前文回顾:
最大似然估计
-
设总体分布为
f(x,θ),X1 , X2…Xn为该总体采样得到的样本。因为X1 , X2…Xn独立同分布,于是,它们的联合密度函数为:
L(x1,x2,⋅⋅⋅⋅,xn;θ1,θ2,⋅⋅⋅,θk)=i=1∏nf(xi;θ1,θ2,⋅⋅⋅,θk)
-
这里,
θ被看做固定但未知的参数;反过来,因为样本已经存在,可以看成
X1,X2⋅⋅⋅Xn是固定的,
L(x,θ)是关于
θ的函数,即似然函数。
-
求参数
θ的值,是的似然函数取最大值,这种方法就是最大似然估计。
最大似然估计的具体时间操作
求导求驻点
- 在实践中,由于求导数的需要,往往将似然函数取对数,得到对数似然函数;若对数似然函数可导,可通过求导的方式,解下列方程组,得到驻点,然后分析该驻点是极大值点
logL(θ1,θ2,⋅⋅⋅θk)=i=1∑nlogf(xi;θ1,θ2,⋅⋅⋅,θk)
∂θ∂L(θ)=0,i=1,2,⋅⋅⋅k
P最大的时候θ的取值
最大似然估计例子
- 10次抛硬币的结果是:正正反正正正反反正正
- 假设p是每次抛硬币结果为正的概率。则:
P=pp(1−p)ppp(1−p)(1−p)pp
=p7(1−p)3
最优解(使函数取最大值)是:p=0.7
二项分布的最大似然估计
- 投硬币实验中,进行N次独立实验,n次朝上,N-n次朝下。
- 假定朝上的概率为p,使用对数似然函数作为目标函数:
f(n∣p)=log(pn(1−p)N−n)⟶h(p)
∂p∂h(p)=pn−1−pN−n⟶0⇒p=Nn
正态分布的最大似然估计
- 若给定一组样本
X1,X2...Xn,一直它们来自于高斯分布
N(μ,σ),试估计参数
μ,σ。
按照MLE的过程分析
- 高斯分布的概率密度函数:
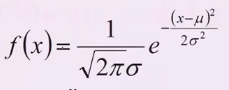
- 将
Xi的样本值
xi带入,得到:
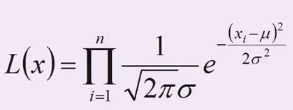
化简对数似然函数
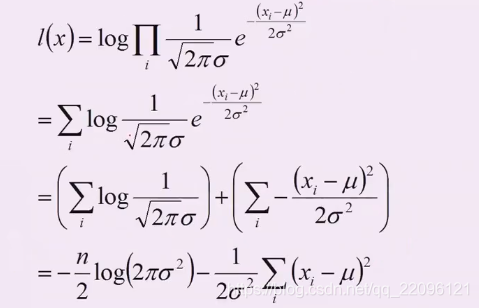
参数估计的结论
- 目标函数
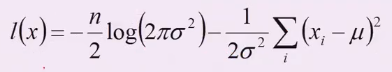
- 将目标函数对参数
μ,σ分别求偏导,容易得到:
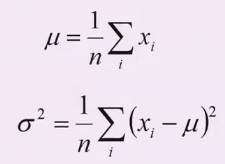
符合直观想象
- 上述结论和矩估计的结果是一致的,并且意义非常直观:样本的均值即高斯分布的期望,样本的伪方差即高斯分布的方差。
- 注:经典意义下的方差分布是n-1;在似然估计的方法中,求的方差是n
- 该结论将在期望最大化EM算法、高斯混合模型GMM中将继续使用。

数据清洗
赔率





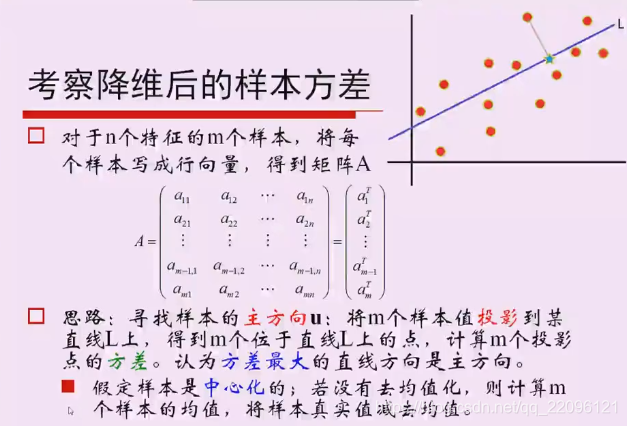


特征选择——降维
从N个特征中选择n个,并不是把所有特征放进去结果会更好。
分类
用线性分类器:线性分类也可以经过不同特征相乘形成非线性的分类器而只使用线性参数。注意在过高阶数下可能会出现过拟合。
