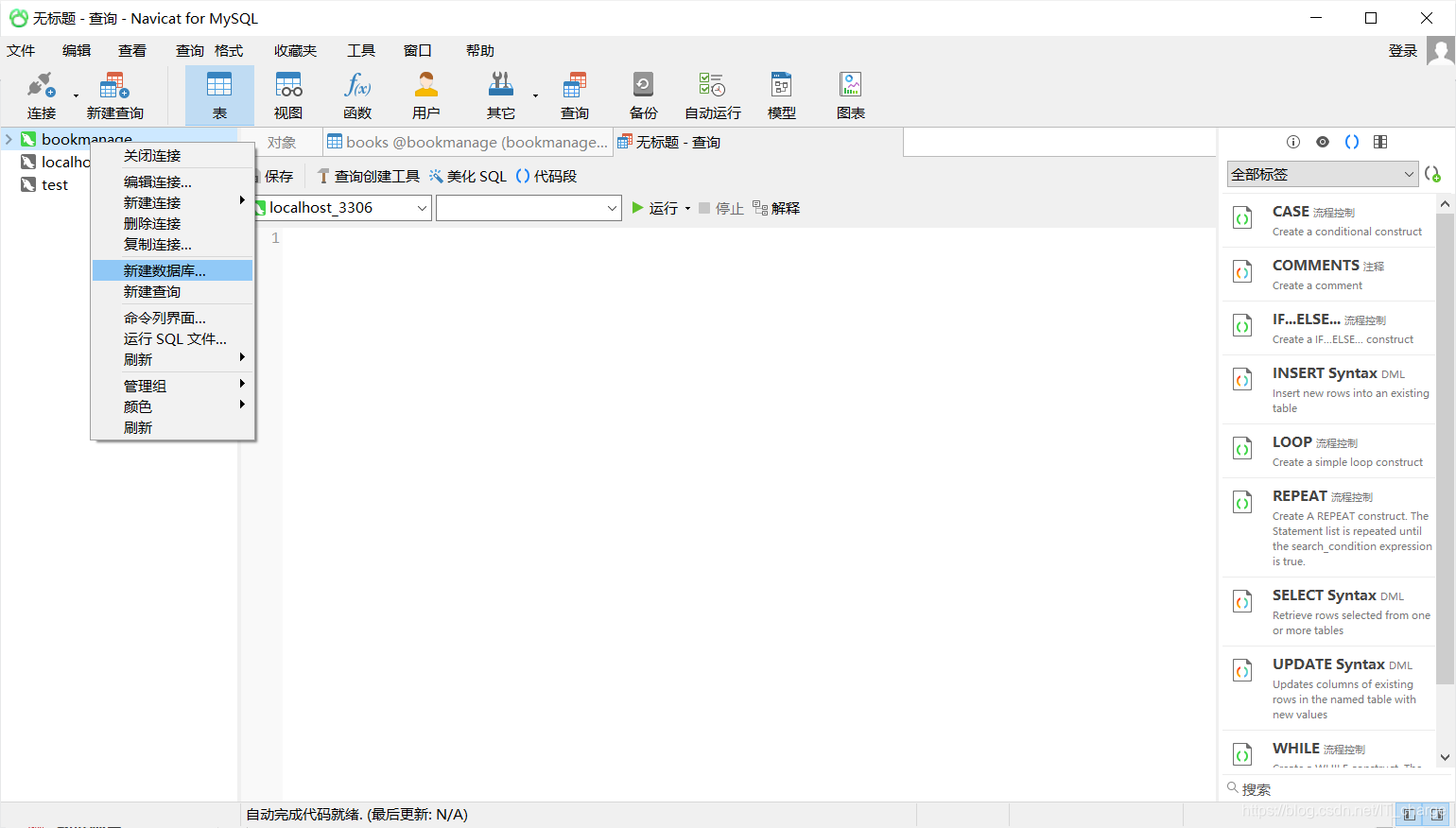
然后再弹出的 “新建数据库” 对话框中输入数据库名、字符集和排序规则,和第一种方法提到的一样,将数据库名设置为“test00”,将字符集设置为“utf8”,将排序规则设置为“utf8_unicode_ci”

单击确定,本地 MySQL数据库就创建成功了。
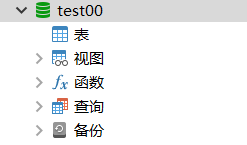
3.3 创建表
利用 Navicat for MySQL 创建表也有两种方法:
一种是单击任务栏中的新建表按钮进行创建、另一种是右击空白处在弹出的快捷菜单中选择“新建表”来创建。

假设新建表为 T_USER_INFO,单击“添加栏位”按钮向表中插入响应字段,插入的字段包括:ID(序号)、USERNAME(用户名)、PWD(密码)、DW_NAME(单位名称);同时还可以设置主键、非空属性、添加注释等。

设置完成之后单击“保存”按钮,并在“输入表名”文本框中输入“T_USER_INFO”,此时数据库的一张表就创建成功了。

当表创建好之后,单击打开表按钮可以查看当前表中所包含的数据。因为该表目前没有数据,所以显示为空。

当然,鼠标右击可以对表进行一系列的操作,感兴趣读者可进一步学习,这里就不再赘述了。

3.4 数据库增删改查操作
SQL 语句支持的常用命令包括:
- 数据库定义语言(DDL):create、alter、drop
- 数据库操纵语言(DML):insert、delete、update、select
- 数据控制语言(DCL):grant、revoke
- 事务控制语言(TCL):commit、savepoint、rollback
3.4.1 插入操作
单击“查询”按钮,再点击“新建按钮”,在弹出的对话框中进行 SQL 语句操作,完成之后单击“运行”按钮。
INSERT INTO T_USER_INFO
(ID,USERNAME,PWD,DW_NAME)
VALUES('1','zzr','123456','软件学院')

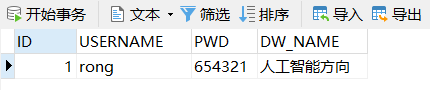
3.4.2 更新操作
将表 T_USER_INFO 中的 ID 值为 “1” 的数据更新
UPDATE T_USER_INFO SET USERNAME='rong',PWD='654321',DW_NAME='人工智能方向'
WHERE ID='1'
3.4.3 查询操作
查询表 T_USER_INFO 中 USERNAME 为 “rong” 的信息,代码如下:
SELECT * FROM T_USER_INFO WHERE USERNAME='rong';
3.4.4 删除操作
删除表 T_USER_INFO 中 ID 值为 “1” 的信息,代码如下:
DELETE FROM T_USER_INFO WHERE ID='1' 
4 MySQL 数据存储招聘信息
4.1 MySQL 操作数据库
首先需要创建表,SQL 语句代码如下:
CREATE TABLE `PAQU_ZHAOPINXINXI`(
`ID` int(11) NOT NULL AUTO_INCREMENT COMMENT '序号',
`zwmc` varchar(100) COLLATE utf8_bin DEFAULT NULL COMMENT '职位名称',
`xzdy` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '薪资待遇',
`gzdd` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '工作地点',
`gzjy` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '工作经验',
`zdxl` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '最低学历',
`zprs` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '招聘人数',
PRIMARY KEY(`ID`)
)ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;

4.2 代码实现
import re
import requests
import MySQLdb
from bs4 import BeautifulSoup
# 存储数据库
# 参数:'职位名称', '薪资待遇', '工作地点', '工作经验', '最低学历', '招聘人数'等
def DatabaseInfo(zwmc, xzdy, gzdd, gzjy, zdxl, zprs):
try:
conn = MySQLdb.connect(host = 'localhost', user='root', passwd='123456', port=3306, db='test00')
cur = conn.cursor() # 数据库游标
# 设置编码方式
conn.set_character_set('utf8')
cur.execute('SET NAMES utf8;')
cur.execute('SET CHARACTER SET utf8;')
cur.execute('SET character_set_connection=utf8;')
# SQL 语句
sql = '''
insert into paqu_zhaopinxinxi(zwmc, xzdy, gzdd, gzjy, zdxl, zprs)values(%s, %s, %s, %s, %s, %s)
'''
cur.execute(sql, (zwmc, xzdy, gzdd, gzjy, zdxl, zprs))
print('数据库插入成功')
except MySQLdb.Error as e:
print('Mysql Error %d: %s' % (e.args[0], e.args[1]))
finally:
cur.close()
conn.commit()
conn.close()
# 爬虫函数
def crawl(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
html = requests.get(url, headers=headers).text
# lxml:html解析库(把HTML代码转化成Python对象)
soup = BeautifulSoup(html, 'lxml')
print('爬取信息如下:')
i = 0
for tag in soup.find_all(attrs={"class": "con-list-zcon new-dl"}):
i = i + 1
zwmc = tag.find(attrs={"class": "list-ga gj_tongji js-float"}).get_text()
zwmc = zwmc.replace('\n', '')
print(zwmc)
# 其他信息
xinxi = tag.find(attrs={"class": "s-butt s-bb1"}).get_text()
print(xinxi)
xzdy = re.findall('薪资待遇:(.*?)元', xinxi)
gzdd = re.findall('工作地点:(.*?)\n', xinxi)
gzjy = re.findall('工作经验:(.*?)\n', xinxi)
zdxl = re.findall('最低学历:(.*?)\n', xinxi)
zprs = re.findall('招聘人数:(.*?)人', xinxi)
gzdd = gzdd[0]
gzjy = gzjy[0]
zdxl = zdxl[0]
# 写入 MySQL 数据库
print('写入数据库操作 ')
DatabaseInfo(zwmc, xzdy, gzdd, gzjy, zdxl, zprs)
else:
print('爬取职位总数:', i)
# 主函数
if __name__ == '__main__':
# 翻页执行 crawl(url) 爬虫
i = 1
while i <= 10:
print('页码:', i)
url = 'http://bj.ganji.com/zpbiaoqian/p6o{}/'.format(i)
crawl(url)
i = i + 1

至此,一个完整的使用 BeautifulSoup 技术爬取招聘网站信息并存储至本地 MySQL 数据库的实例已经讲完。通过数据库,用户可以对数据进行增删改查等各项操作,非常适合于海量数据爬取和数据分析操作。
5 本文小结
前几期文章分别讲述了 BeautifulSoup 技术和 Python 操作数据库,本文通过一个利用BeautifulSoup 技术爬取招聘信息的实例贯穿了所有知识点,将爬取的内容存储至本地 MySQL 数据库。通过这几期文章希望能给您普及一些关于爬虫的相关知识以及提供一些微不足道的爬虫思路。
欢迎留言,一起学习交流~
感谢阅读